
こんにちは、8月は案件対応尽くめだったディーネットの山田です。
SAAを取得して早2年半経ちましたが、実際に構築者としてAWSの環境を触ってみると新しい発見や触ったことがない機能に触れることができてよかったです。
さて、そんな案件対応とは関係ありませんが、一度趣味程度でAmazon Rekognitionを使ってみたので、それをブログに書いてみようと思います。
目次
Amazon Rekognitionとは
機械学習の専門知識を必要とせずに、実績のある高度にスケーラブルな深層学習テクノロジーを使用して、アプリケーションに画像およびビデオ分析を簡単に追加できるようになります。
Amazon Rekognition を使用すると、画像と動画の物体、人物、テキスト、シーン、活動を特定し、不適切なコンテンツを検出できます。
Amazon Rekognition は、非常に正確な顔分析および顔検索機能も備えています。
これを使用して、さまざまなユーザー検証、人数のカウント、および公共安全のユースケースで顔を検出、分析、比較できます。
※AWSさんの概要ページより引用しました。
にある通り、個人の顔を特定することも出来ます。
使い方
- AWS CLIやAWS SDKでAmazon RekognitionのAPIを使用して利用します。
- 今回は、AWS SDK for Pythonであるboto3を使います。
- Pythonを動かすEC2にはIAMロールを割り当てています。
検証内容
- この技術ブログに貼り付けている私のプロフィール画像(顔写真)を元に、技術ブログのバナーや採用サイトにある私を含む画像からどこにいるか抽出してみる。
- Amazon Rekognitionからは、一致した座標がレスポンスとして返ってくるので、matplotlib.pyplotモジュールを使って編集してみます。
- 5MBまでであれば、S3を使わなくても利用可能なので、SDKに直接流し込みます。
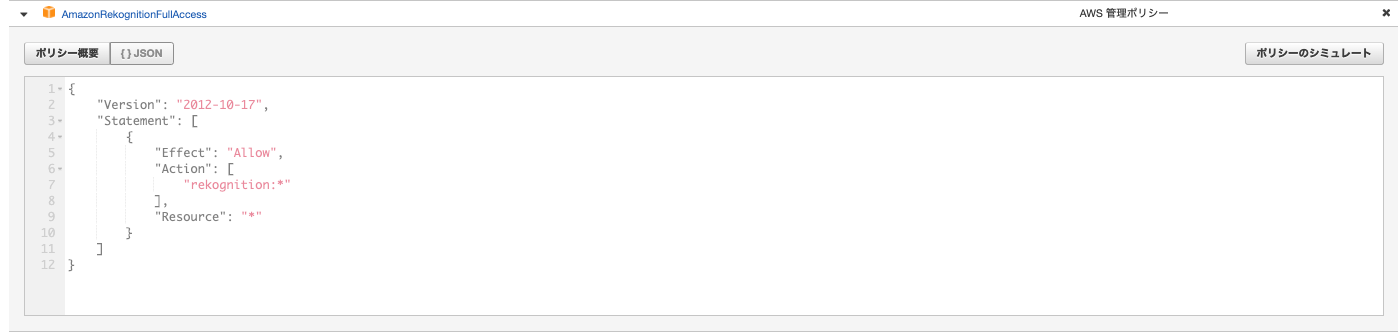
必要なIAMポリシー
- AmazonRekognitionFullAccess
用意したコード
import boto3
from matplotlib import pyplot as plt
from PIL import Image
# 画像ファイルを定義する
Source = './PICTURE/source.png' # 検索対象となる画像を定義
Target = './PICTURE/target.png' # 検索対象を探す画像を定義
Result = './PICTURE/SEARCH.png' # 検索対象が見つかればどこで見つかったかを表示する
# boto3でrekognitionを定義する
rekognition = boto3.client('rekognition', region_name='ap-northeast-1')
# 画像ファイルを読み込む(5MBまでであれば、S3を使わずに利用可能)
imageTarget = open(Target,'rb')
imageSource = open(Source,'rb')
# 検索対象をrekognitionで比較させる
response = rekognition.compare_faces(SimilarityThreshold=70, SourceImage={'Bytes': imageSource.read()}, TargetImage={'Bytes': imageTarget.read()})
# 読み込んだ画像は不要なのでクローズ
imageSource.close()
imageTarget.close()
# 検索対象を探す画像を編集のためにオープン
img = Image.open(Target)
img_width = img.size[0]
img_height = img.size[1]
# rekognitionで比較した結果、関連する部分が見つかったか判定
if len(response['FaceMatches'])==1:
# 検索対象を探す画像で見つかった位置を扱いやすいように変数に定義する
size_width = response['FaceMatches'][0]['Face']['BoundingBox']['Width']
size_height = response['FaceMatches'][0]['Face']['BoundingBox']['Height']
size_left = response['FaceMatches'][0]['Face']['BoundingBox']['Left']
size_top = response['FaceMatches'][0]['Face']['BoundingBox']['Top']
# 見つかった対象の類似度を表示する
print("関連する部分が見つかりました\n詳しくは、生成された画像を確認してください")
print("類似度:" + str(round(float(response['FaceMatches'][0]['Similarity']), 10)) + "%")
# 検索対象を探す画像のどの部分に見つかったか画像を修正
rect = plt.Rectangle(
(size_left * img_width, size_top * img_height),
size_width * img_width, size_height * img_height,
fill=False,
edgecolor='red')
plt.gca().add_patch(rect)
plt.imshow(img)
# 検索対象が見つかった画像をファイルに出力する
plt.savefig(Result, dpi=600)
else:
# 見つからなかったら見つからなかったことを伝える
print("関連する部分は見つかりませんでした")検証その1
比較画像

検索対象

当社リクルートサイトにある"先輩の声"の画像
検索結果

はい、そうですね。奥で手をあげているのが私ですね。
処理結果
関連する部分が見つかりました
詳しくは、生成された画像を確認してください
類似度:99.8819732666%検証その2
比較画像
検索対象

当社技術ブログにある"バナー"の画像
検索結果

はい、そうですね。右端に居るのが私ですね。
処理結果
関連する部分が見つかりました
詳しくは、生成された画像を確認してください
類似度:90.688369751%まとめ
- この検証を行うまでは、そこまで精度高くないだろう...と思っていましたが高精度で個人を特定できたのには、非常に驚きました。
- 今回は、画像から人物を特定しましたが、動画から特定できるならやってみたいですね。

プロフィール
テクニカルサポートは卒業して、フロントサイドでお客様環境の構築をさせていただいております。
たまに、テクニカルサポートでご対応させていただくことがあるかもしれませんが、その際はよろしくお願いいたします。
インフラ系のエンジニアですが、時々休日プログラマー(Python、PHP)をやっております。