
目次
はじめに
みなさん、こんにちは。
アドベントカレンダー企画、12月22日担当の牛山です。
本日の記事では、S3、Athena、QuickSightを使用して、国や民間企業が提供している高等学校数の統計データを使用し、QuickSight上で視覚化してみたいと思います。
前置き
登場するAWSコンポーネントとして、Amazon S3、Amazon Athena、Amazon QuickSightとなります。

-
各サービスの役割
-
Amazon S3
視覚化する統計データを保存するストレージです。 -
Amazon Athena
統計データにもとづくテーブルを作成し、Amazon S3に保存してある統計データをデータソースとして入れ込みます。 -
Amazon QuickSight
Amazon Athenaをデータソースとして、データベースを取り込みます。
-
統計データの準備
今回、1948年 ~ 年度の高等学校数統計データを利用させていただき、Amazon QuickSight上で視覚化していきますので以下リンク先からCSVファイルをダウンロードします。
※リンク先にある「一括ダウンロード」を押すことでCSVファイルを入手できます。
入手した統計データは不要なデータが含まれますので加工します。
UTF8へ文字コードを変換
nkfコマンドでcsvファイルの文字コードを変換します。
nkf -w --overwrite TimeSeriesResult_20231218012732596.csv
※「TimeSeriesResult_」以降はそれぞれ読み替えてください。
細かな不要データを除く
以下コマンドで細かい部分を加工して、data.csvに書き込みます。
cat TimeSeriesResult_20231218012732596.csv | sed 's/"//g' | awk '{print $1, $2, $3, $4}' | sed -r 's/(年|速報)//g' | cut -d "," -f 1,2,3,4 > data.csv
S3へ統計データをアップロード
AWSマネージメントコンソールからS3サービス画面へ、いき、適当なバケットを作成します。
今回は「s3://data-lake-20231218/high_schools/data.csv」のようにしました。
※先ほど加工した統計データをアップロードするようにしてください。
Amazon Athenaへテーブルを作成
AWSマネージメントコンソールから「Amazon Athena」のサービスへ、いき「クエリエディタ」を選択します。
その後、設定タブをクリックします。
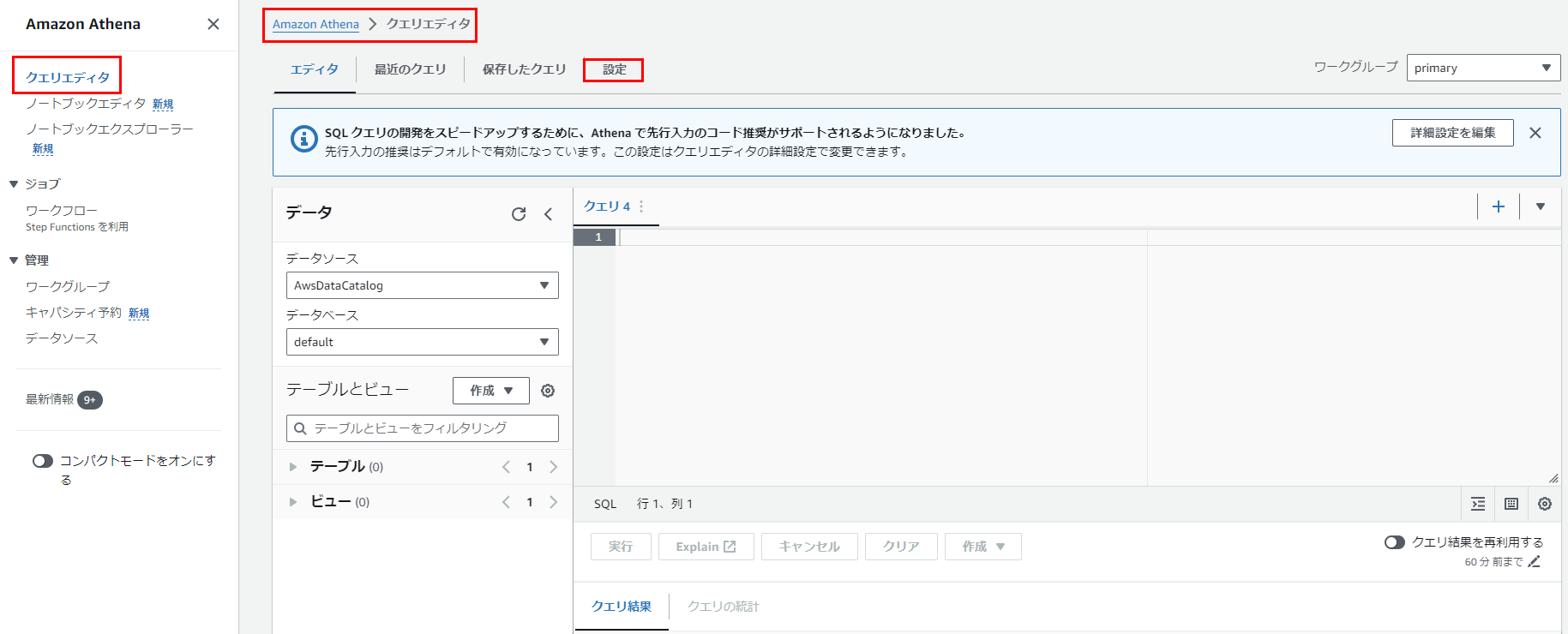
「クエリの結果の場所と暗号化」項目よりそれぞれ下記のように設定します。
-
クエリの結果の場所
s3://data-lake-20231218/high_schools/
-
クエリ結果を暗号化
- 無効
-
予期されるバケット所有者
- AWSアカウントID
-
バケット所有者にクエリ結果に対する完全なコントロールを割り当てる
- 有効
テーブル作成
「エディタ」タブで以下、クエリを実行します。
※デーブルとビュー項目、作成プルダウンメニューより「S3 バケットデータ」から同様のクエリを発行できます。
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`high_schools` (
`year` int,
`region_code` int,
`region_name` string,
`high_school_number` int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://data-lake-20231218/high_schools/'
TBLPROPERTIES ('classification' = 'csv');※LOCATION箇所は、各自の環境に合わせてください。
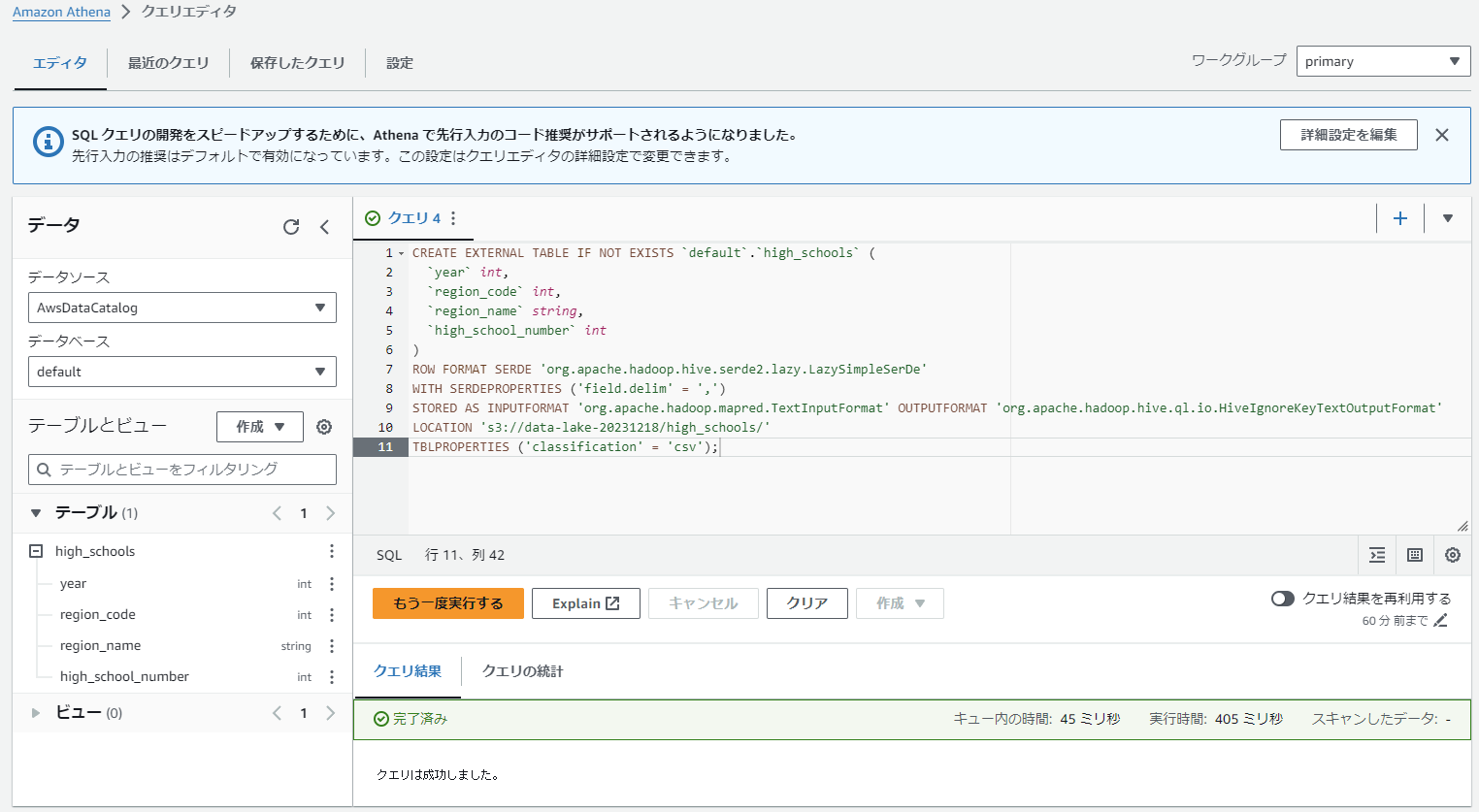
SQLを実行すると上記画像の通り、テーブル項目にテーブルが出来上がります。
今度は作成したテーブルに対して、統計データを以下コマンドで入れ込んでいきます。
SELECT *
FROM default.high_schools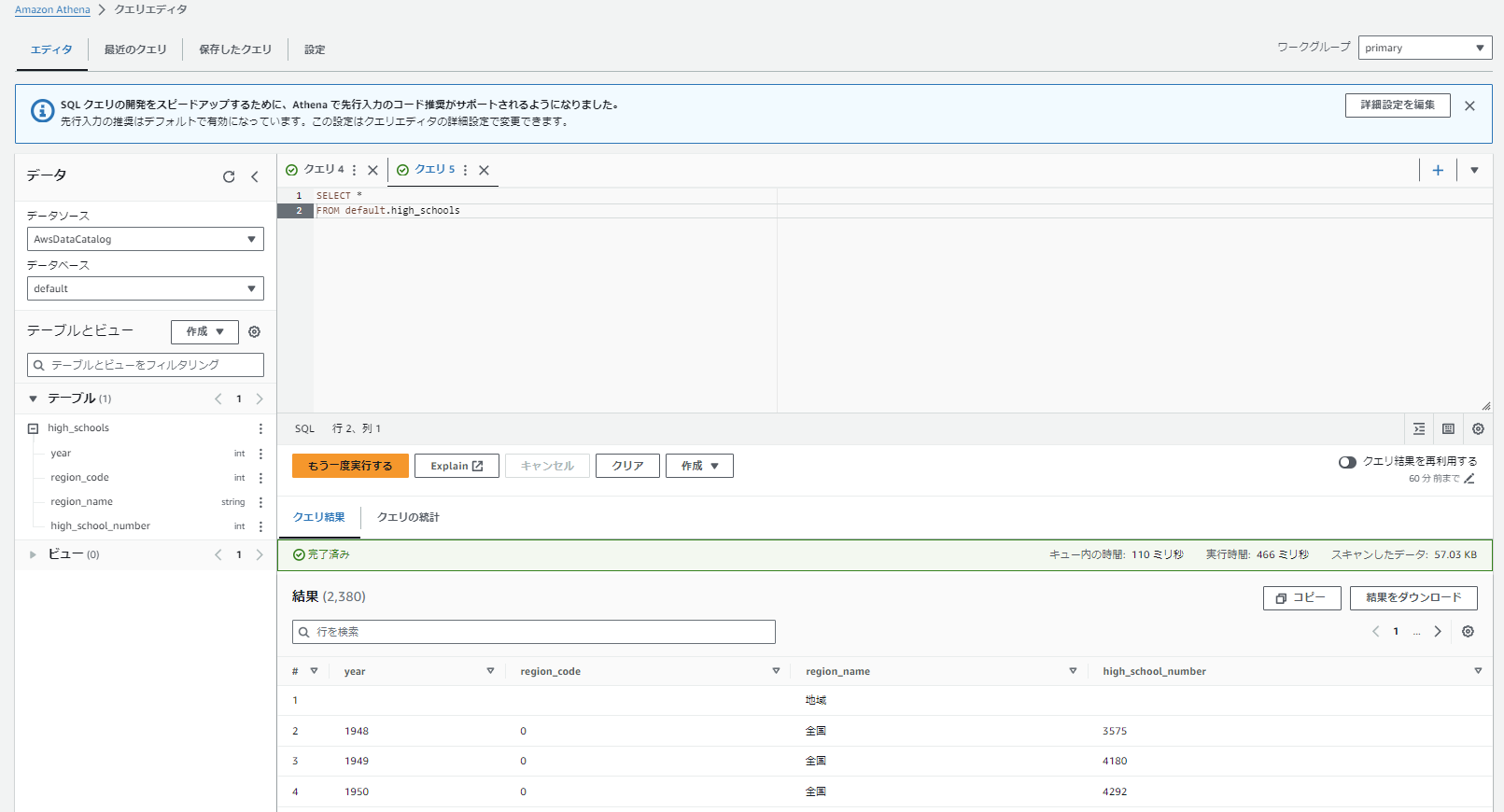
取込み結果として2380件のデータが取り込まれ、取り込まれたデータについても想定したものになっていそうです。
Amazon QuickSightで視覚化
AWSマネージメントコンソールのより「Amazon QuickSight」サービス画面にいきます。
初回はセットアップがあるので初めて使われる方は、適宜初期設定をおこなってください。
権限設定
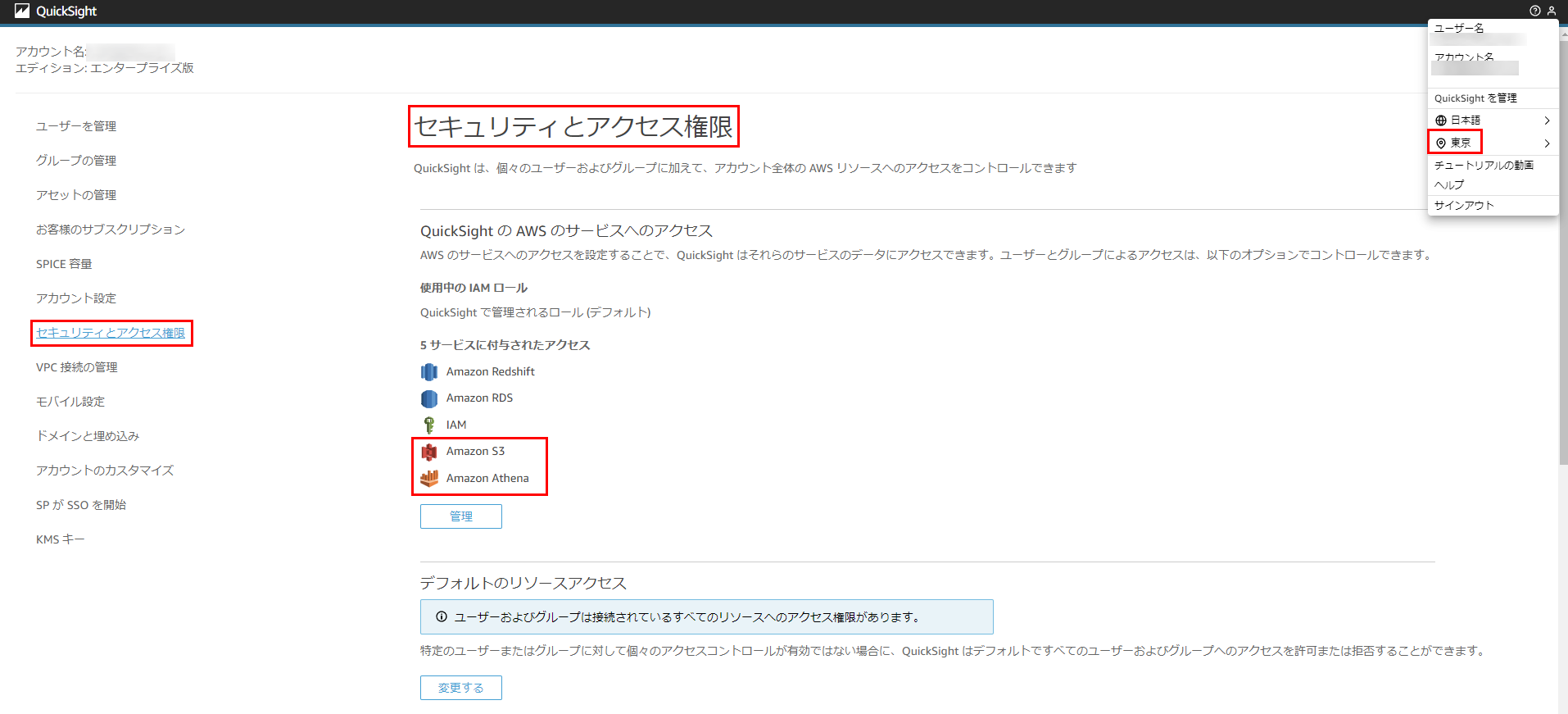
ここでは要点のみお伝えします。
Amazon QuickSightのリージョンが東京になっていることを確認し、セキュリティとアクセス権限
より、Amazon S3とAmazon Athenaに付与されたアクセスがあることを確認します。
※ない場合、管理から設定をおこなってください。
作成したS3バケットへのアクセスが有効になっていることも確認します。
データセット作成
「新しいデータセット」をクリックし、「Athena」を選択します。
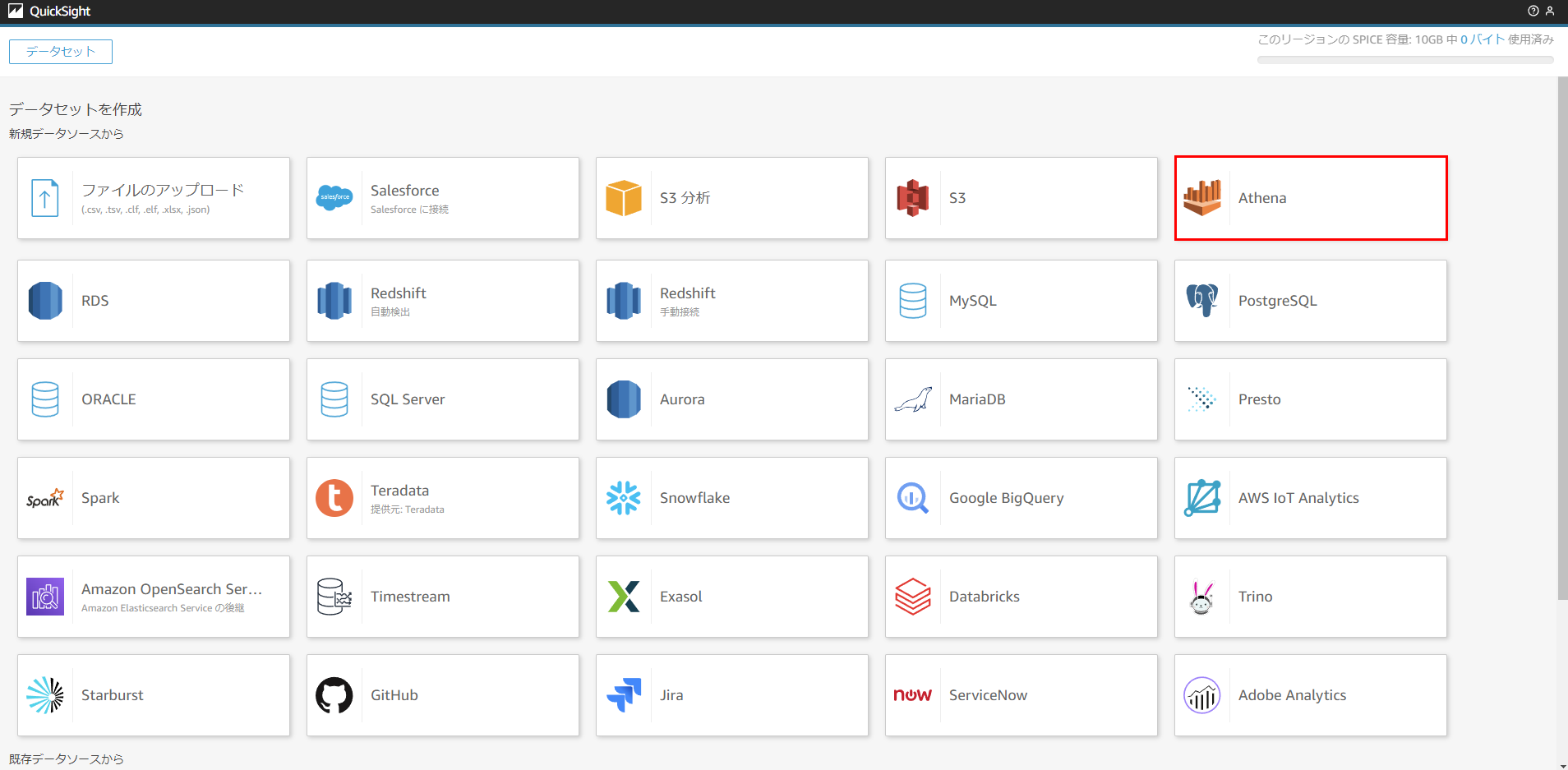
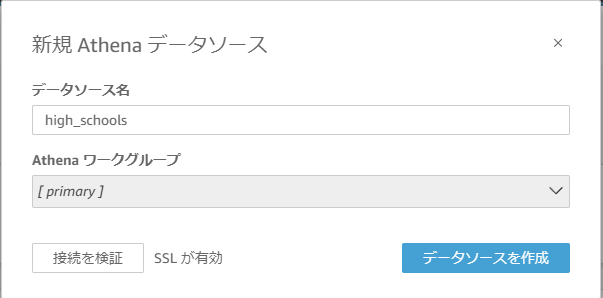
「新規 Athena データソース」に遷移するので「データソース名」を「high_schools」とし、「データソース作成」を押します。
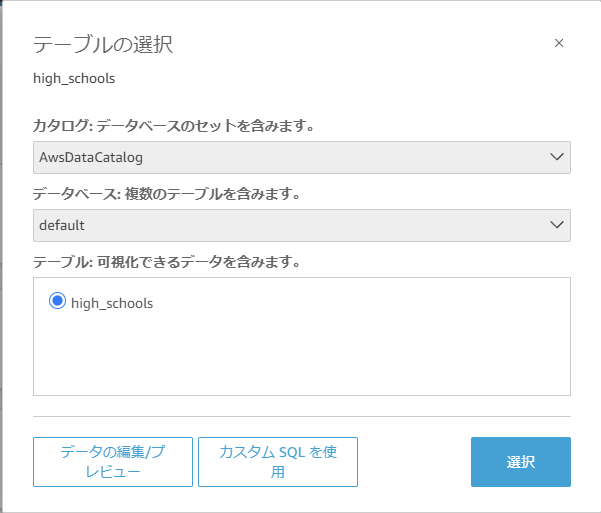
「テーブルの選択」に遷移するので「テーブル: 可視化できるデータを含みます。」項目で「high_schools」にチェックを入れ、「選択」をクリックします。
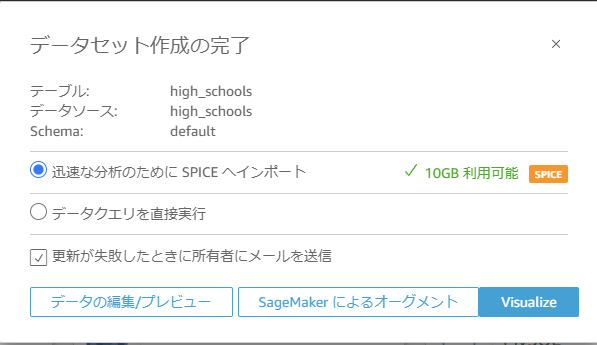
「データセット作成の完了」に遷移するので何も変更せず「Visualize」をクリックします。
「Visualize」クリック後、グラフ作成画面に自動的に遷移します。
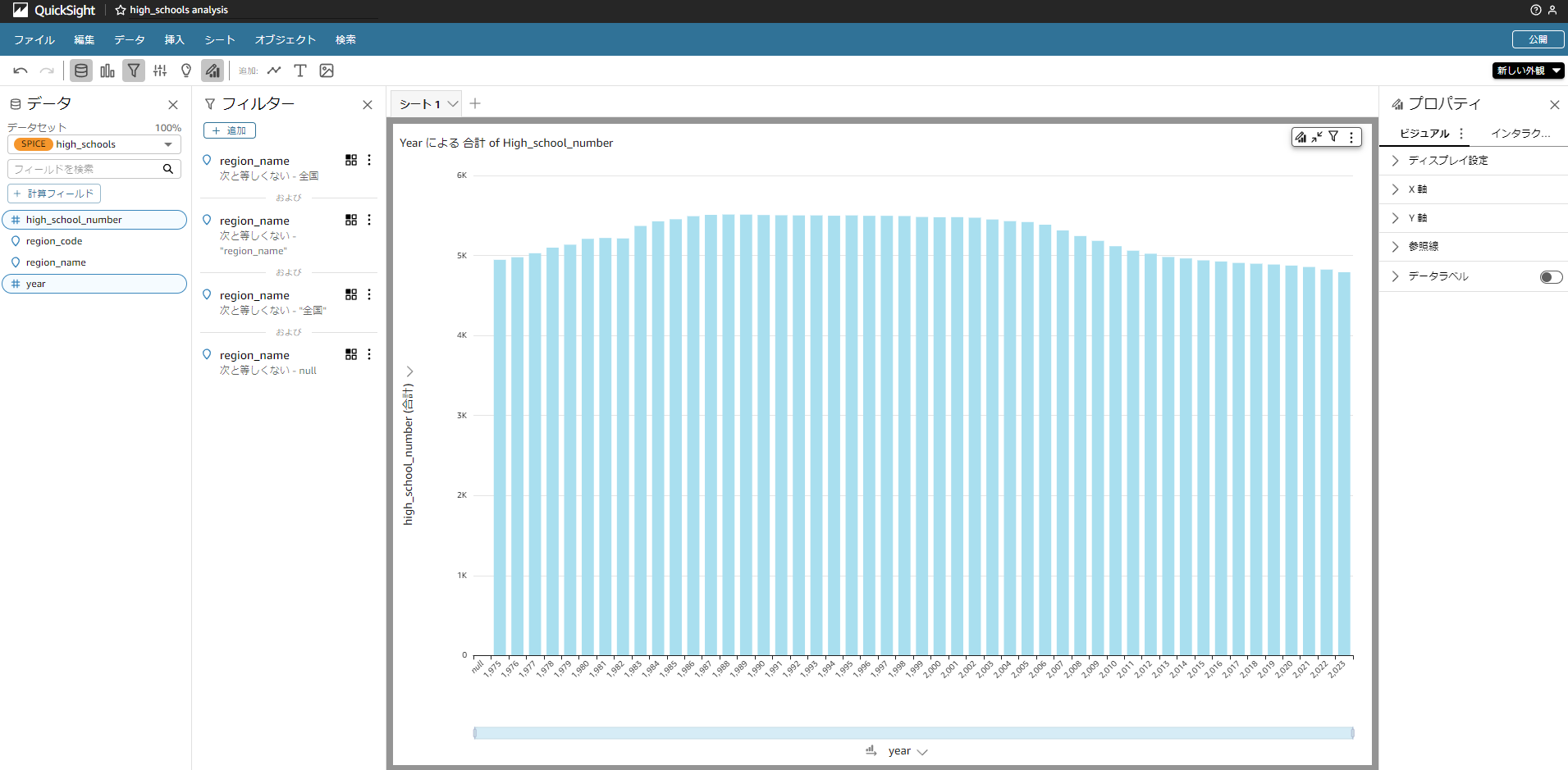
ビジュアルタイプとして「垂直棒グラフ」を選びます。
X軸に「year」を指定し、値に「high_school_number」を指定します。
「high_school_number」の三点リーダをクリックし集計を「合計」へ変更します。
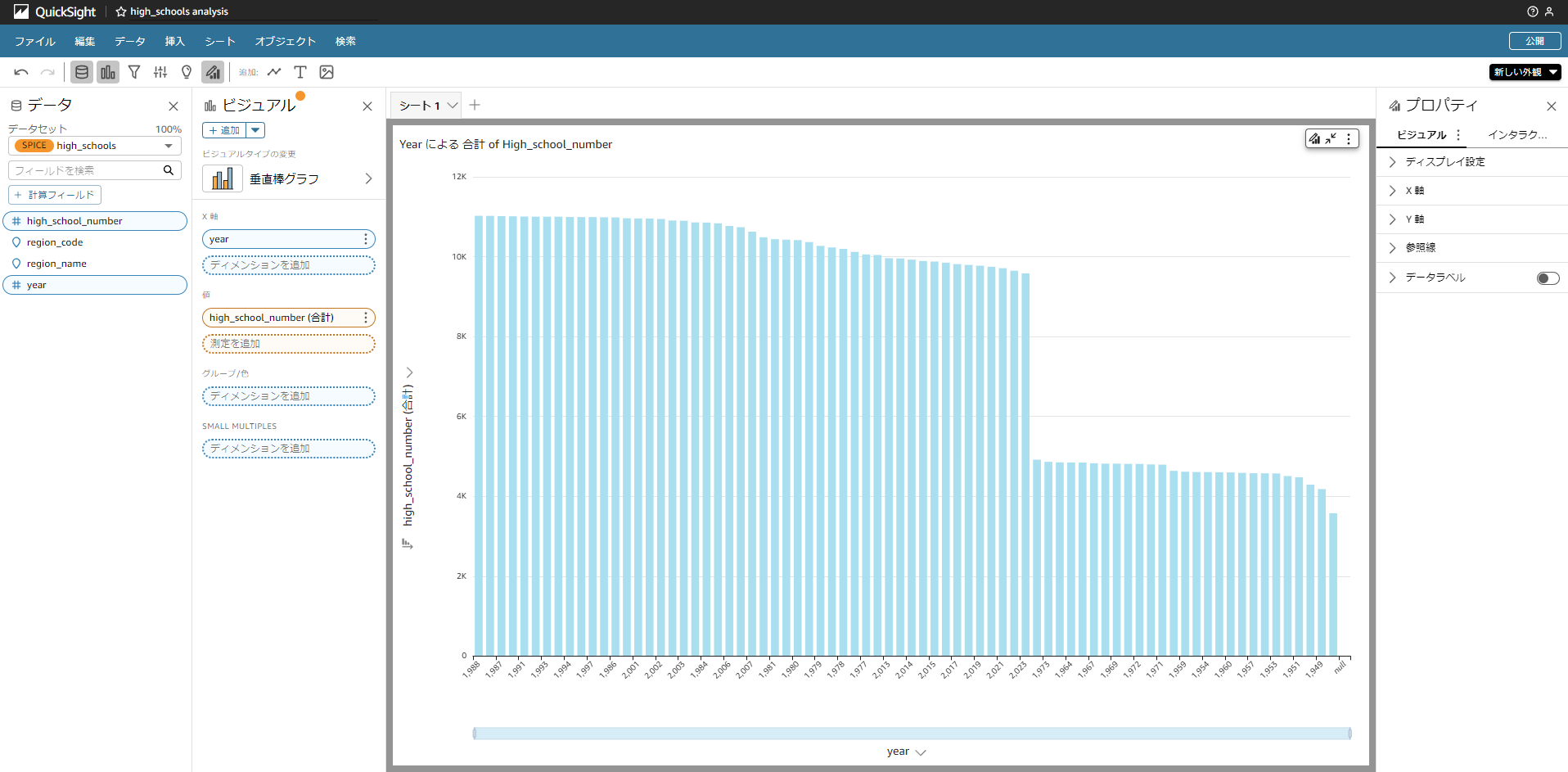
この状態ではノイズがあり、グラフが綺麗に見えないので以下画像のようにフィルター
を活用し、データを除外したりすることでもっともらしいグラフになります。
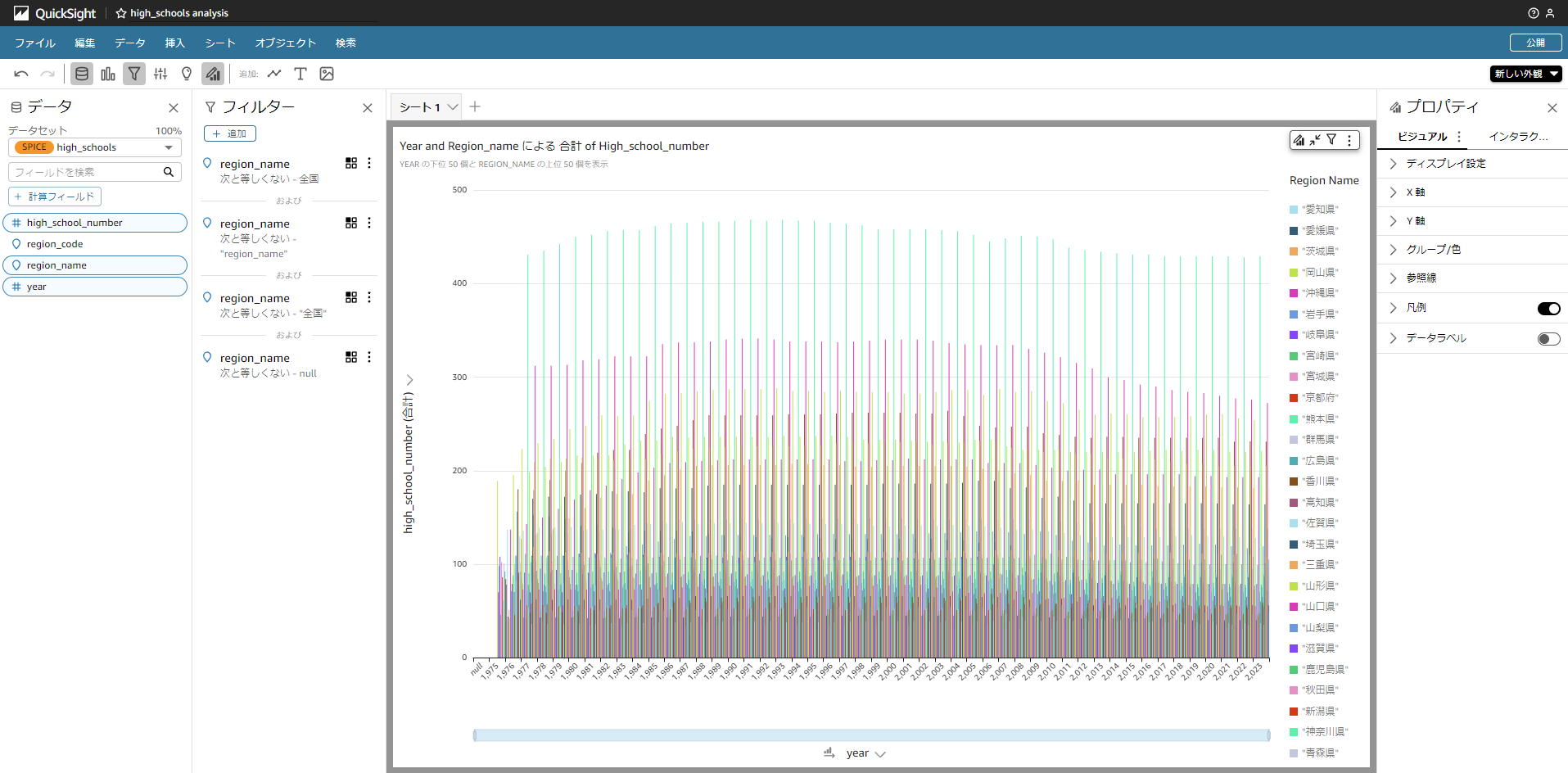
また、region_nameを選択すると都道府県別の高等学校数を確認できたりします。
パラメータを変更することで簡単にグラフを変更できるので是非、みなさんも
一度は試してみても良いかもしれません。
おわりに
統計データの準備 ~ データの分析、視覚化までおこなってみました。
簡単にグラフに表現できることがわかりました。
AWSで分析してみたい!といった方のご参考になれば幸いです。

プロフィール
AWSの設計・構築をメインにおこなっています。
運用・保守をおこなう部署におりましたが、最近、アーキテクト課に異動しました。
日々精進しております。