
目次
はじめに
検証環境で調べ事をしたあとRDSを停止するのを忘れたままサインアウトして、
後日RDSをつけっぱなしにしていることに気づくということが何度かあり、そのたびに心が苦しくなってしまっていました。
今回は、こういったことを減らすためのしくみを考えてみたのでそれを紹介したいと思います。
構成について
構成図
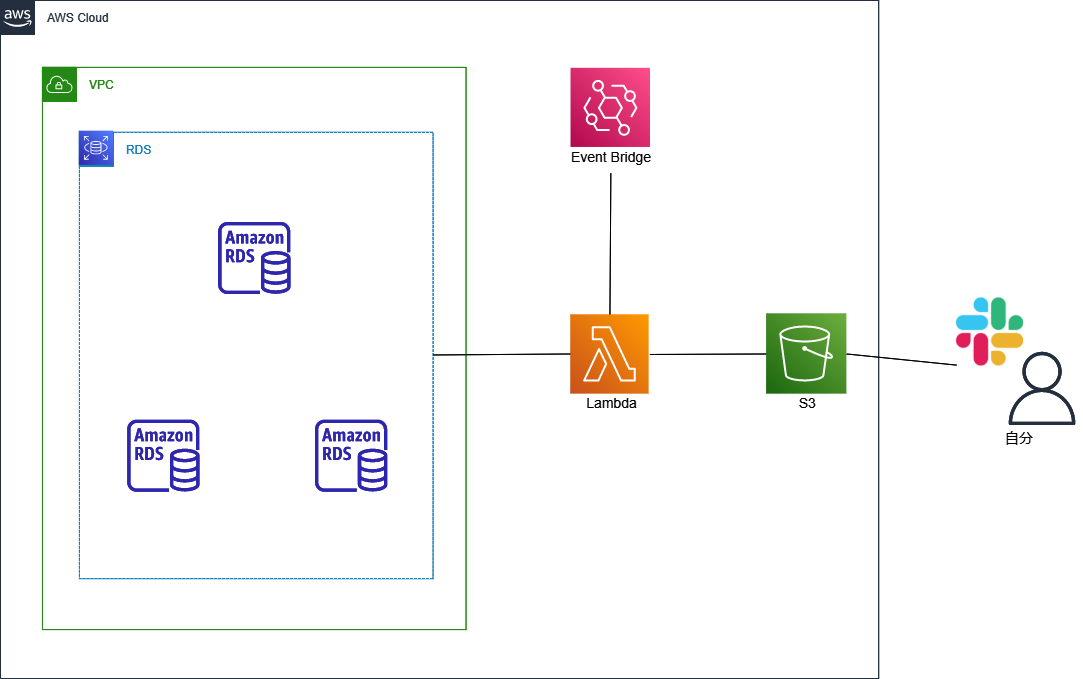
処理の大まかな流れ
- Event Bridgeで発行されるイベントをトリガーにLambdaが起動
- S3のファイルから起動していたRDSインスタンスの数を確認
- APIで現在起動しているRDSインスタンスの数を確認
- 2より3の値を比較
- 3が大きければS3にRDSインスタンス数を上書きしてSlackに通知
Slackの通知を見てコンソールからRDSインスタンスを停止する流れになります。
実装に求めたこと
- お金があまりかからない
- 忘れそうな処理を挟まない
- インスタンスの操作は手動
この3点を意識したような気がします。
CloudTrailのログ機能は使いませんでした。
というのもRDSのみ監視という点でコスト的に必要ないと判断したためです。
同様の理由で自動タグ付けの処理等も省きました。手動で登録も忘れるのでなしの方向で進めています。
コストといっても雀の涙でしょ、といってしまえばそうですがCloudTrail+S3の場合AWS公式では1日に最大288回ほどS3に書き込むそうなのですが、今回構築したコードでは1日1~2回しか書き込みを行いません。
響きをよくすれば1/288までコストカットできたということになります。
S3バケットのファイルも1バイトしかないため実質無料です。
Q: CloudTrail はどれくらいの頻度で Amazon S3 バケットにログファイルを送信しますか?
CloudTrail は Amazon S3 バケットに約 5 分ごとにログファイルを送信します。そのアカウントに対して API コールがない場合、CloudTrail はログファイルを送信しません。
Lambdaで実行するコード
実際にLambdaで処理されるコードです。Slackに投稿する処理だけ借りさせていただきました。
import json
import urllib.request
import logging
from collections import OrderedDict
import pprint
import boto3
import random
s3 = boto3.resource('s3')
rds = boto3.client('rds')
bucket = 'denet-s3-bucket-name' #バケット名
key = 'rds-instance-count.txt' #インスタンス数を保存するファイル
#コードお借りしました。
#https://qiita.com/suo-takefumi/items/b47922362366de897920
def post_slack(count):
message_list = [
'ここに通知時メッセージをいれる。',
'いれる。',
]
send_data = {
"text": random.choice(message_list) + '\n 現在起動中のインスタンス数: ' + str(count),
}
send_text = json.dumps(send_data)
request = urllib.request.Request(
'https://hooks.slack.com/services/HO6EH0G3/HUG4HU6A/P1Y0PIYOPIYO',
data=send_text.encode('utf-8'),
method="POST"
)
with urllib.request.urlopen(request) as response:
response_body = response.read().decode('utf-8')
def get_rds_instance_count_from_s3(bucket,key):
obj = s3.Object(bucket,key)
data = obj.get(Range='string')['Body'].read()
return int(data.decode('utf-8'))
#RDSのインスタンス数を取得してavailableならカウントする。
def get_rds_instance_count_from_rds():
db_list = rds.describe_db_instances(MaxRecords=100)['DBInstances']
count=0
for db in db_list:
if db['DBInstanceStatus'] == 'available':
count+=1
return count
#RDSインスタンス数をS3バケットに書き込みする。
def save_rds_status_to_s3(bucket,key,recent_count,last_count):
file_contents = str(recent_count)
obj = s3.Object(bucket,key)
#インスタンス数に変更があった場合のみ書き込み処理
if not recent_count == last_count:
obj.put(Body=file_contents)
def lambda_handler(event, context):
yesterday_count = get_rds_instance_count_from_s3(bucket,key)
rds_instance_count = get_rds_instance_count_from_rds()
save_rds_status_to_s3(bucket,key,rds_instance_count,yesterday_count)
#インスタンス数が増えたままだと鳥が怒る。
if rds_instance_count > yesterday_count:
post_slack(str(rds_instance_count))eventはEvent Bridgeで帰宅する前と適当な時間に設定しています。
適当な時間というのはSlackで通知後に自分がRDSインスタンスを停止したのを検知するために走らせているイメージです。
bucketとkeyはそれぞれS3で作成したバケットとファイルを設定して、このコードとは別にLambdaがそれを触れるよう権限を与えています。
Slackとの連携の箇所も同様にあらかじめ設定していたWebhookのキーを割り当てています。
54行目の処理は正直いらなそうですが、ほんの少しだけ料金を抑えるために確認しています。
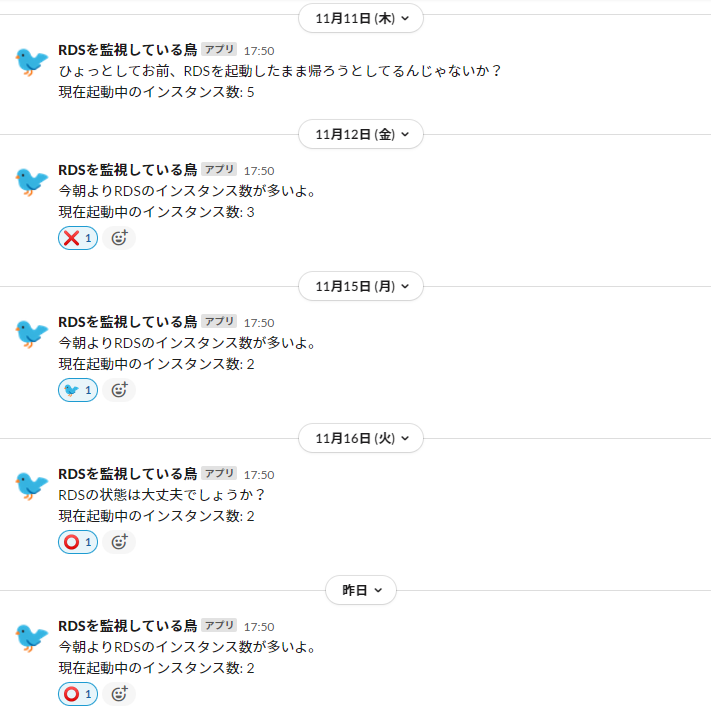
実行結果
無事にSlackに投稿されています。
おわりに
穴がありそうな構成ですが、意外なことにいまのところ順調に想定している動作をしています。
ただ一度だけ通知を見たのにも関わらず停止するのを忘れてしまうことがありました。
途中で気づけたので同期と先輩に頼んで停止していただき事なきは得ましたが。。
今後の改善案として、頑張れば今の環境にAPI Gatewayを加えてSlack上から停止できそうなのでそれもよいかなと思いました。
参考になれば幸いです。