
こんにちは、CI/CDの魅力に取り憑かれたディーネットの山田です。
目次
概要
Amazon SESを使ったAWS案件を担当していてアカウントレベルのサプレッションリスト解除を楽にできないか?と考えPythonでコード化してみました。
Pythonでコード化したのは、Lambdaで使えるためです。
AWSをがっつり触っている方であればもうお気づきかもしれませんが、S3イベントとLambdaを連携させて「メールアドレスを記載したCSVファイルをS3にアップロードしたら自動的にアカウントレベルのサプレッションリストから解除」を実現したいと思います。
Amazon SESについて
Amazon SESについては、以前栩野が紹介したブログがありますので、リンクをまとめておきます。
以下も合わせて確認してみてください。
構成(仕組み)について
- S3バケットのイベントでLambda関数を発火する
- Lambda関数内でアカウントレベルのサプレッションリストからメールアドレスを解除する
- メールで管理者に通知する
環境の作り方について
環境の作成方法をスクリーンショット付きで紹介したいところではありますが、こちらについても以前ブログで詳細に説明しているものがありますので割愛させていただきます。
詳細な作り方は割愛させていただきますが、Pythonコードや必要となるIAMポリシー内容は説明いたします。
S3のイベント通知を使用してLambdaで文字コードを変換する
事前準備として以下をお願いいたします
メールアドレス一覧をアップロードするS3バケットの準備
- S3バケットにファイルがアップロードされたらLambdaを発火するようのバケットになります
サプレッションリスト解除用のS3バケットの準備
- サプレッションリストを一括操作する用のS3バケットを作成する
- SESからS3バケットに保存されているオブジェクトにアクセスできるようにバケットポリシーを設定する Amazon SESのサプレッションリストからメールアドレスを一括追加と一括削除する
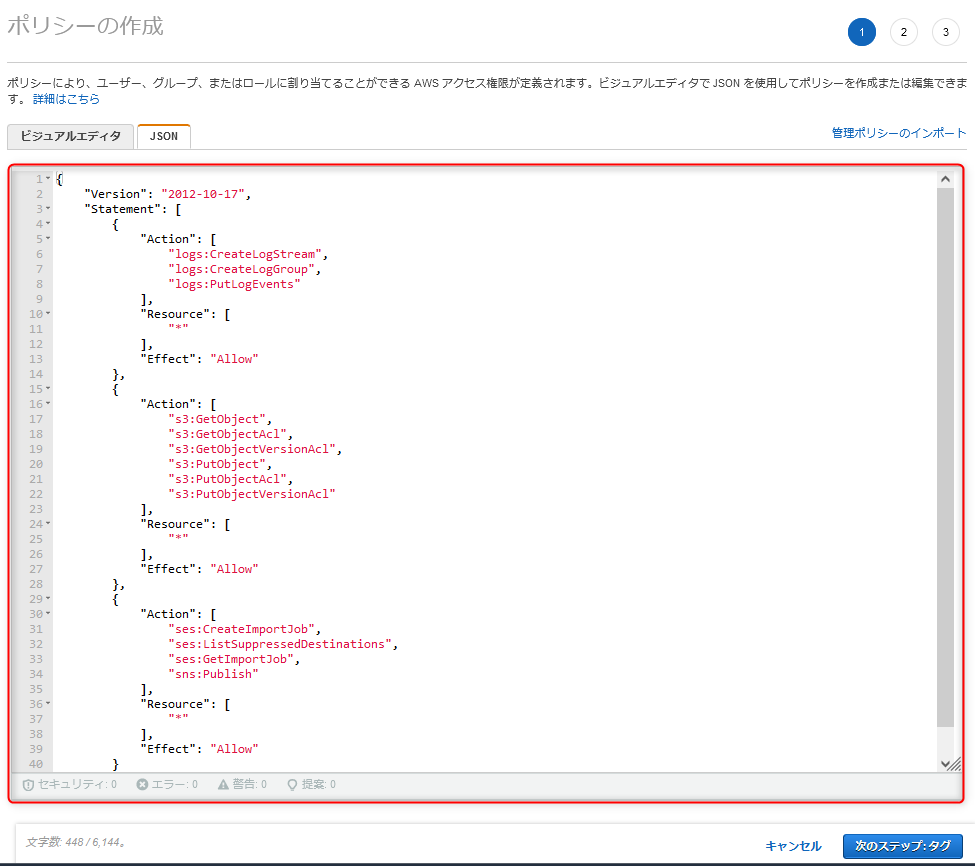
IAMポリシーの作成
- 本ブログ執筆の際には、横着しています
- 正しく運用される際は、ベストプラクティスに則って最低限の権限に絞ってください
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents"
],
"Resource": [
"*"
],
"Effect": "Allow"
},
{
"Action": [
"s3:GetObject",
"s3:GetObjectAcl",
"s3:GetObjectVersionAcl",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:PutObjectVersionAcl"
],
"Resource": [
"*"
],
"Effect": "Allow"
},
{
"Action": [
"ses:CreateImportJob",
"ses:ListSuppressedDestinations",
"ses:GetImportJob",
"sns:Publish"
],
"Resource": [
"*"
],
"Effect": "Allow"
}
]
}
Lambda関数を登録する
関数の作成で、ランタイムをPython3.8にして作成する

以下のソースコードをデプロイする
Pythonコードの内容
import datetime
import boto3
import json
import os
import urllib.parse
import uuid
import time
import re
def lambda_handler(event, context):
# eventで受け取った内容をそのまま表示
print("Received an event ...")
print(event)
# 実行開始時間を記録
now = datetime.datetime.now()
# UUIDを生成
uuid4hex = str(uuid.uuid4())
# 環境変数から情報を取得
bucketname = os.getenv("BUCKETNAME")
ses_region = os.getenv("SES_REGION")
sns_region = os.getenv("SNS_REGION")
topic = os.getenv("TOPIC")
# Lambdaの一時領域に保存するようなファイルパスを生成
filename = "/tmp/{0}.list".format(now.strftime("%Y%m%d%H%M%S"))
# パラメータ数を超えるとファイルを分割
# SESv2で使用するジョブは、10000件までしか一度に流し込めない
max_line = 5000
# boto3のライブラリを使ってインスタンスを生成
sesv2 = boto3.client("sesv2", region_name=ses_region)
sns = boto3.resource("sns", region_name=sns_region)
s3 = boto3.resource("s3")
# SESのサプレッションリスト解除用のS3バケットを選択
bucket = s3.Bucket(bucketname)
# 変数の初期値を定義
part = 1
# S3イベントから受け取ったイベント数分ループ処理
for eventdata in event["Records"]:
# アップロードされたS3オブジェクトを取得
print("Bucketname ...")
uploadbucketname = eventdata["s3"]["bucket"]["name"]
print(uploadbucketname)
print("Objectkey ...")
uploadbucketobject = eventdata["s3"]["object"]["key"]
print(uploadbucketobject)
# イベントで受け取ったS3バケット名を選択
uploadbucket = s3.Bucket(uploadbucketname)
# S3オブジェクトをURLデコード
print("URL Decode ...")
bucketobject = urllib.parse.unquote(uploadbucketobject)
print(uploadbucketobject)
# S3からオブジェクトをダウンロード
print("Object Download ...")
uploadbucket.download_file(uploadbucketobject, filename)
# ダウンロードしたファイルの行数を取得
print("Lines Check ...")
lines = len(open(filename).readlines())
print(lines)
# ダウンロードしたファイルの行数が1行以上あれば処理を続行
if lines >= 1:
# 変数の初期値を定義
now_line = 0
# ダウンロードしたファイルの展開と分割先を準備
source = open(filename, mode="r", encoding="UTF-8")
dest = open(
"{0}/{1}_part{2}_{3}.list".format(
os.path.dirname(filename),
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
),
mode="a",
encoding="UTF-8",
)
# ダウンロードしたファイルを読込
line = source.readline()
while line:
# 5000行以上あればファイルを分割
if now_line >= max_line:
dest.close()
print("S3 Upload ...")
print("part/{0}_part{1}_{2}.list".format(
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
))
# 分割したファイルをS3にアップロード
bucket.upload_file(
"{0}/{1}_part{2}_{3}.list".format(
os.path.dirname(filename),
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
),
"part/{0}_part{1}_{2}.list".format(
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
),
)
print("sleep 1sec ...")
time.sleep(1)
print("Request Job ...")
print("s3://{0}/part/{1}_part{2}_{3}.list".format(
bucketname,
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
))
# S3にアップロードしたファイルを使ってSESのサプレッションリスト解除申請を行う
response = sesv2.create_import_job(
ImportDestination={
"SuppressionListDestination": {
"SuppressionListImportAction": "DELETE"
}
},
ImportDataSource={
"S3Url": "s3://{0}/part/{1}_part{2}_{3}.list".format(
bucketname,
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
),
"DataFormat": "CSV",
},
)
print(response)
# 解除した宛先を取得
request_mailto = open(
"{0}/{1}_part{2}_{3}.list".format(
os.path.dirname(filename),
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
)
).read()
# SNSを使ってメールで解除申請を行った案内を送る
response = sns.Topic(topic).publish(
Subject="サプレッションリストの解除申請を行いました",
Message="サプレッションリストの解除申請を行いました\n解除申請を行いましたので、宛先メールアドレスをご確認ください。\n\n■アドレス一覧\n{0}\n※5000件を超える場合は、複数回通知されます。".format(
request_mailto
),
)
print(response)
# 変数のインクリメントと値の初期化
part = part + 1
now_line = 0
# 分割先を新たに準備
dest = open(
"{0}/{1}_part{2}_{3}.list".format(
os.path.dirname(filename),
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
),
mode="a",
encoding="UTF-8",
)
# 内容を分割先に書込して、変数のインクリメントとダウンロードしたファイルを読込
line = re.sub('[\r\n]+$', '', line)
dest.write(line + "\n")
now_line = now_line + 1
line = source.readline()
source.close()
dest.close()
print("S3 Upload ...")
print("part/{0}_part{1}_{2}.list".format(
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
))
# 分割したファイルをS3にアップロード
bucket.upload_file(
"{0}/{1}_part{2}_{3}.list".format(
os.path.dirname(filename),
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
),
"part/{0}_part{1}_{2}.list".format(
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
),
)
print("sleep 1sec ...")
time.sleep(1)
print("Request Job ...")
print("s3://{0}/part/{1}_part{2}_{3}.list".format(
bucketname,
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
))
# S3にアップロードしたファイルを使ってSESのサプレッションリスト解除申請を行う
response = sesv2.create_import_job(
ImportDestination={
"SuppressionListDestination": {
"SuppressionListImportAction": "DELETE"
}
},
ImportDataSource={
"S3Url": "s3://{0}/part/{1}_part{2}_{3}.list".format(
bucketname,
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
),
"DataFormat": "CSV",
},
)
print(response)
# 解除した宛先を取得
request_mailto = open(
"{0}/{1}_part{2}_{3}.list".format(
os.path.dirname(filename),
os.path.splitext(os.path.basename(filename))[0],
part,
uuid4hex,
)
).read()
# SNSを使ってメールで解除申請を行った案内を送る
response = sns.Topic(topic).publish(
Subject="サプレッションリストの解除申請を行いました",
Message="サプレッションリストの解除申請を行いました\n解除申請を行いましたので、宛先メールアドレスをご確認ください。\n\n■アドレス一覧\n{0}\n※5000件を超える場合は、複数回通知されます。".format(
request_mailto
),
)
print(response)
# 変数のインクリメントと値の初期化
part = part + 1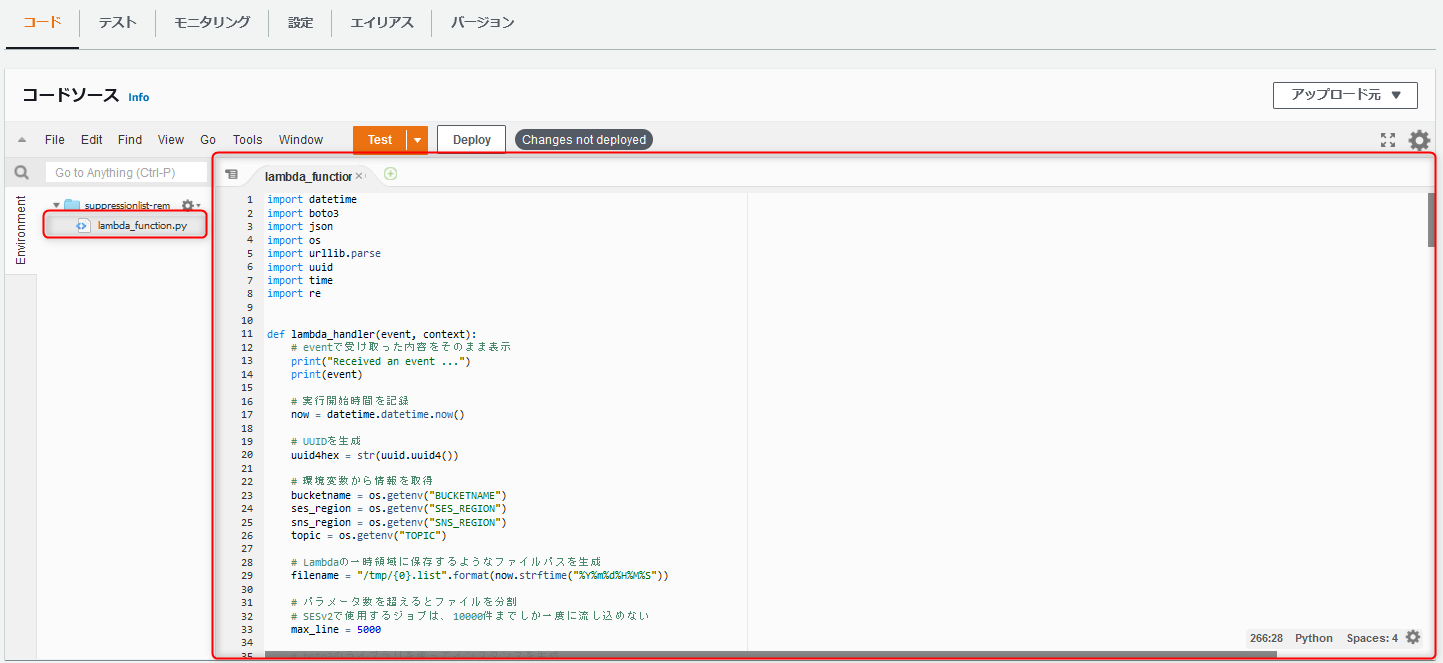
流れとしては、以下のような動きをします
- S3バケットのイベントでLambda関数が発火する
- Lambda関数に対してイベントが通知される
- "/tmp"配下にS3からファイルをダウンロードする
- ファイルの行数が長いと分割する(Amazon SESの一括処理が10000件までなので)
- S3バケットに分割したファイルをアップロードする
- Amazon SESにある"CreateImportJob"のAPIを実行する CreateImportJobのリファレンス
- Amazon SNSを使ってメールで管理者に通知する (トピックに対して通知)
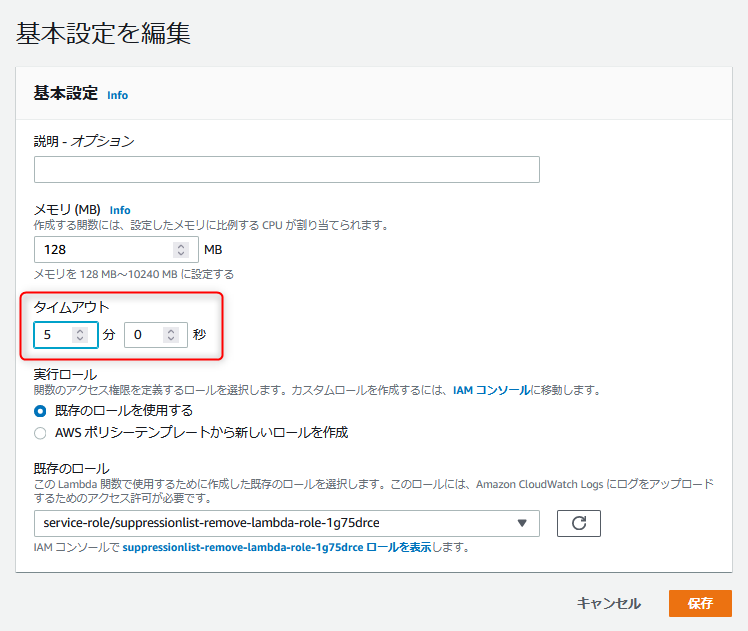
Lambda関数のタイムアウト値を伸ばしておく
標準では、3秒のタイムアウトだが300秒にしておく。
環境変数を設定
環境変数を必須とするので、それぞれ環境変数を定義してください。
| 環境変数名 | 指定する内容 |
|---|---|
| BUCKETNAME | CreateImportJobで使用するS3バケット名 |
| SES_REGION | Amazon SESを稼働させているリージョン名 |
| SNS_REGION | Amazon SNSを稼働させているリージョン名 |
| TOPIC | SNSトピックで使用するARN名 |
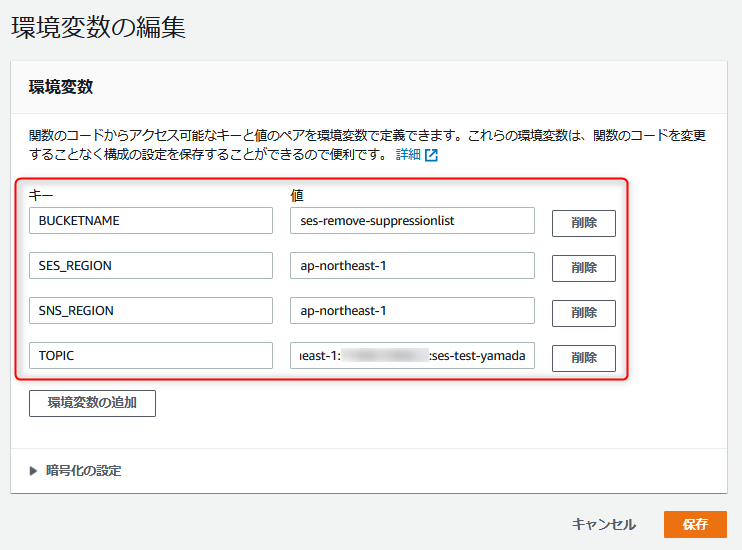

IAMロールにIAMポリシーを割り当て
先に作成したIAMポリシーをLambda作成時に作成されたIAMロールに割り当てます。
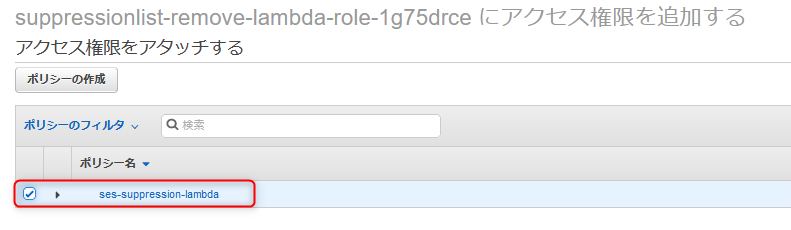
S3のイベントでLambda関数が発火するように割り当て
以前のブログで割り当て方法を紹介しているので、ここでは割愛します。
S3のイベント通知を使用してLambdaで文字コードを変換する
備考
S3にファイルをアップロードしたらLambdaが動作するので、メール通知された。
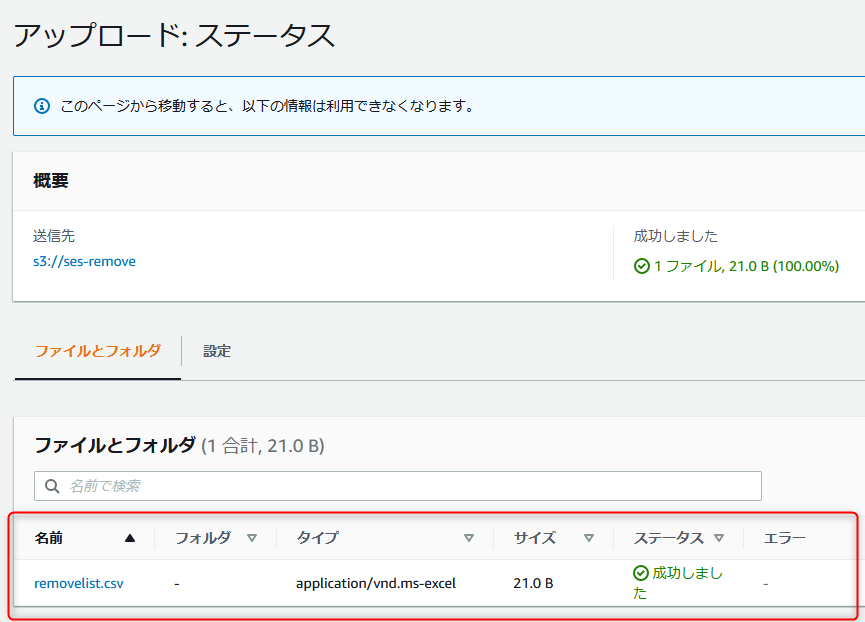

詰まったポイントなど
- Lambdaによって分割されたファイルは、S3上に残る形で構成しております(消したければライフサイクルルールを利用)
- 私の考えが至らなかった訳ですが、複数ファイルを同時にS3へアップロードした際Lambdaが同時刻に2本稼働してしまいS3上でファイルが上書きされてしまいました
- 対策としては、UUID4を使って同時実行されても極力被らない構成としました
- 改行コードがLF(\n)でないとジョブがセットされてもサプレッションリストから解除されずはまりました
ご注意
お客様環境での動作を保証したものではございませんので、参考にされる際は十分な検証を行っていただきますようお願いいたします。

プロフィール
テクニカルサポートは卒業して、フロントサイドでお客様環境の構築をさせていただいております。
たまに、テクニカルサポートでご対応させていただくことがあるかもしれませんが、その際はよろしくお願いいたします。
インフラ系のエンジニアですが、時々休日プログラマー(Python、PHP)をやっております。