
目次
はじめに
AWSサポートをよく利用させていただいているのですが、サポートセンターの問い合わせの返信をSlackで受け取りたいと思っていたので受け取れるようにしてみました。
この記事ではその大まかな手順とLambdaを紹介したいと思います。
今回の構成
今回紹介する構成は以下のようになります。
構成図
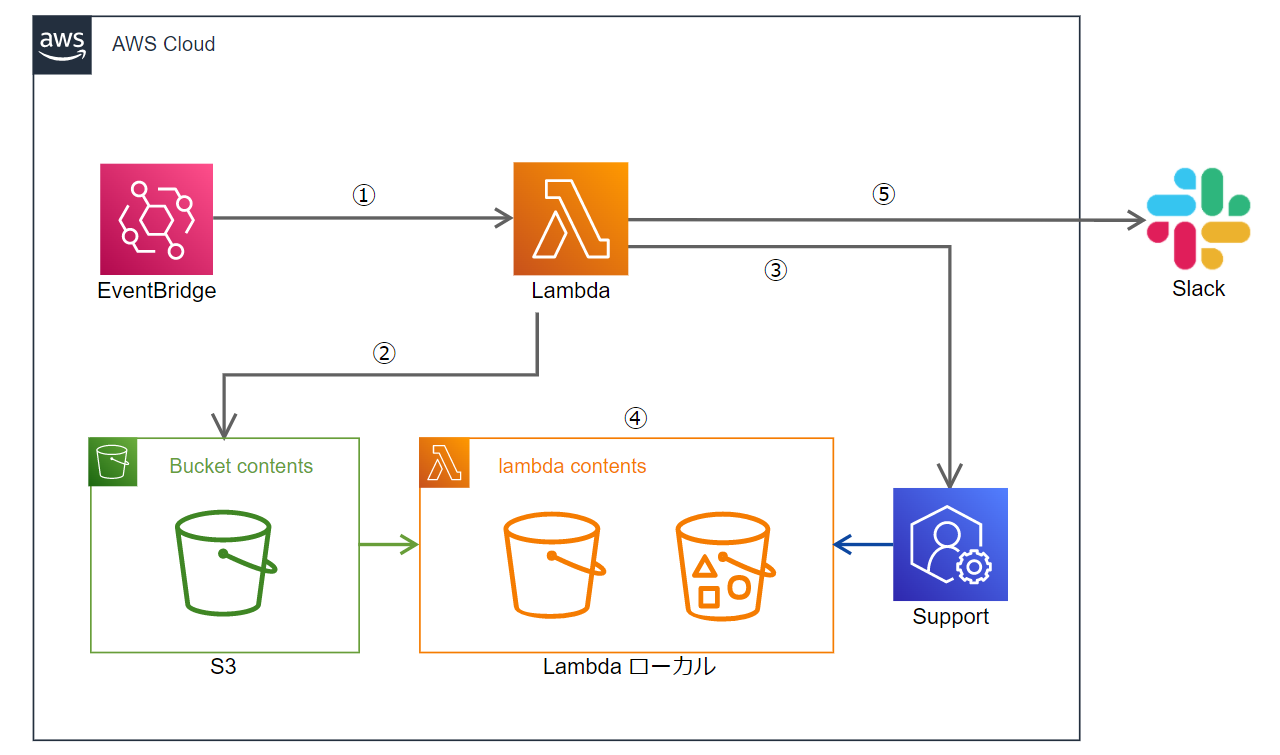
フローについて
上記の図について少しだけ補足で、基本的にはこのような流れになっています。
- cronによるLambdaの定期実行
- S3から前回Lambda実行時に取得した問い合わせ情報.csvをダウンロード
- サポートから現在の問い合わせ情報をcsvに整形
- 2と3のcsvを比較し、差分を更新点としてS3にアップロード
- 問い合わせがAWSサポート側で更新された場合はそのケースをSlackに送信
問い合わせ情報.csvについて
ケースID,ディスプレイID,返信数,件名,ユーザ名,最新の投稿のユーザ名
case-XXXXXXXXX-mjja-XXXX-XXXXXXXXXXXXX,XXXXXXXXX,999,EC2のインスタンスタイプについて,blog_denet (IAM) <aws@dedededenet.wow.com>,Amazon Web Servicescsvは上記のようなものを作成していて、ここにオープンケースの情報が保存されます。
また例として3にて最新の問い合わせ情報を取得した際、
返信数が1000などであった場合は差分が発生しているのでSlackに送信されるといった形になります。
Webhook Urlの発行
SlackとLambdaをつなげるのにWebhook URLを用意する必要があります。
発行するには下記URLにアクセスします。
https://slack.com/services/new/incoming-webhook
Webhookを追加するチャンネルを選択すれば、
https://hooks.slack.com/services/~~の形式のWebhook URLが発行されるので控えておきます。
Lambdaを準備する
リージョンの確認
Lambdaを作成するリージョンはバージニア北部 (us-east-1)であることを確認します。
それ以外のリージョンはAWS SupportのAPIが対応していないかと思います。
作成したコードの紹介
import json
import boto3
import urllib
import csv
import os
import pandas as pd
from time import sleep
s3 = boto3.resource('s3')
support = boto3.client('support')
#バケット名
bucket = 'bakebakebaketto'
#インスタンス数を保存するファイル
key = 'opencase_data.csv'
def post_slack(user_name,subject,display_id,body):
'''
slackにsend_dataを送信する。
'''
send_data = {
'attachments': [{
'pretext': hoge '表示させたいテキスト',
'color': hoge 'カラーコード',
'title': subject,
'title_link': 'https://console.aws.amazon.com/support/home#/case/?displayId={0}&language=ja'.format(display_id),
'author_name': user_name,
'short': False,
'text': body
}]
}
send_text = json.dumps(send_data)
url = 'ここにwebhookのurlいれます。'
request = urllib.request.Request(
url,
data=send_text.encode('utf-8'),
method="POST"
)
with urllib.request.urlopen(request) as response:
response_body = response.read().decode('utf-8')
def get_support_describe_cases():
response = support.describe_cases(
includeResolvedCases=False,
maxResults=50,
language='ja',
includeCommunications=True
)
return response
def cut_body_text(body):
'''
slackで読みやすくするためにbodyのtarget以下をちょんぎる
'''
target = '今回の担当者の対応は適切でしたでしょうか?'
return body.split(target)[0]
def trim_case_info(case):
'''
データ整形
case_id : string AWSサポートコンソールから確認できるIDとは別のID
subject : string 件名
inquire_user : 問い合わせ投稿者
latest_reply_user : 最後に返信した方
communication_index : 返信の数
display_id: よくみるID
body: 本文
'''
#nullチェック
if not case['recentCommunications']['communications'][0]['body'] == '':
body = case['recentCommunications']['communications'][0]['body']
body = cut_body_text(body)
else:
body = None
data = {
'case_id': case['caseId'],
'subject': case['subject'],
'inquire_user': case['recentCommunications']['communications'][-1]['submittedBy'],
'latest_reply_user': case['recentCommunications']['communications'][0]['submittedBy'],
'communication_index': len(case['recentCommunications']['communications']),
'display_id': case['displayId'],
'body': body
}
return data
def get_compare_csv_data(pre_path,cur_path):
'''
データを比較。
'''
pre_csv = pd.read_csv(pre_path)
cur_csv = pd.read_csv(cur_path)
_data = pre_csv[(pre_csv == cur_csv).all(axis=1) == False]
return _data
def get_data_from_s3(save_path):
'''
s3からcsvをsave_pathに保存
'''
s3.meta.client.download_file(bucket, key, save_path)
s3.meta.client.download_file(bucket, 'opencase_data_test.csv', '/tmp/test_' + key)
def save_data_to_s3(hogelist,obj_path):
'''
obj_pathのcsvにヘッダーを加えてhogelistの情報を書き込みS3にアップロードする。
'''
obj = s3.Object(bucket,key)
with open(obj_path, 'w+') as data:
print(data.read())
writer = csv.writer(data)
writer.writerow(['ケースID','ディスプレイID','返信数','件名','ユーザ名','最新の投稿のユーザ名','本文'])
for l in hogelist:
writer.writerow([l['case_id'],l['display_id'],l['communication_index'], l['subject'], l['inquire_user'],l['latest_reply_user'],l['body']])
s3.meta.client.upload_file(obj_path, bucket, key)
def lambda_handler(event, context):
data = get_support_describe_cases()
hogelist =[]
for case in data['cases']:
trimmed_case = trim_case_info(case)
hogelist.append(trimmed_case)
previous_path = '/tmp/previous_' + key
current_path = '/tmp/current_' + key
# 別名で同じファイルをダウンロードする。
get_data_from_s3(previous_path)
get_data_from_s3(current_path)
# 片方だけ更新したサポート情報をcsvに上書きして保存する。
save_data_to_s3(hogelist,current_path)
# 値が変動した行?列?だけpanda_dataに入ってる
panda_data = get_compare_csv_data(previous_path,current_path)
for column_name, item in panda_data.iterrows():
if item['最新の投稿のユーザ名'] == 'Amazon Web Services':
post_slack(item['ユーザ名'],item['件名'],item['ディスプレイID'],item['本文'])
sleep(2)Slackで通知を確認する
Lambdaが実行されたあとSlackを確認してみます。
無事に表示されました。(見えない)
個人的な感想としては問い合わせ内の引用がインデントで整形されていたり引用URLがクリックで参照できるのでSlack上で見やすかったです。
おわりに
この記事ではAWSサポートのオープンケースが更新された場合に、その内容を含めてSlackに通知する処理を紹介しました。
似たような内容ですがRDSでもSlack通知した記事があるので、もし興味があればこちらも見てみてください。
【Lambda+S3】誰でもできるRDSの停止忘れのなくしかた。 | Denet技術ブログ
なにかしらが参考になれば幸いです。