
目次
はじめに
こんにちは、お久しぶりです。甫立です。
今回はいつもインフラ運用・保守関連を担当しているので、気になっていたOpenSearchの機能について触っていこうと思います。
Webサービスの運用において、トラフィックの急激な変化(スパイクやドロップ)は、システム障害やDDoS攻撃、
あるいはキャンペーンによるアクセス集中など、何らかの異常事態を示唆する重要なサインです。
従来、こうした監視は閾値ベース(特定のログが「3」回出力されたら検知など)のアラートで行われることが一般的でした。
しかし、閾値設定は「平日と休日」「昼と夜」といった周期性を考慮するのが難しく、誤検知や検知漏れの原因となりがちです。
そこで活用したいのが、OpenSearchのAnomaly Detection(異常検知)機能です。機械学習を
用いてデータの「通常の状態」を学習し、そこから逸脱した振る舞いをリアルタイムに検知することができます。
本記事では、OpenSearch Dashboardsを使って、アクセスログの出力回数の異常を検知する設定手順を紹介します。
前提条件
- OpenSearch および OpenSearch Dashboards が構築済みであること
- Webサーバーのアクセスログなどが OpenSearch にインデックスされていること(例:
access-logs-*)
データの準備
まず、監視対象となるデータが OpenSearch に入っていることを確認します。今回は、HTTPステータスコードやリクエスト数を含むアクセスログを想定します。
Detector(検知器)の作成
OpenSearch Dashboards の左メニュー → OpenSearch Plugins → Anomaly Detection
"Create detector" をクリックして、以下の項目を設定します。
Define detector
ここでは検知器の基本設定を行います。
| 項目 | 説明 |
|---|---|
| Name | わかりやすい名前を入力します(例: web-logs-anomaly-detector) |
| Description | 説明を入力します |
| Clusters | 今のクラスター名が入力されていることを確認します |
| Index | 監視対象のインデックスパターンを選択します(例: access-logs-*) |
| Data filter | 必要に応じてフィルタリングします(例: 特定のホストのみ監視したい場合など)。今回は全データを対象とするため設定しません。 |
| Timestamp field | 時系列分析に使用するタイムスタンプフィールドを選択します(例: @timestamp) |
| Custom result index | 必要に応じて検知結果を保存するインデックスを選択します。今回は保存しないのでオフ |
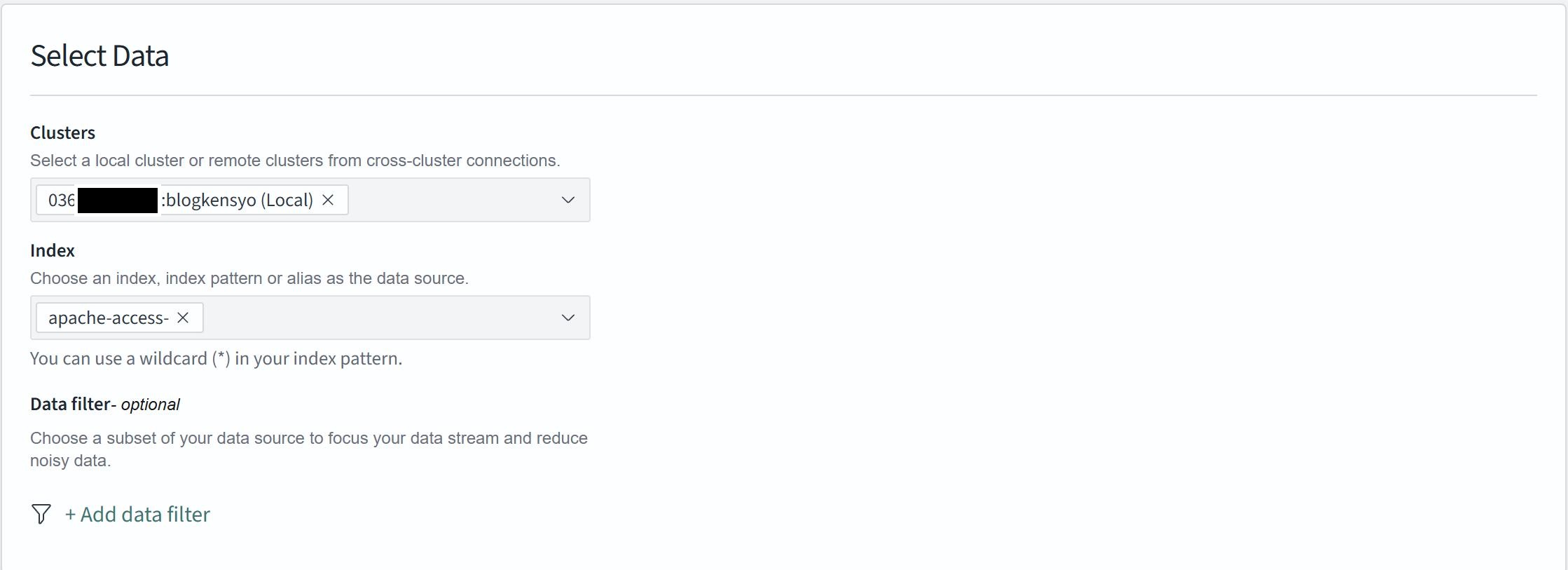
設定したら"Next"をクリックします。
Configure model
ここでは検知器のモデル設定を行います。
Model(モデル)とは、正常な状態と異常な状態を判断するためのアルゴリズムを定義するものです。
Feature(フィーチャー)とは、異常を判定する指標を定義するものです。
簡単に言えば、検知器が異常かどうかをどこで判断するかを設定します。
| 項目 | 説明 |
|---|---|
| Feature name | わかりやすい名前を入力します。(例: total-request-count) |
| Find anomalies based on | 異常を検知する対象を選択します。今回は Field value を選択します。 |
| Aggregation method | 集計方法を選択します。今回は count() を選択します。 |
| Field | 集計対象のフィールドを選択します。今回は @timestamp を選択します。 |
| Anomaly criteria | 異常を検知する基準を選択します。今回は Deviation in any direction (default) を選択します。 |
| interval | データを集計する間隔を設定します。リアルタイム性を重視するなら 1 minute や 5 minutes が一般的です。 |
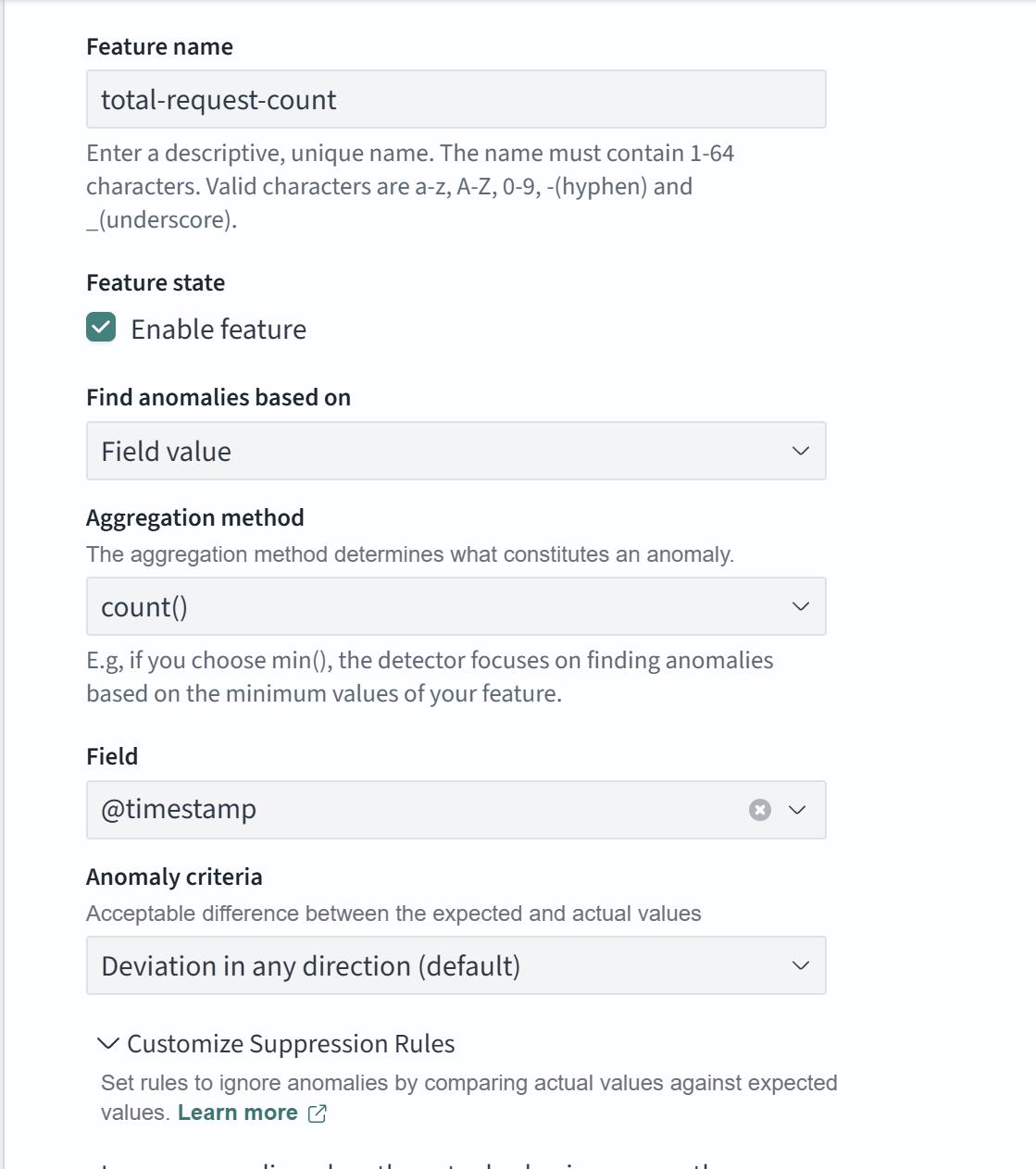
その他は変更せず"Next"をクリックします。
Set up detector jobs
ここでは検知器のジョブ設定を行います。
| 項目 | 説明 |
|---|---|
| Real-time detection | リアルタイムで異常検知を有効にするかを選択します。今回は オン にします。 |
| Historical analysis detection | 過去のデータを分析して異常を検知するかを選択します。今回は オフ にします。 |
設定したら"Next"をクリックします。
Review and create
設定内容を確認して問題なければ、"Create Detector" をクリックして Detector を作成します。
監視と可視化
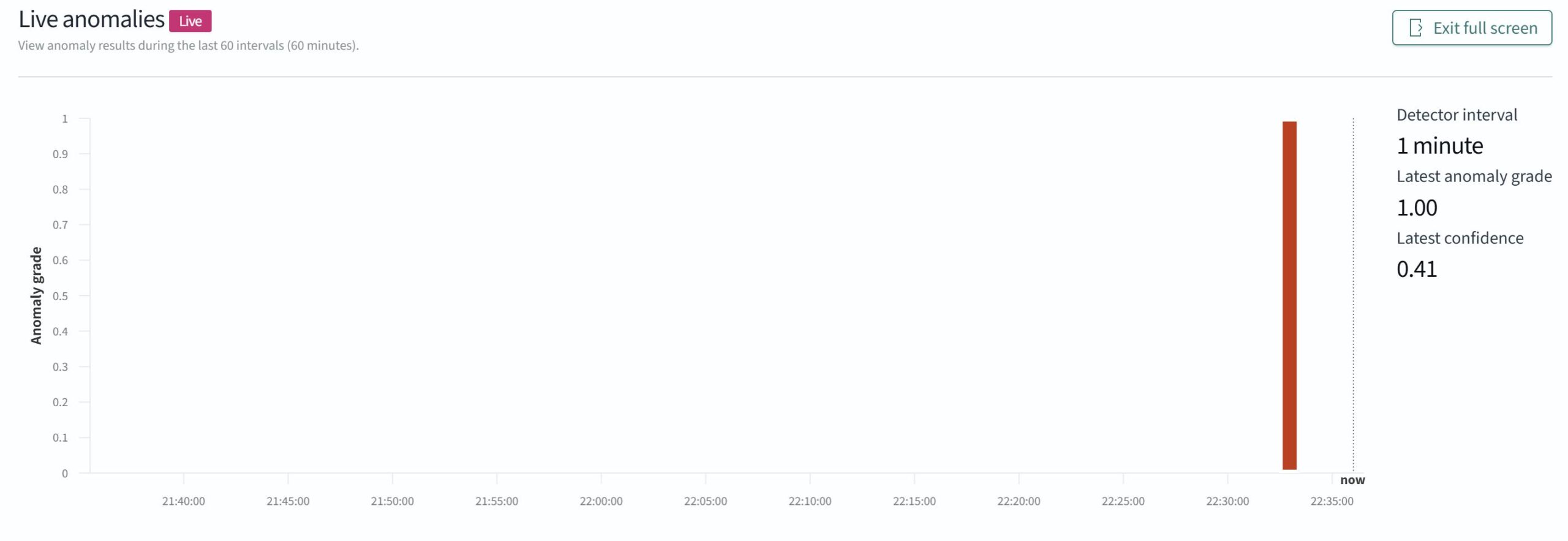
Detector の詳細画面では、時系列グラフとともに異常スコア(Anomaly Grade)が表示されます。
- Anomaly Grade: 0〜1の範囲で異常の度合いを示します。1に近いほど重大な異常です。
- Confidence: モデルの確信度です。
グラフ上で、通常のリクエスト数の推移(青線など)に対し、異常と判定されたポイントが赤くハイライトされます。
これにより、「いつ」「どの程度」異常なトラフィックが発生したかが一目でわかります。
以下の画像では設定してから新たに入れたデータが、赤くハイライトされてます。
アラート通知の設定(オプション)
ここまでは異常検知までの設定まで行いました。
それだけでは異常検知結果を誰かに通知することはできません。
そこで、OpenSearch の Alerting 機能と連携させることで、異常検知時に Slack やメール、Chime などに通知を送ることができます。
ちょっと駆け足になりますが、その設定についてもご紹介します。
チャンネルの設定
あらかじめ通知先を設定します。
OpenSearch Dashboards の左メニュー → Management → Notifications
Create Channel から任意の通知先を設定します。
OpenSearch Dashboards の左メニュー → OpenSearch Plugins → Alerting
Alerting メニューから "Create monitor" をクリックして、以下の項目を設定します。
- Monitor details
| 項目 | 説明 |
|---|---|
| Monitor name | web-logs-anomaly-detector-monitor |
| Monitor type | Per query monitor |
| Monitor defining method | Anomaly detector |
| Detector | web-logs-anomaly-detector |
| Schedule | 1 Minute(s) |
- Trigger
| 項目 | 説明 |
|---|---|
| Trigger name | web-logs-anomaly-detector-trigger |
| Severity level | 1 (Highest) |
| Trigger type | Anomaly detector grade and confidence |
| Anomaly grade threshold | IS ABOVE 0.7 |
| Anomaly confidence threshold | IS ABOVE 0.7 |
| Actions | 先ほどの通知先を設定したものを選択 |
Create をクリックして、設定内容を保存します。
まとめ
OpenSearch の Anomaly Detection を利用することで、静的な閾値設定に頼ることなく、動的なログ出力数などの変化に追従した高度な監視が可能になります。
- 設定が容易: GUIベースで数ステップで設定可能。
- メンテナンスフリー: データのトレンド変化を自動学習するため、閾値の定期的な見直しが不要。
- リアルタイム: 異常発生を即座に検知し、迅速な対応につなげられる。
システムの安定稼働のために、ぜひ導入を検討してみてください。

テクニカルサポートをしている甫立です。
普段はシステム運用・保守を担当してます。
バリバリやってます。よろしくお願いします。