
会社で蓄積されているデータをいい感じに分析できないかなー?と想い、「Amazon QuickSight」を使ってみたので、簡単に流れをまとめておこうと思います。
目次
ざっくりアーキテクチャ
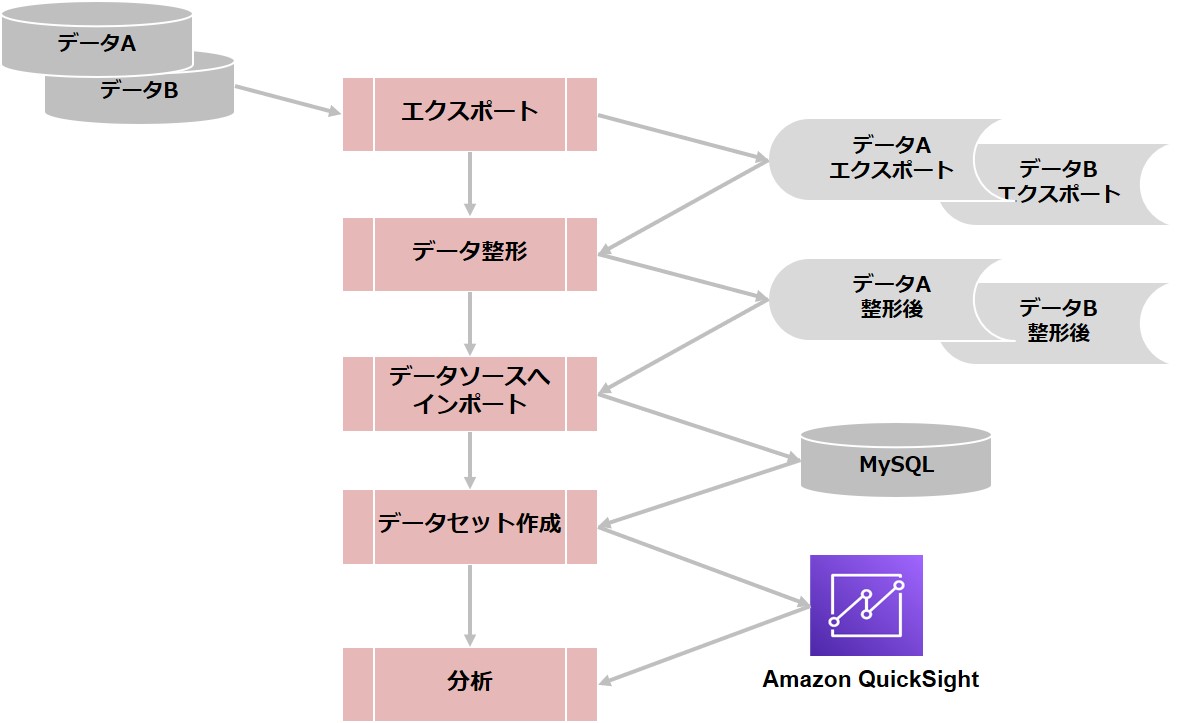
大まかなアーキテクチャは図のようになります。
データソースは2つあり、別々の形態で保存されています(ExcelとRDBで保存のようなイメージ)。特定のキー情報を相互に持っています。
時系列の変化を見たいので、エスポートデータに年月の情報を付加しつつ、必要に応じて不要なデータ削除などの整形を行います。
整形後のデータはMySQLへインポートすることで、2つのデータを結合して確認することができます。
MySQLのままではSQLが打てるエンジニアしか閲覧ができないので、Amazon QuickSightでグラフ化し共有しました。
BI初心者なので他に良い方法があるのかもしれませんが、一旦こんな感じでやってみました。
Amazon QuickSightを使うまでの流れ
実際の社内データを使うわけにはいかないので、今回は「郵便番号データ」を例に流れを説明していきます。アーキテクチャの図からデータBを抜いたイメージです。
見たいものを決める
何はともあれば見たい情報を決めましょう。
やりながら決めていくというのもいいとは思いますが、迷子になるのである程度は決めておいたほうがいいと思います。
今回は「都道府県別の市区町村数を見たい」ということで進めます。
元データの構造を理解する
日本郵便が提供している住所データを利用することにします。データは以下のページより、ダウンロードが可能です。「全国一括のデータファイル」を利用しました。
全国一括のデータファイル:https://www.post.japanpost.jp/zipcode/dl/roman-zip.html
説明ページによると次のようなCSVファイルになっているようです。
郵便番号(7桁)・・・・・ 半角数字
都道府県名・・・・・・・・漢字(コード順に掲載)(注1,2)
市区町村名・・・・・・・・漢字(コード順に掲載)(注1,2)
町域名 ・・・・・・・・漢字(五十音順に掲載)(注1,2)
都道府県名・・・・・・・・ヘボン式ローマ字 半角大文字(注3)
市区町村名・・・・・・・・ヘボン式ローマ字 半角大文字(注3)
町域名 ・・・・・・・・ヘボン式ローマ字 半角大文字(注3)
データを整形する
ダウンロードした住所データはきれいなデータなので何もする必要はありません。
実際の現場ではデータの整形が必要になることが多きがします。何気に一番面倒なフェーズでした。
実際にやった内容としては、
- 不要データの削除
- 揺らぎの修正
- 時系の変化を見たいので、年月情報の追加
になります。
データソースを作成する
Amazon QuickSightへ直接CSVをアップロードすることも可能ですが、今回は一旦MySQLへデータ投入する想定で進めます。
データベース作成とデータ投入
データベースの作成とデータ投入を行います。
create database zip;
create user zip_user@'13.113.244.32/255.255.255.224' IDENTIFIED BY 'password';
grant all on zip.* to zip_user@'13.113.244.32/255.255.255.224';
create table zip(
zip char(7),
pref varchar(255),
city varchar(255),
town varchar(255),
pref_r varchar(255),
city_r varchar(255),
town_r varchar(255)
)default charset=utf8;
LOAD DATA LOCAL INFILE "ダウンロードした住所データ" INTO TABLE zip FIELDS TERMINATED BY ',' ENCLOSED BY '"';
「13.113.244.32/255.255.255.224」はAmazon QuickSightのIPアドレス帯となります。グローバルIP経由でMySQLのアクセスをするため、セキュリティグループにもアクセス許可をいれておきましょう。
Amazon QuickSightのIPアドレス帯:https://docs.aws.amazon.com/ja_jp/quicksight/latest/user/regions.html
Amazon QuickSightへ取り込む
初期セットアップ
Amazon QuickSightは最初にサインインが必要になります。
無料枠と試用期間が設けられていて、お試しであれば無料で利用可能です。
参考:https://dev.classmethod.jp/articles/amazon-quicksight-free-tier-free-trial/
今回は「Enterprise Edition」を利用してみます。
参考:https://aws.amazon.com/jp/quicksight/pricing/
データセットの作成
データセットの作成を行い、MySQLからデータの取り込みを行います。
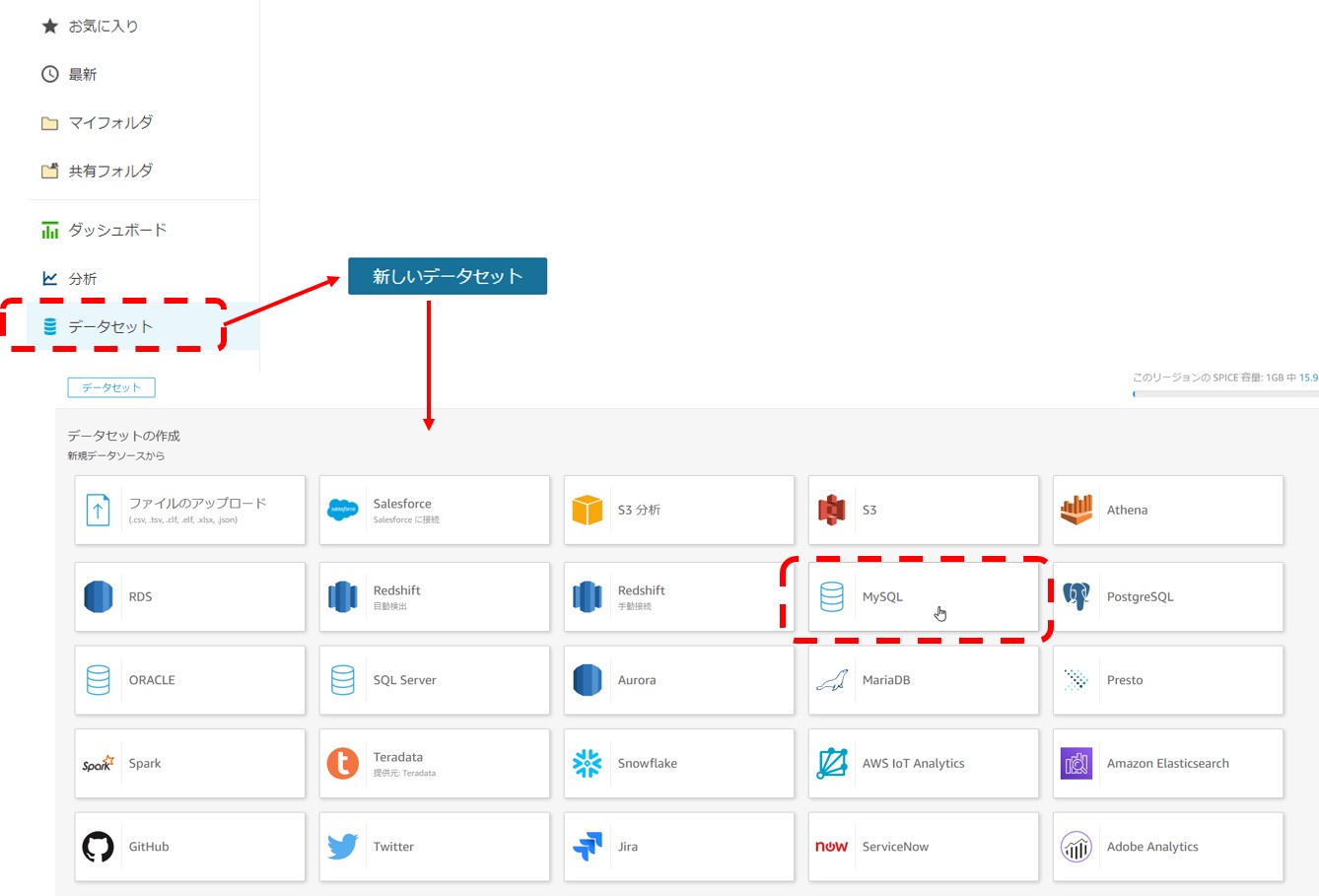
データソースへの接続情報の入力を行います。接続できない場合は、セキュリティグループやMySQLのユーザー情報の確認をしましょう。
テーブルのデータをそのままインポートすることもできますが、今回は以下のSQLで市区町村データの取得を行います。
select zip,pref,city from zip group by pref,city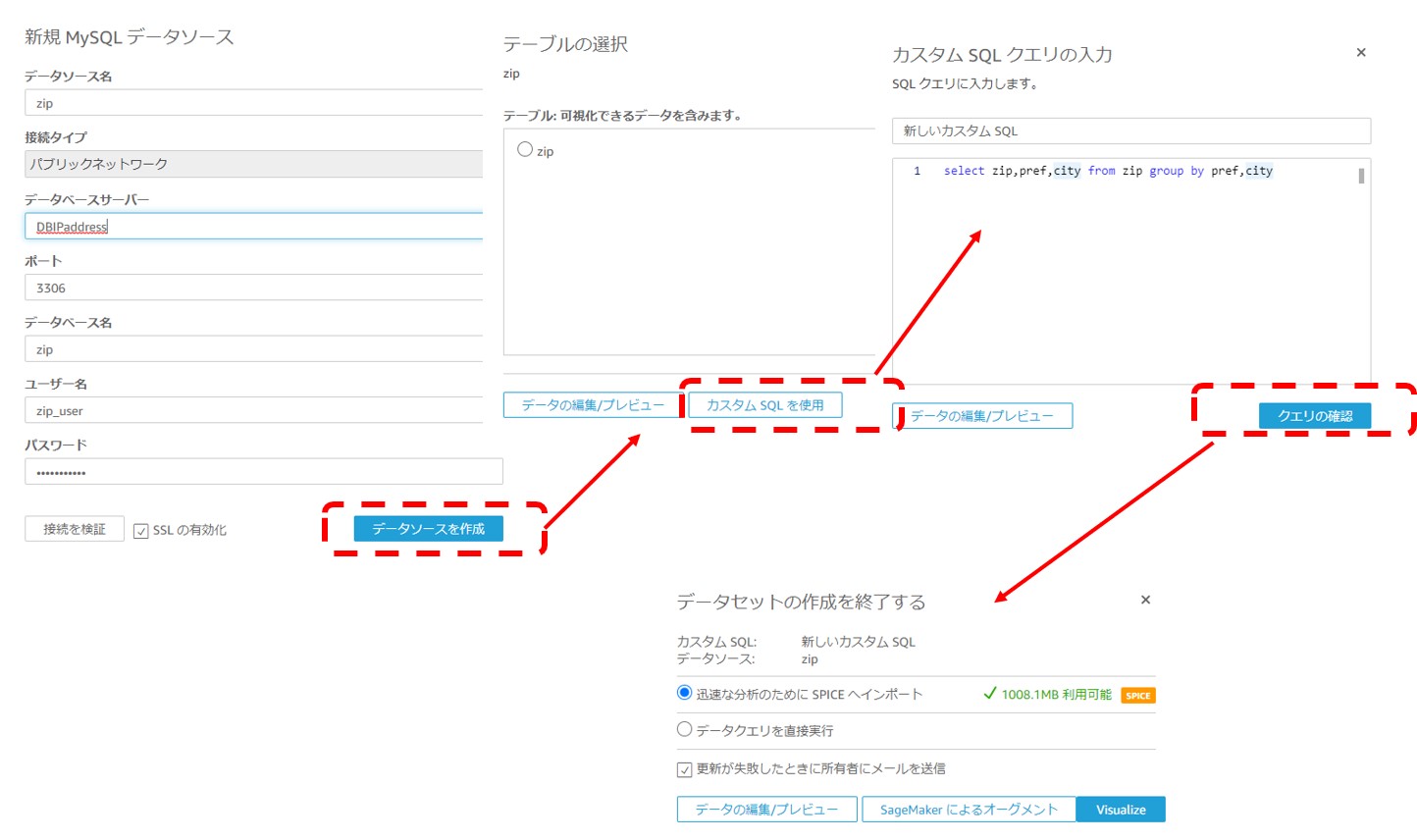
分析を実施する
データセットの作成が終わると分析画面へ切り替わります。
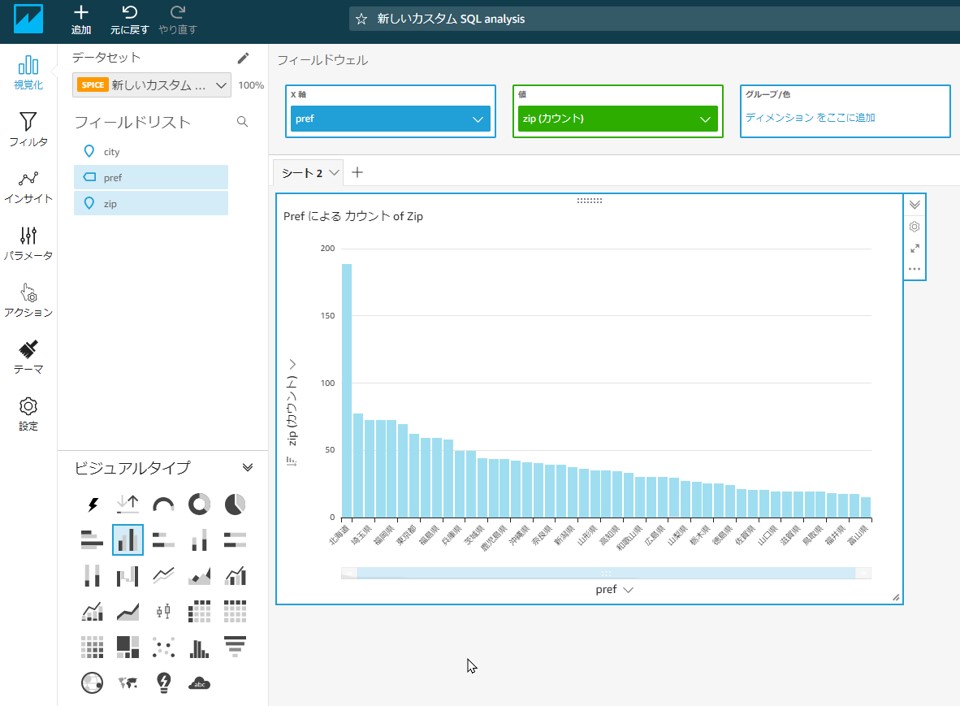
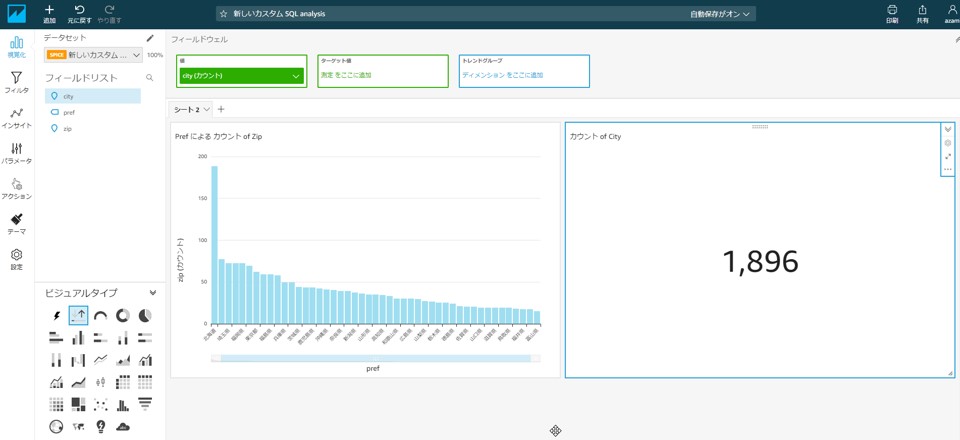
都道府県ごとの市区町村数をカウントした棒グラフを作成する
左下にある「ビジュアルタイプ」から「垂直棒グラフ」を選択します。
フィールドリストの項目を選択し、X軸に「pref」を値に「zip」を設定します。「zip」がグループ/色に設定されてしまった場合は、ドラッグ&ドロップで移動させます。「zip(カウント)」のプルダウンを選択することで、ソートが可能です。
市区町村が一番多いのは北海道で、長野、埼玉と続くようです。
グラフをもう一つ追加してみる
同じタブにもう一つグラフを追加してみます。
エスケープを押して、再度フィールドリストの項目を選択すると、もう一つグラフが作成されます。
「ビジュアルタイプ」の「主要業務指数(KPI)」を選択し、フィールドリストの「city」を選択すると、市区町村数が表示されます。
2020年6月現在の市区町村数は1,896ということのようです。
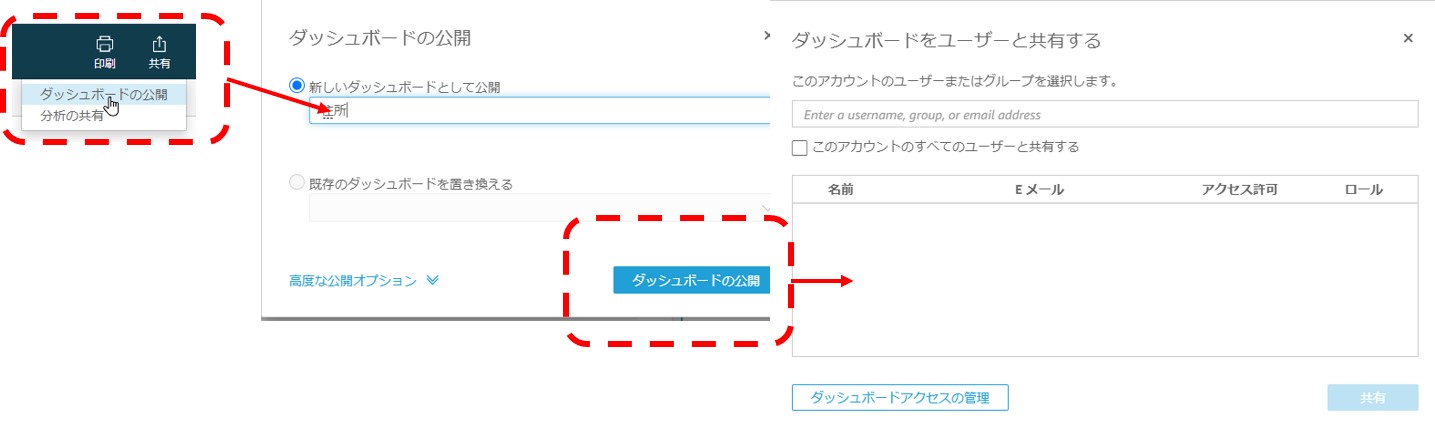
ダッシュボードで共有する
分析結果のグラフが出来上がったら、ダッシュボードで共有します。他のユーザーに共有する場合は、事前に「QuickSightの管理」からユーザーを招待しておく必要があります。ユーザー招待をすると、試用期間後有償になるので注意しましょう。
まとめ
BIツールとして、Amazon QuickSightを使ってみました。使ってみようと思い立ってから、半日程度でグラフ化することができました。無料で試すことができ、有償で使う場合も使った分だけ払いのツールなので、非常に使い勝手がよさそうです。
社内に眠っているデータから有用な情報を取得したい!と持った方は一度お試しください。
QuickSightが気になる方はこちらもどうぞ→QUICKSIGHTのデータソースをMYSQLからATHENA+AMAZON S3に変更してみた

お客様の課題ヒアリングと提案活動をメインに行っていましたが、2021年からはマーケティング担当として活動しています。技術ブログはもちろん、様々な形でディーネットの取り組みについて発信していきますので、よろしくお願いします!