
目次
はじめに
こんにちは、omkです。
Glueでデータを加工する上で特に困るのがデータの重複や崩れたデータの混入ですよね。
元データにこれらが存在することに気づかず(自動化したらほぼ気づかないと思います)そのまま加工にデータを使ってしまって大変、しかも加工後のデータはS3に出力するから問題のあるデータがどのファイルにあるかも分からない、なんてことあると思います。
私も何度か苦しみました。
結局ジョブの実行前の状態に戻した上で元データをきれいにしてジョブをやり直したり、加工済みのデータから問題のあるデータを削除するジョブを作ったり、事前にデータがきれいなことを確認できていればこんなことにはならなかったのに。
そんなわけでGlue Data Qualityを利用してテーブルが問題ないかを確認します。
Data Qualityとは
Glue Data Catalogのテーブルに対してテーブルやカラムのクォリティが適切かを評価することができます。
例えば特定カラムの値が一意であるか、値がNullでないか、データの新しさや平均値や合計値など、独自に用意したルールを満たす状態であるかを評価し、レポートしてくれます。
推奨のルールセットを自動で用意してくれる設定もあったりします。
23年4月現在はプレビュー版となっております。
やってみた
ルールセット作成
ルールの一覧はこちらに記載があります。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/dqdl.html
今回は冒頭に上げたテーブル内容の重複とデータの崩れに着目します。
データの重複については「IsUnique」「IsPrimaryKey」で評価できると思います。一旦「IsUnique」で評価します。
データの崩れについては、ダブルクォーテーションや改行などが値に混ざっていて適切にエスケープ出来ていないと割と簡単に起こるイメージがあります。
そいうった場合にカラム数が増えることがありますので「ColumnCount」で評価します。
そんなわけで次のルールが出来ました。
Rules = [
ColumnCount = 3,
IsUnique "name"
]わざとおかしなデータを上げて評価を実行してみます。
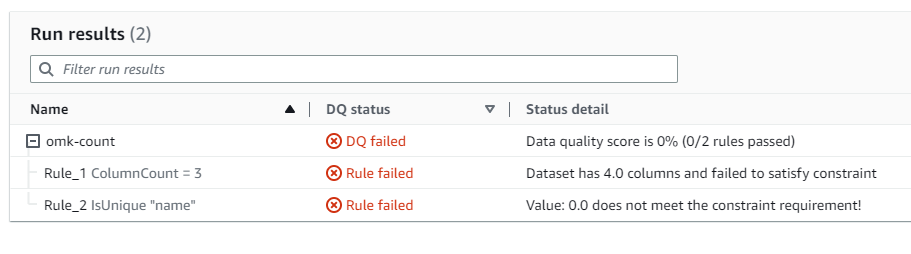
ボロボロの結果になったので成功です。
JSONで結果をダウンロードすることも可能です。
{
"RunId": "dqrun-532e6e1b7124ffb330cb276ccf08d7475fbd9525",
"Status": "SUCCEEDED",
"StartedOn": "2023-04-11T07:20:26.607Z",
"DataSource": {
"GlueTable": {
"DatabaseName": "omkblogdb",
"TableName": "family"
}
},
"ResultId": "dqresult-85dfbcd8d231d5cbf0392d8e4fd74f0ff22b76d6",
"Score": 0,
"RulesetName": "omk-count",
"CompletedOn": "2023-04-11T07:20:35.550Z",
"RulesetEvaluationRunId": "dqrun-532e6e1b7124ffb330cb276ccf08d7475fbd9525",
"RuleResults": [
{
"Name": "Rule_1",
"Description": "ColumnCount = 3",
"EvaluationMessage": "Dataset has 4.0 columns and failed to satisfy constraint",
"Result": "FAIL"
},
{
"Name": "Rule_2",
"Description": "IsUnique \"name\"",
"EvaluationMessage": "Value: 0.0 does not meet the constraint requirement!",
"Result": "FAIL"
}
],
"DQRunStatus": "DQ failed"
}あとはGlueジョブの実行前に評価して結果を確認してからジョブを実行するようにすれば完璧ですね。
残念ながらGlueの「Workflows」ではまだ利用することができませんでした。
StepFunctionsでなら利用できるのでこちらを利用してみます。
ステートマシン作成
では評価の実行と結果の確認を行うステートマシンを作成します。
関連のAPIについては以下にまとまってます。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-data-quality-api.html
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/data-quality-authorization.html
こんな感じになりました。
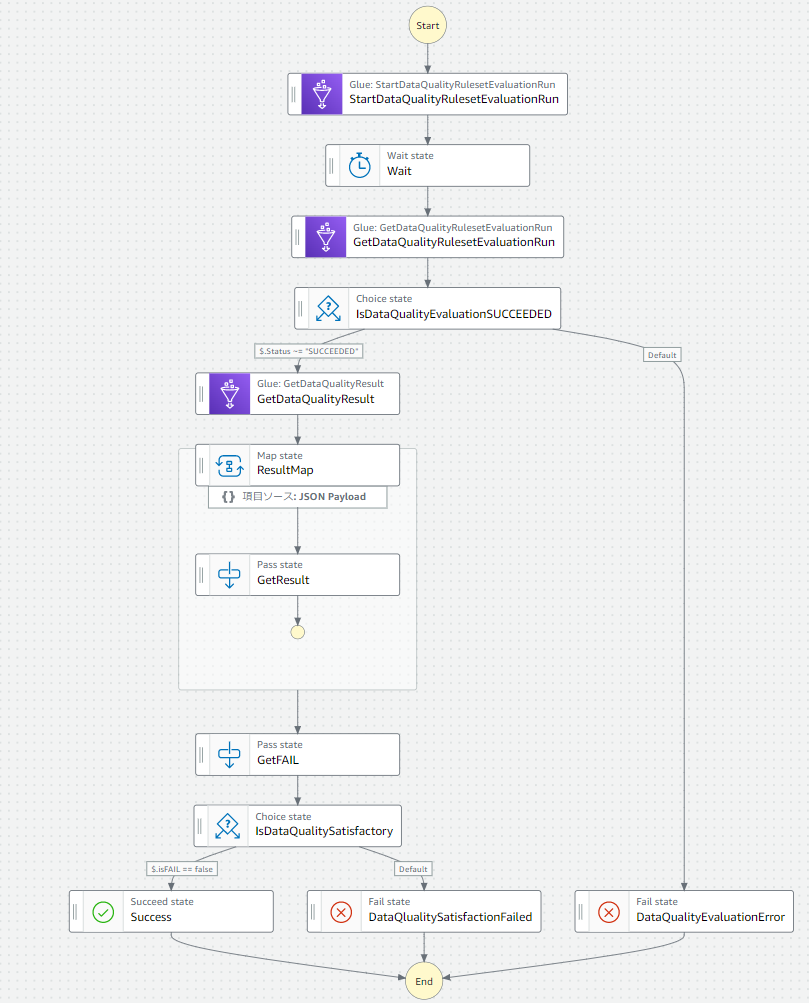
State Languageでは以下。
{
"Comment": "A description of my state machine",
"StartAt": "StartDataQualityRulesetEvaluationRun",
"States": {
"StartDataQualityRulesetEvaluationRun": {
"Type": "Task",
"Parameters": {
"DataSource": {
"GlueTable": {
"DatabaseName": "omkblogdb",
"TableName": "family"
}
},
"Role": "arn:aws:iam::{アカウントIDが入ります}:role/omk-blog-data-job-role",
"RulesetNames": [
"omk-count"
]
},
"Resource": "arn:aws:states:::aws-sdk:glue:startDataQualityRulesetEvaluationRun",
"Next": "Wait"
},
"Wait": {
"Type": "Wait",
"Next": "GetDataQualityRulesetEvaluationRun",
"Seconds": 160
},
"GetDataQualityRulesetEvaluationRun": {
"Type": "Task",
"Next": "IsDataQualityEvaluationSUCCEEDED",
"Parameters": {
"RunId.$": "$.RunId"
},
"Resource": "arn:aws:states:::aws-sdk:glue:getDataQualityRulesetEvaluationRun"
},
"IsDataQualityEvaluationSUCCEEDED": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.Status",
"StringMatches": "SUCCEEDED",
"Next": "GetDataQualityResult"
}
],
"Default": "DataQualityEvaluationError"
},
"GetDataQualityResult": {
"Type": "Task",
"Parameters": {
"ResultId.$": "$.ResultIds[0]"
},
"Resource": "arn:aws:states:::aws-sdk:glue:getDataQualityResult",
"Next": "ResultMap"
},
"ResultMap": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "GetResult",
"States": {
"GetResult": {
"Type": "Pass",
"End": true,
"OutputPath": "$.Result"
}
}
},
"Next": "GetFAIL",
"ItemsPath": "$.RuleResults",
"ResultPath": "$.Result"
},
"GetFAIL": {
"Type": "Pass",
"Next": "IsDataQualitySatisfactory",
"Parameters": {
"isFAIL.$": "States.ArrayContains($.Result,'FAIL')"
}
},
"IsDataQualitySatisfactory": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.isFAIL",
"BooleanEquals": false,
"Next": "Success"
}
],
"Default": "DataQlualitySatisfactionFailed"
},
"Success": {
"Type": "Succeed"
},
"DataQlualitySatisfactionFailed": {
"Type": "Fail"
},
"DataQualityEvaluationError": {
"Type": "Fail"
}
}
}流れとしては以下です。
- 予め用意したルールセットの評価を実行して完了を待ちます。(非同期なのでWaitで待ちます。ほんとは.syncが欲しい)
- 評価の実行が完了したことを確認します。
- ResultIdから評価結果の内容を取得します。
- 複数ルールのそれぞれの成否をMapで取得します。
- 1つでも評価結果に問題があるかを評価します。
- 問題があれば処理をこかします
先程のおかしなデータを入れた状態で実行したところデータに問題があったため最終的に失敗に流れました。
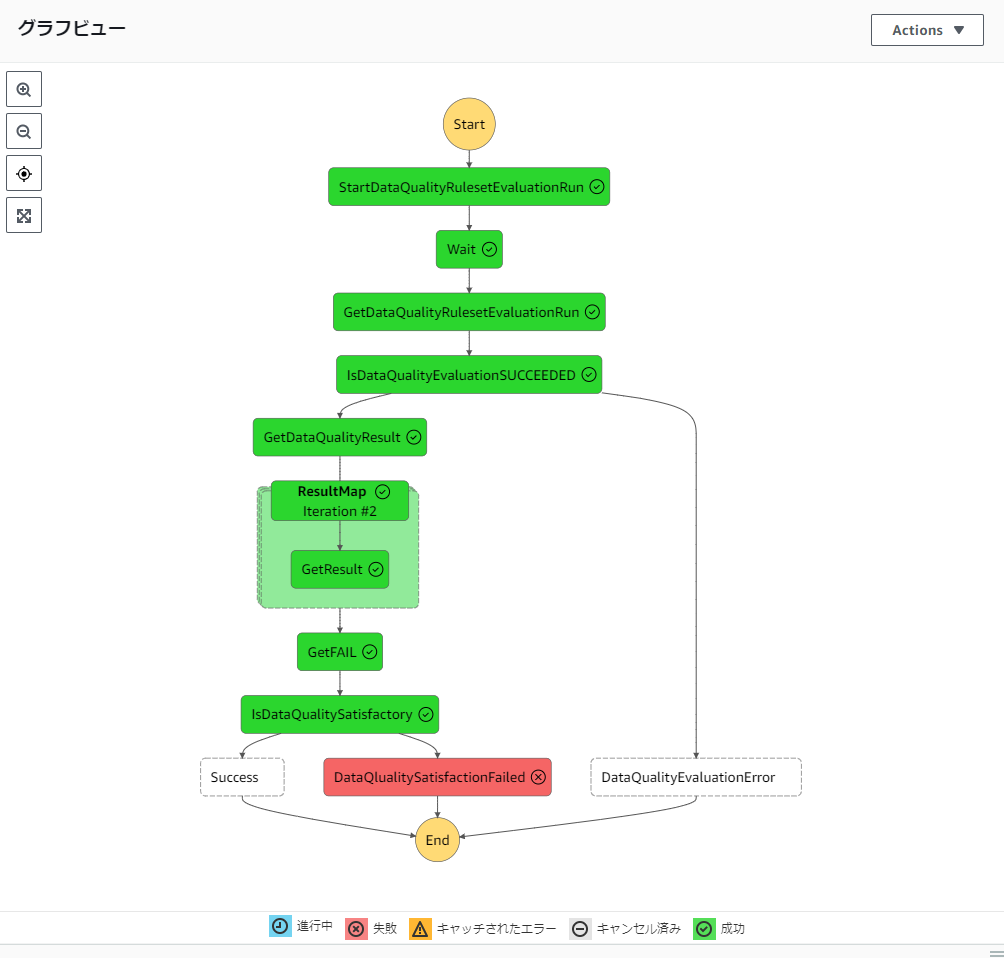
ということでこれにGlueジョブの実行を組み込めばデータに問題があるかを確認した上でジョブを実行でき、問題があれば事前に実行を止める・通知するということが可能になりましたね。
おわりに
今回は決め打ちでルールを作りましたが、何をもって適切とするかというところを事前に想定しておくことがデータクオリティを保つ上で重要だと感じました。
そこの定義さえしっかりできていればあとはルールに基づいて自動で評価してくれるので非常に便利ですね。
機械学習の特徴量エンジニアリングに使えそうなルールが色々ありますので、単純にテーブルが壊れてないかのレベルでなく、一つ一つのデータが適切かあるいはテーブル全体でみたときにデータの品質が保たれているかというところまでしっかり使ってみたいサービスだと思いました。
以上、最後までお付き合いありがとうございました。

アーキテクト課のomkです。
IoTが主食です。