
こんにちは!
弊社ディーネットがAWSのアドバンストコンサルティングパートナー昇格の記念として実施しているAWSサービスしりとりリレー9日目担当、森屋です。
リレーも折り返し地点を過ぎ、後半戦の開始です!
本日は、「Systems Manager」からバトンを受け、Rから始まる「Redshift」を扱っていきます。
目次
はじめに
さて本題前に突然ですが、私の属する部署では、SaaSと独自システムの掛け合わせでワークログの可視化をやっています。
この可視化により得られるメリットはたくさんあり、
- 個人レベルで定期的に分析し、自身の業務バランスなどを見直す
- チームレベルで定期的に分析し、意思決定の材料とする
- 「今なにやってます」という情報をチームで共有しあう
- 業務ごとの工数試算を出しやすくする
と様々あり非常にオススメです。
しかしこのシステム、実は Elasticsearch + Kibana でやっており、フルAWSじゃない状態なんですよね…。
今回、ブログリレーのおかげでRedshiftを触る機会を得たので、Redshift + QuickSightで同じようなことをしたらどうなんだろう?と思い、分析の部分を試してみました。
本記事でのご紹介内容について
まず、Redshift + QuickSightについて、ある程度触れる方向けの内容となっています。
といっても、私もほぼ初見状態から数時間触っただけなので、すぐに追いつけるかと思います。
(QuickSight、というかKibanaはけっこう触ってきているので、可視化部分は少しアドバンストな内容になるかもしれませんが…)
本記事の執筆にあたり、多大に参考になったAWSハンズオンセミナーがありますので、まずご紹介します。
https://pages.awscloud.com/JAPAN-event-OE-Hands-on-for-Beginners-Analytics-2021-reg-event.html?trk=aws_introduction_page
※基本的に無料枠で試せます
そして、このハンズオンで作った環境上で、ワークログを流し込み、可視化して遊んでいきたいと思います。
ワークログの取得は、言わずと知れたタイムトラッキングツールSaaS『Toggl』を使用します。
他にも、エクスポート機能のあるツールをご利用でしたら、参考になることがあるかもしれません。
やってみよう!
手順の概要
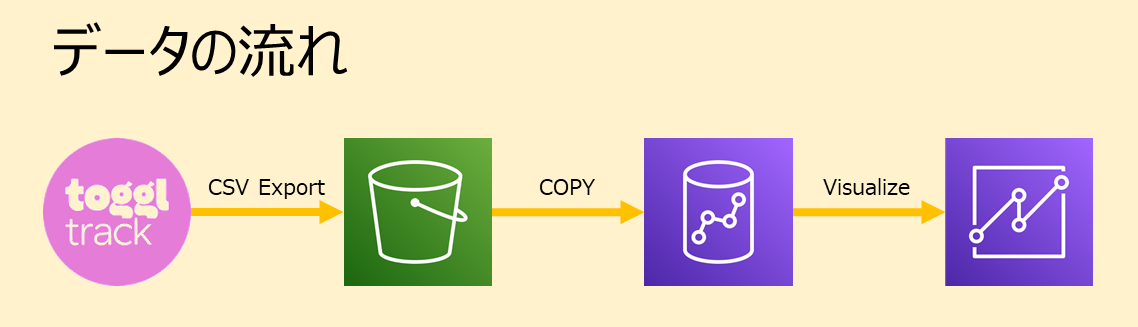
①TogglのデータをCSVでエクスポートします
②CSVデータをS3にアップします。
③CSVデータをRedshiftからCOPYコマンドで読み込みます。
④RedshiftとQuickSightを接続します
⑤QuickSightで可視化します
ハンズオン内で、
- 「AmazonS3ReadOnlyAccess」をアタッチした、Redshift用IAMロール
- QuickSight→Redshiftの接続を許可する、Redshift用セキュリティグループ
- Redshift→QuickSightの接続を許可する、QuickSight用セキュリティグループ
をそれぞれセットしているので、ハンズオンを実施されていない方はご注意ください。
①Togglデータのエクスポート
Togglは無料ユーザでもCSV出力に対応しています。これをRedshiftに流し込むわけです。
ハンズオンでもCSVを扱ったので、応用編としてもお楽しみください。
というわけで、コツコツ記録してきた2021年の約1000時間のワークログを、エクスポートしていきます。
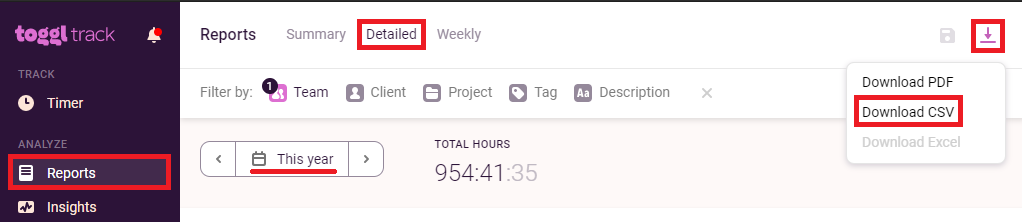
[Reports]のページにて、期間を[This year]とし、[Detailed]のタブに移ります。
今回は私一人の結果を集計しようと思うので、チームメンバーを絞っていますが、ここはお好きにどうぞ。
そして地面に一直進なアイコンのボタンを押下し、[Download CSV]でお目当てのデータをダウンロードしましょう。
②S3へのアップロード
特段変わったことはしません。適当な名前でアップロードしましょう。
③Redshiftへのインポート
Redshiftの[クエリエディタ]に移動します。
データベースに接続したら、画像下のクエリを実行し、Run。
今回使うテーブルを作成します。

create table worklog(
username varchar(1000),
email varchar(1000),
client varchar(1000),
project varchar(1000),
task varchar(1000),
description varchar(1000),
billable varchar(1000),
startdate char(10),
starttime char(8),
enddate char(10),
endtime char(8),
duration char(8),
tags varchar(1000),
amount varchar(1000));※varcharの文字数枠は雑に1000と設定してますが、環境に合わせて適宜変えてください
続いて、テーブルにデータをインポートしましょう。
ハンズオン同様、S3ファイルに上げたCSVを、COPYクエリによってインポートします。
COPY worklog from 's3://{バケット名}/{アップロードしたCSVファイル名}' iam_role 'arn:aws:iam::{Redshift用IAMロールのARN}' delimiter ',' csv ignoreheader as 1 ;COPYコマンドで割と引っかかってしまったので、それぞれのオプションについて紹介しておきます。
-
delimiter ','
区切り文字の指定です。
ハンズオンではパイプ(|)区切りでしたが、TogglのCSVはカンマ(,)区切りで出てくるので、カンマを指定しています。 -
csv
デリミタをカンマにしていることから、Togglの入力内容にカンマが含まれている場合に、思わぬカラムにデータが入ったりします。
そういったものはTogglから出てくる時点でダブルクォーテーション(")で囲われており、こういうCSVデータはcsvオプションを渡すことで、Redshiftがうまいこと判別してくれます。 -
ignoreheader as 1
CSVの1行目に入る項目名を、無視させています。
流し込むデータによってエラーは異なってくると思うので、エラーが出た場合は以下のコマンドでエラー内容を確認しましょう。
select * from stl_load_errors;
COPYに成功したら、行数をカウントし、全部流し込まれているか見てみましょう。
select count(*) from worklog;
→私は1922件と出ました。CSVと同じ行数です。
④RedshiftとQuickSightの接続
さて、いよいよ可視化フェーズです。(本題はRedshiftやろがい)
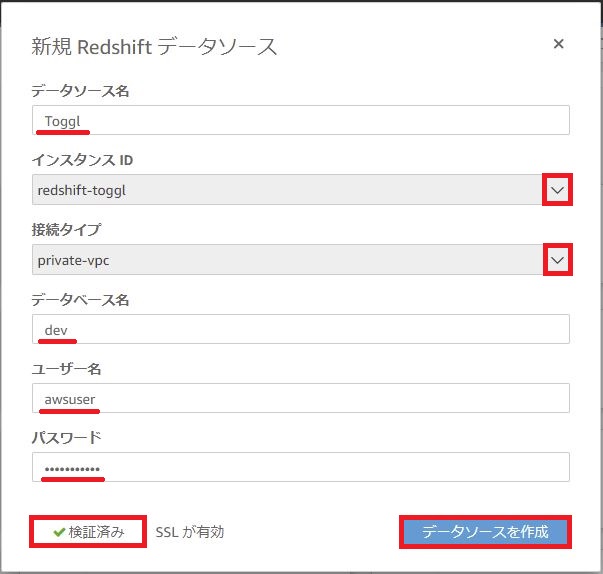
QuickSightにログインしたら、[データセット]に移動し、[新しいデータセット]をクリックします。
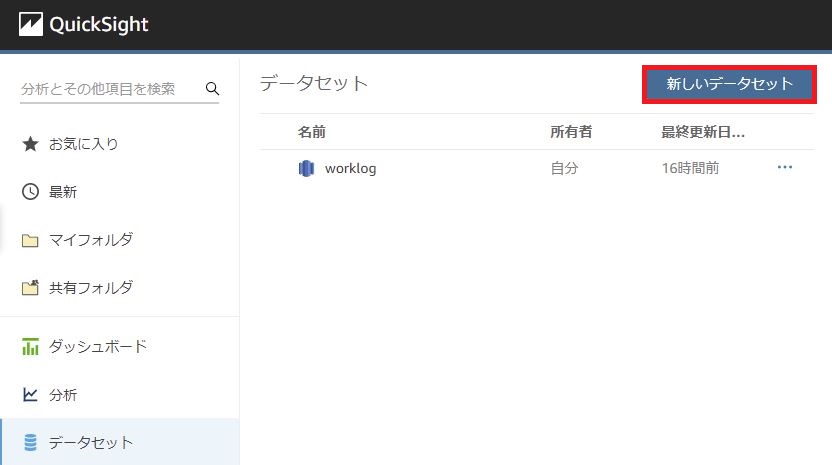
データソースは[Redshift(自動検出)]を選択し、Redshiftのデータベースへの接続を検証し、問題なければ[データソースの作成]をクリックします。
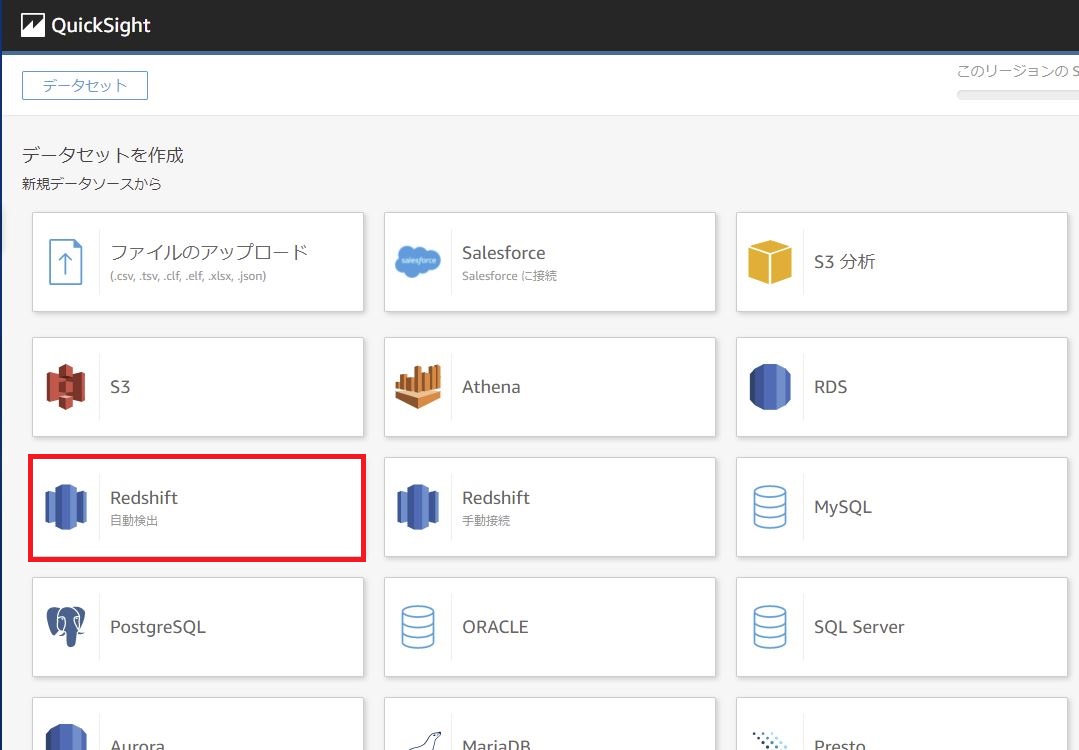
続いて、テーブルは先ほど作成した[worklog]を選択し、[データの編集/プレビュー]をクリックします。
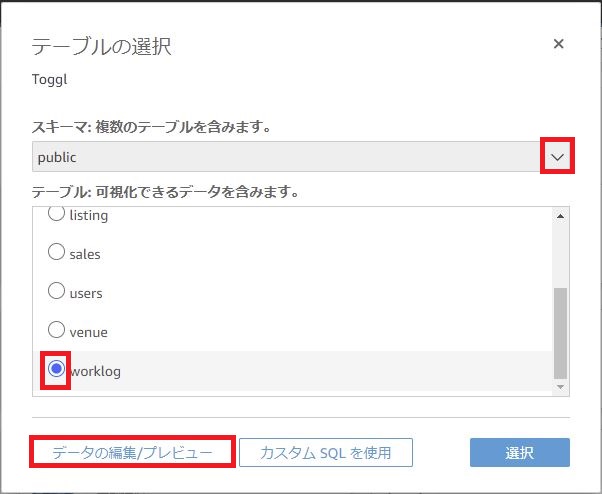
各データセットのリレーション等を設定する画面に移りますが、今回はデータセット一つで完結してます。
しかし、Togglエクスポートで得られるデータのままでは少し不足があるので、データに手入れをしていきます。
[計算フィールドを追加]をクリックし、それぞれ画像下の通り項目を作成していきましょう。
関数は、以下のページが参考になります。
https://docs.aws.amazon.com/ja_jp/quicksight/latest/user/functions.html
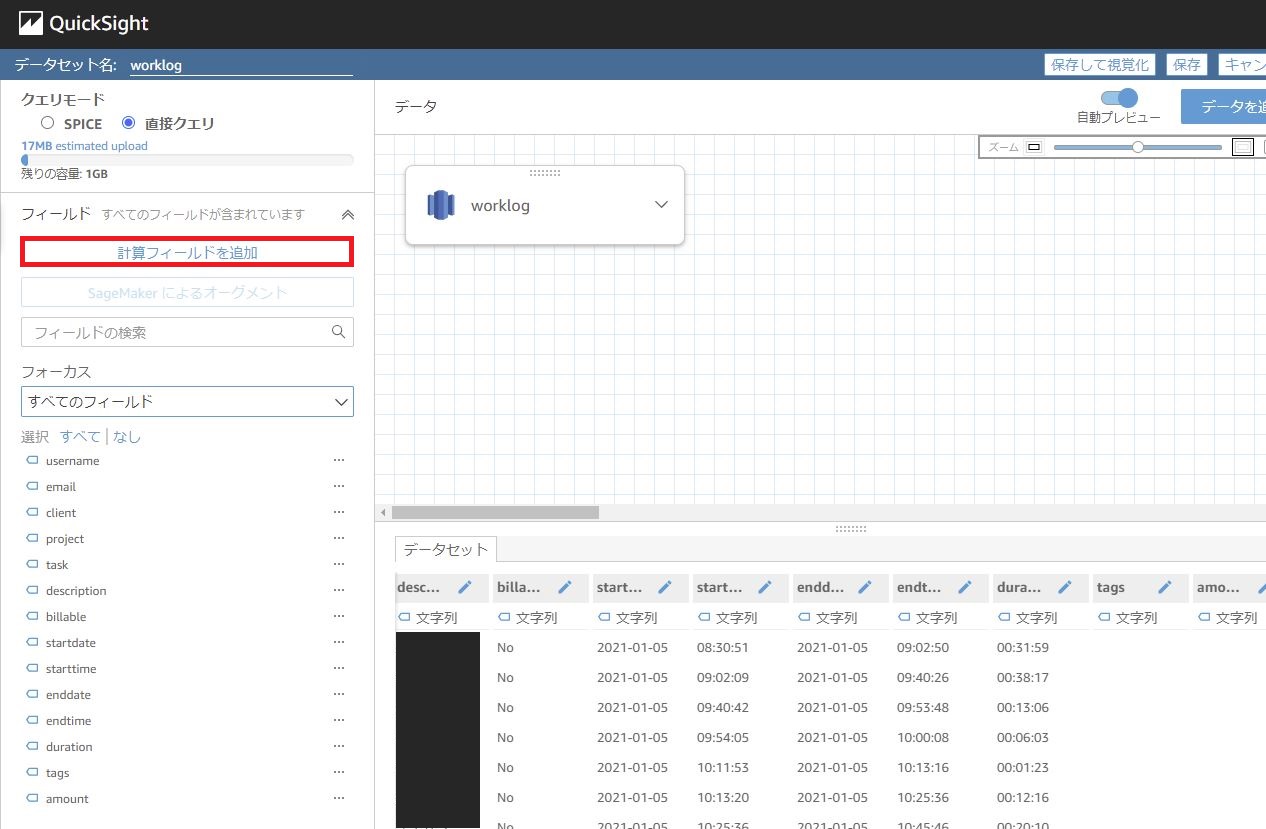
-
Start
parseDate(concat({startdate},' ',{starttime}), "yyyy-MM-dd HH:mm:ss")
→QuickSightはTIME型を扱えないようだったので、文字列同士をくっつけて、DATE型にしています。 -
End
parseDate(concat({enddate},' ',{endtime}), "yyyy-MM-dd HH:mm:ss")
→Startと同じく -
Time
decimalToInt((parseInt(substring({duration},1,2)) * 3600 + parseInt(substring({duration},4,2)) * 60 + parseInt(substring({duration},7,2))) / 3600)
→DurationがHH:mm:ssで出てきて扱いづらかったため、「01:30:00」だったら「1.5(h)」という風に変換させています。
作成すると、それぞれの項目が表示され、またプレビューでも反映結果が確認できるはずです。
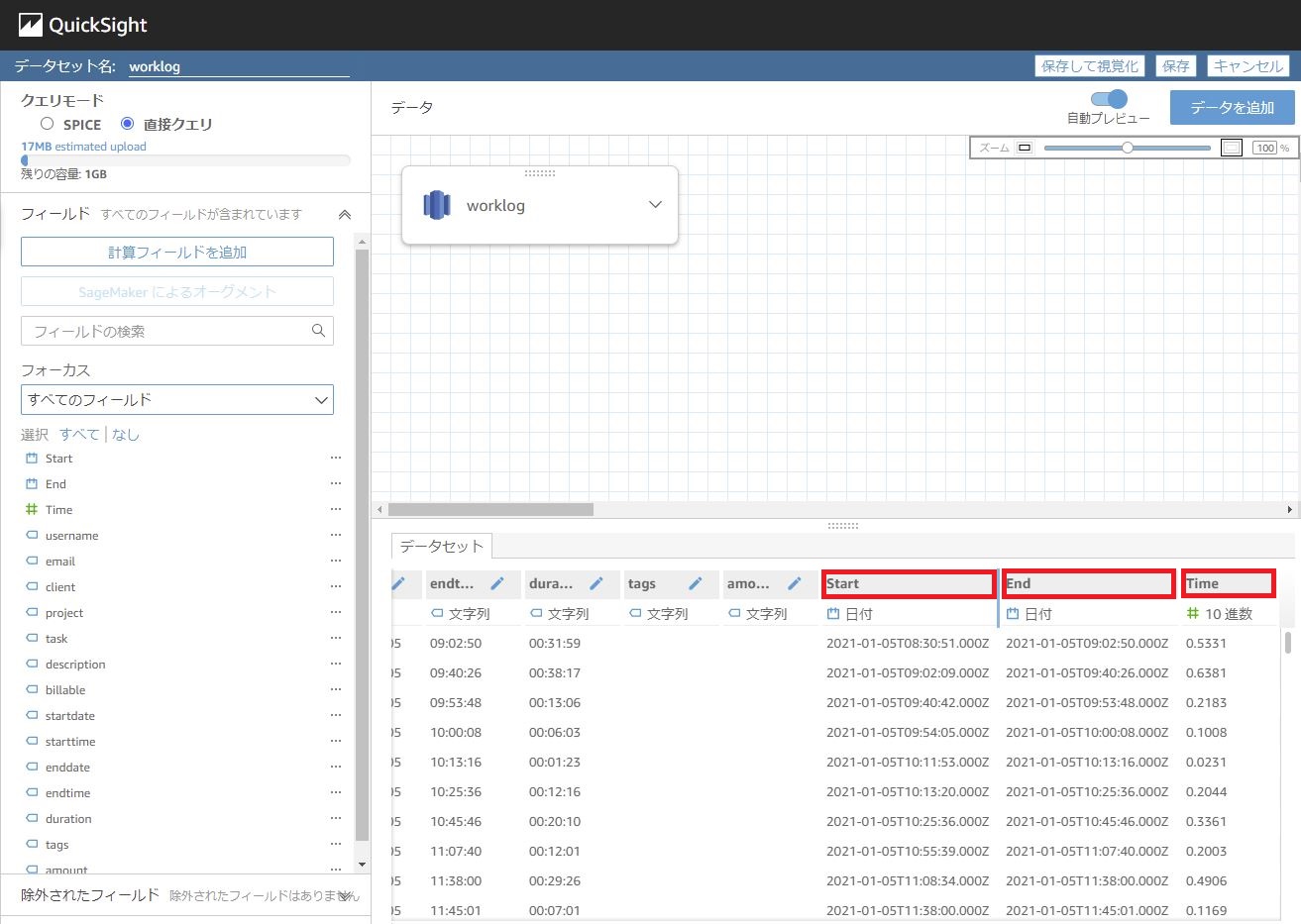
計算フィールドの追加がうまくいったら、[保存して視覚化]をクリックしましょう。
⑤QuickSightでの可視化
あとは、それぞれのデータを視覚化していくだけです。
フィールドを選択すると、自動判別でグラフを作成してくれますが、思わぬグラフになる時もあり、またそれが使える内容の時もあったりして楽しいですね。
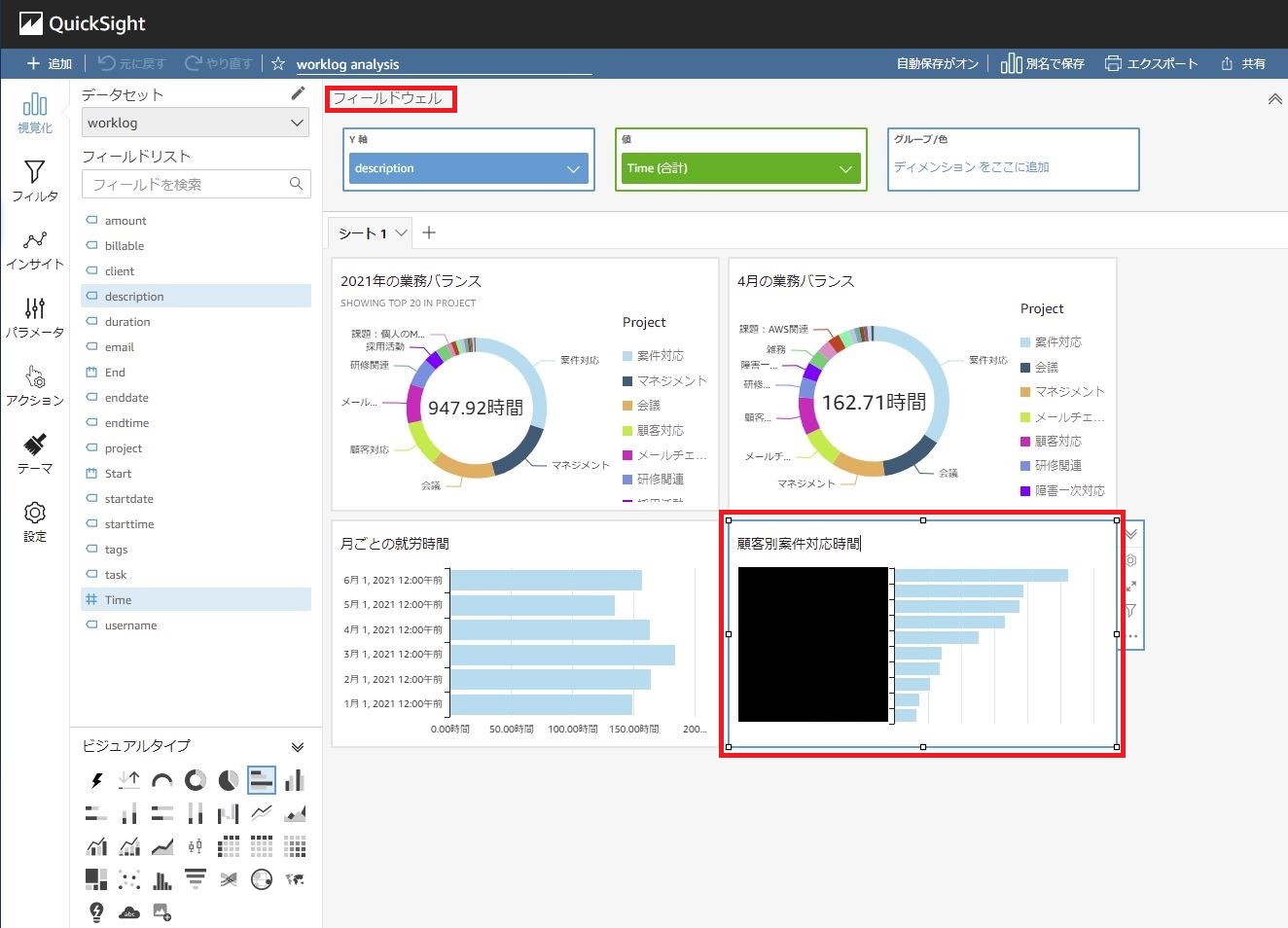
しかし、[フィールドウェル]で作っていくのが、なんだかんだ一番楽でした。
参考までに一つだけ画像を載せておきますので、フィルタ等も駆使し、お好みのビジュアルを作ってみてください!
おわりに
いくつかクエリや関数は触りましたが、がっつりコードを書いたり、難しい演算処理など気にすることなく、可視化できちゃいました。
Togglにもレポート機能がありますが、そこで分析できないものを作ったり、マイダッシュボードを作れたり、より便利に使い倒せるのではないでしょうか。
今回は私一人のデータを使いましたが、[email]のフィールドを使えば各メンバー毎の可視化なんかもできます。
そして、手動でCSVをアップロードするのではなく、それぞれの処理を自動化すれば、継続的に分析を行うことができそうです。
まだまだリレーは続きますが、私からは以上です。お読みくださり、ありがとうございました。
ではまた!

テクニカルサポートとして、日々お客様の悩み事解決を支援しております。
スーパーエンジニアになるべく、日々、自宅でのウェイトトレーニングに励んでいます。
LINK
クラウドベリージャム:プロフィールページ