
前回の記事でQuickSightを使って住所コード一覧の情報をグラフ化してみました。
前回の記事→社内データのBIツールとして、AMAZON QUICKSIGHTを使ってみた話。
極力既存のナレッジが利用できるように、データソースにはMySQLを指定していました。が、しかし、BIのためにわざわざEC2インスタンスをたてて運用するのもなぁと思ってきたので、データソースをMySQLからAthena+Amazon S3へ移行してみました。図のようなイメージです。

今回は、QuickSightのデータソースをAthena+S3にする方法を紹介します。Athenaは、Amazon S3内のデータを標準的なSQLを使用して検索できるサービスです。SQLが利用できるので、既存ナレッジの活用ができつつ、データ置き場をS3とするためEC2インスタンスの運用が不要になる素敵な構成です。
目次
S3の設定
S3のバケットを作成します。
aws s3 mb s3://denet-blog-zipそのうえで住所コード一覧のcsvファイルをアップロードします。ファイルは下記よりダウンロードしており、解凍後zip.csvとリネイムしています。
全国一括のデータファイル:https://www.post.japanpost.jp/zipcode/dl/roman-zip.html
aws s3 cp zip.csv s3://denet-blog-zip/zip/
aws s3 ls s3://denet-blog-zip/zip/念のためマネジメントコンソールからも確認してみます。
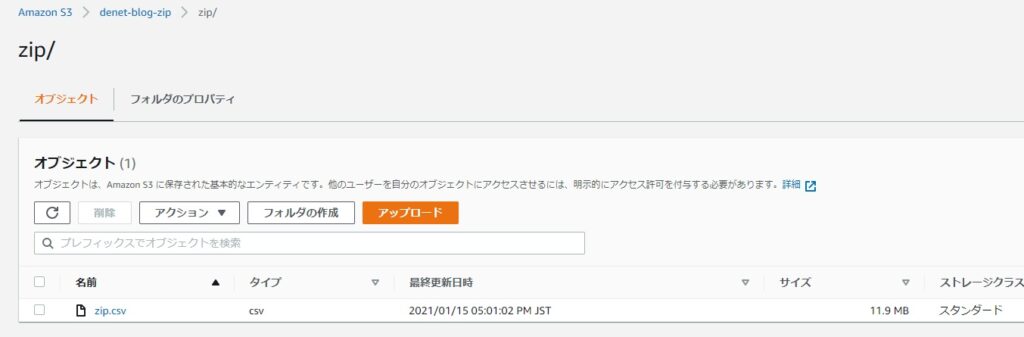
無事にアップロードされていそうです。
のちほど、Athenaでアップロードしたファイルをテーブルに見立てて利用することになるのですが、「テーブル」=「フォルダ」として扱うことになります。そのため、「zip」フォルダを作成し、その中にファイルをアップロードしました。フォルダ内に複数ファイルが存在している場合は、自動でマージしてくれるので、定期的にファイルアップロードするだけでデータの追加が可能です。
Athenaの設定
テーブル定義
次にAthenaの設定を行っていきます。まずはじめにテーブル定義を行う必要があります。
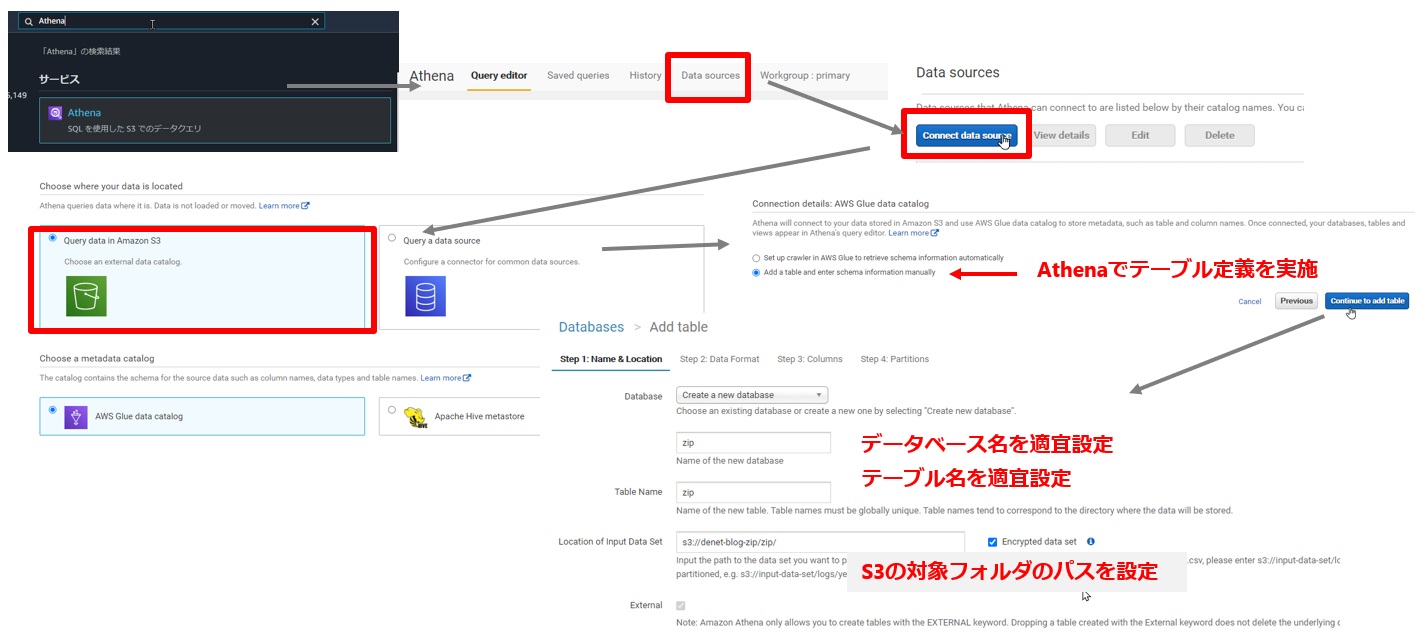
「Data Sources」の「connect data sources」から作成していきます。図のように進めていきます。(見にくいので別タブで画像を開いてもらえると良いかと思います)
データソースにS3を設定して、データベース名、テーブル名は適当に設定します。データソースのロケーションにS3の対象フォルダを設定します。今回は、「s3://denet-blog-zip/zip/」を設定しました。
DataFormatにcsvを設定します。列定義の設定を適宜行います。今回は「Bulk add columns」から一括登録を行います。
zip string,pref string,city string,town string,pref_r string,city_r string,town_r string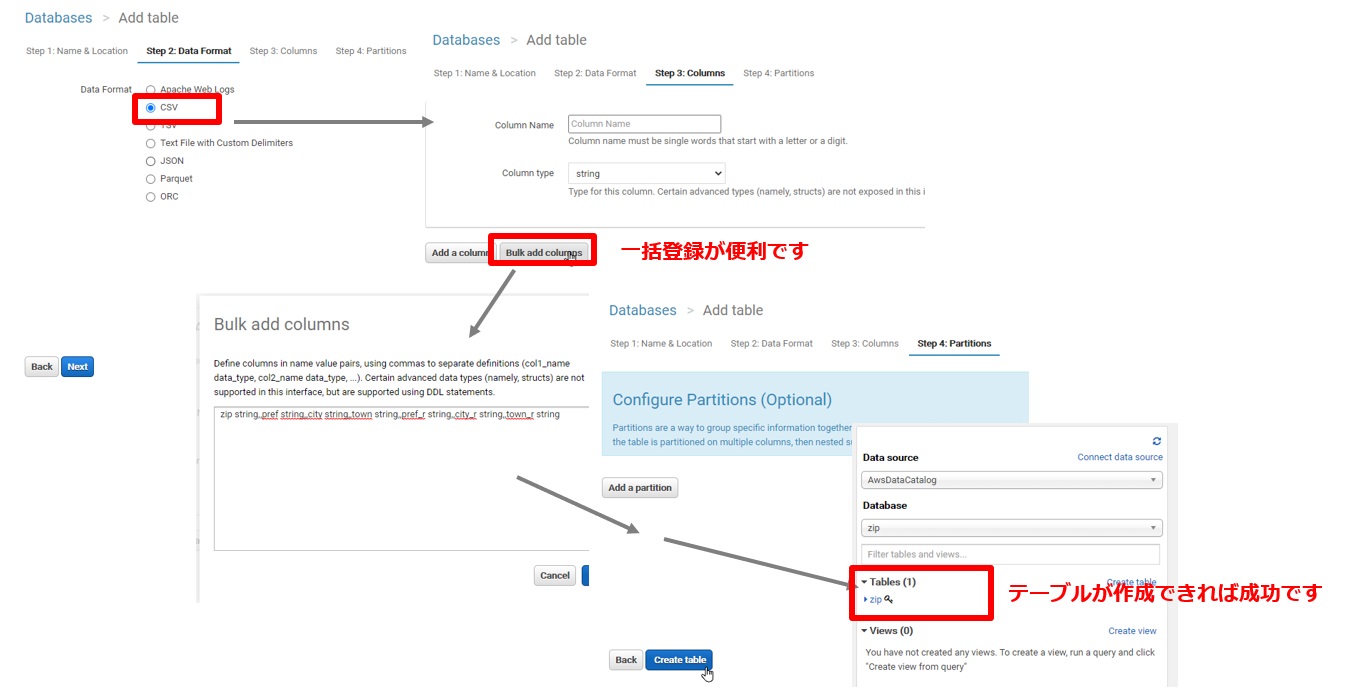
以下クエリの実行でも作成が可能です。
CREATE EXTERNAL TABLE IF NOT EXISTS zip.zip (
`zip` string,
`pref` string,
`city` string,
`town` string,
`pref_r` string,
`city_r` string,
`town_r` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://denet-blog-zip/zip/'
TBLPROPERTIES ('has_encrypted_data'='true');クエリ時の実行
試しにクエリを実行してみましょう。クエリの実行は「QueryEditor」から行います。Reusltsに「124433」が表示されれば成功です。
select count(*) from zip;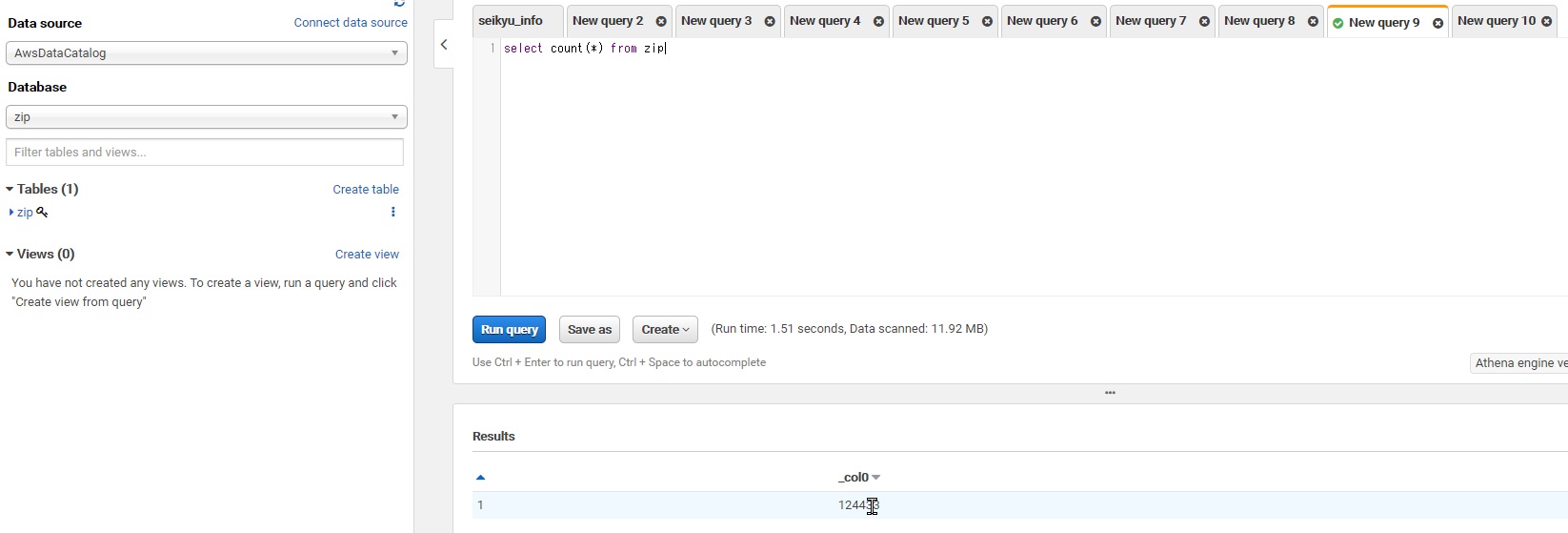
Athenaでは、SQL文中にダブルクォーテーションは利用できないようです。固定文字列を使う場合はシングルクォーテーションを利用しましょう。
複数テーブル用意して結合もできるので、普通のデータベース感覚で扱えます。
QuickSightの設定
Amazon S3とAthenaの設定ができたので、QuickSightの設定を行っていきます。
データセットの設定
新規データソースに「Athena」を選択します。Athenaで作成したデータベース「zip」を選択して「カスタムSQLを使用」します。QuickSightから実行する場合は、テーブル名の前にデータベース名を指定してあげる必要があるようです。
select pref,city from zip.zip group by pref,city;おそらく最初はSQL例外のエラーが発生します。
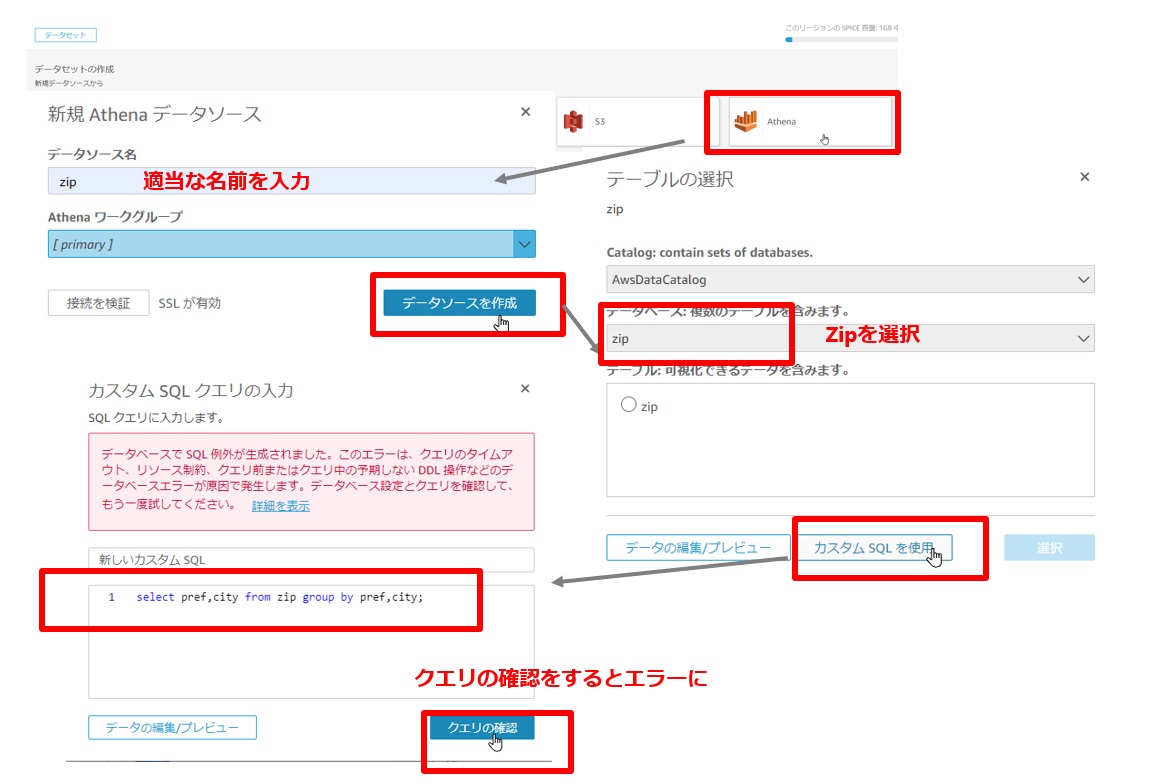
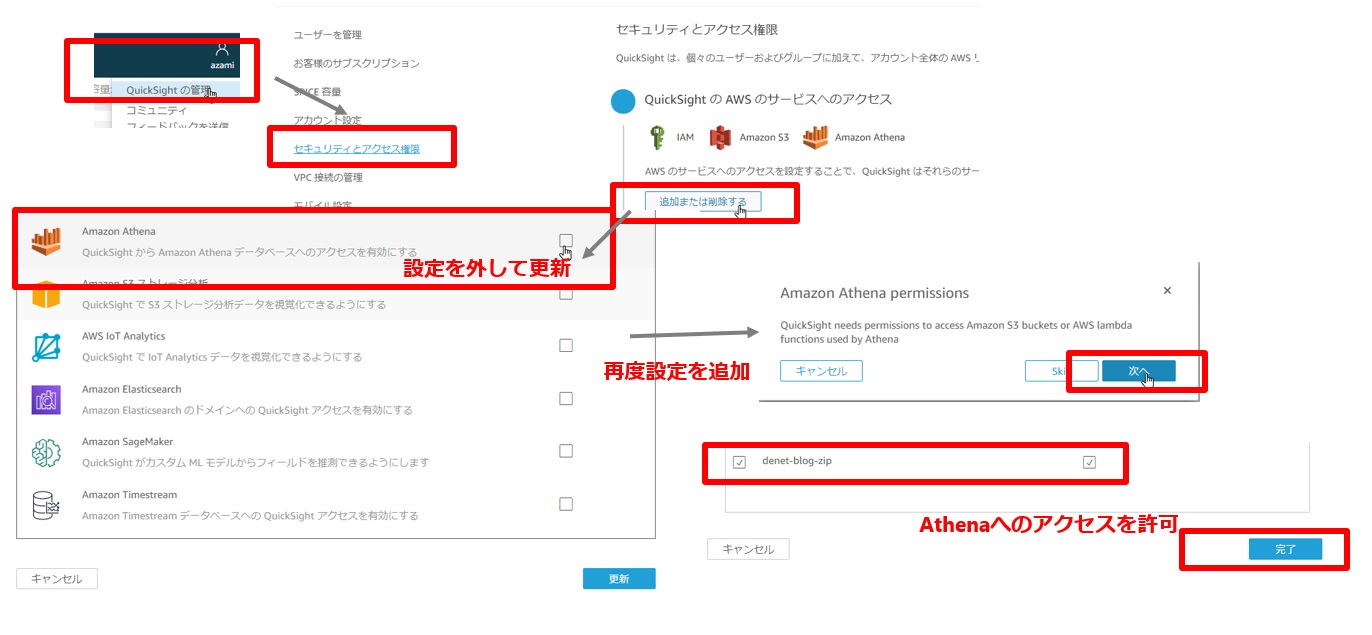
Athenaへの接続許可設定
QuickSightからAthenaへの接続許可を入れる必要があります。右上の「QuickSightの管理」を選択し、「セキュリティとアクセス権限」の設定を行います。「QuickSight の AWS のサービスへのアクセス」には、すでにAthenaが追加されていますが、一度削除を行います。削除後に再設定すると、データベースを選ぶことができるので、今回作成したデータベースを選択します。
データセットの設定 その2
データソースの設定を実行してみると、データ取得が成功するはずです。
分析の実施
データの取得ができたら、通常通り分析の実施が可能です。
まとめ
QuickSightのデータソースをMySQLからAthena+Amazon S3へ変更してみました。S3に対してSQLが利用できるので、意外と敷居は低いと感じました。
BI用途のためにEC2インスタンスの管理をするのは手間なので、S3をデータソースにできることはすごくメリットがありそうです。

お客様の課題ヒアリングと提案活動をメインに行っていましたが、2021年からはマーケティング担当として活動しています。技術ブログはもちろん、様々な形でディーネットの取り組みについて発信していきますので、よろしくお願いします!
記事参考に読ませていただきました。大変勉強になりました。
ありがとうございます。
1つ疑問が湧いているのですが、現在「S3 => Amazon Athena => Amazon QuickShit」という構成でデータ分析とデータの可視化を行っているように見受けられます。Amazon QuickShitはS3をデータソースとして選択できアドホック分析もできると思っているのですが、間にAmazon Athenaをいれられているのにはどのようなメリットが有るのかお伺いしたいです。
これ疑問が現在の私自身の課題でもあるので返信頂けますと幸いです。
よろしくお願いいたします。
竹中様
コメントありがとうございます。
ご指摘の通り
「S3 => Amazon Athena => Amazon QuickSight」
の構成としております。
Athenaを使っている理由ですが、
・複数種類のデータを扱いやすい
・データをSQLで扱える(学習コストが低く、結合ができる)
という2点となります。
Athenaを使うことで、S3内の各フォルダをテーブルに見立てて扱うことができます。
たとえば、
・「s3://denet-blog-zip/zip/」は、住所テーブル
・「s3://denet-blog-zip/employee/」は、社員テーブル
のような形です。
こうすることで、SQLを使って、社員の住所情報を結合して扱うことが可能です。
つまり、SQLで必要な情報を結合してQuickSightへ取り込むことが可能になります。
ブログ記事内の例は簡単な内容にしていましたが、実際の社内データを扱うさいには複数種類のデータを扱っています。
そのため、Athenaでデータごとにテーブルを作成し、必要に応じて結合などを行いQuickSightへ取り込んで利用する形としています。
(データはS3内の所定フォルダにアップロードするだけでOKです)
わたしは、S3をデータソースに指定したことがなかったりするのですが、結合などの処理が難しいのではないかと思います。
ご丁寧に返信いただきありがとうございます。
とてもわかりやすい説明をいただき私の中での疑問「なぜ間に Amazon Athenaを挟むのか」に対する答えを見つけることが出来ました。
今後システムを組んでいく際に「SQLの結合」について深堀りして調べ、ブログで紹介されている構成を組んできたいと思います。
本当にありがとうございました。
竹中様
お役に立ててよかったです。
頑張って組んでみてください!