
目次
はじめに
こんにちは、omkです。
最近はGlueジョブの結果の取得のパフォーマンス改善について色々と検証しています。
S3+AthenaよりRDS(MySQL)に入れたほうが取得が早くなるのではないかと思い、GlueジョブからRDSに書き込むようにしてみました。
やってみた
以下の記事を見つつやってみましたが少々ややこしいところもあったのでまとめていきます。
https://aws.amazon.com/jp/blogs/big-data/connecting-to-and-running-etl-jobs-across-multiple-vpcs-using-a-dedicated-aws-glue-vpc/
VPC側の設定
ポイントは
- セキュリティグループ
- VPCエンドポイント
です。
まずはセキュリティグループを用意します。
おおよそ以下のページに従います。
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/setup-vpc-for-glue-access.html
接続用のセキュリティグループは「すべてのTCP」を「接続用セキュリティグループ」に自己参照で許可します。
RDSのセキュリティグループは接続用セキュリティグループからMySQLに対するアクセスを許可します。
つぎにRDSを準備します。今回はMySQLのものを用意します。
詳細は割愛。DBとテーブルを作っておきます。
S3のVPCエンドポイントも作成します。
Gateway型のエンドポイントをVPCに割り当ててルーティングします。
NATGatewayでも良いです。
これでVPC側の設定は完了です。
Glue 接続
つぎにGlue 接続を用意します。
Glueのコンソールから「接続」を選択します。
「接続の追加」から作成していきます。
接続名に任意の名前を設定して、接続タイプに「Amazon RDS」データベースエンジンに「MySQL」を選択します。
作ったRDSインスタンスを選択してDBとユーザー・パスワードを入力します。
で、現在のコンパネではこのままRDSのVPC・サブネット・セキュリティグループが割り当てられますので「編集」でセキュリティグループを接続用に作ったものに差し替えます。
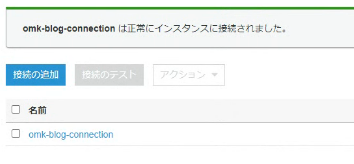
できたら「接続のテスト」を選択します。
これまでの設定が正しければ正常に接続できます。
Glueジョブ
最後に本題のジョブの設定をします。
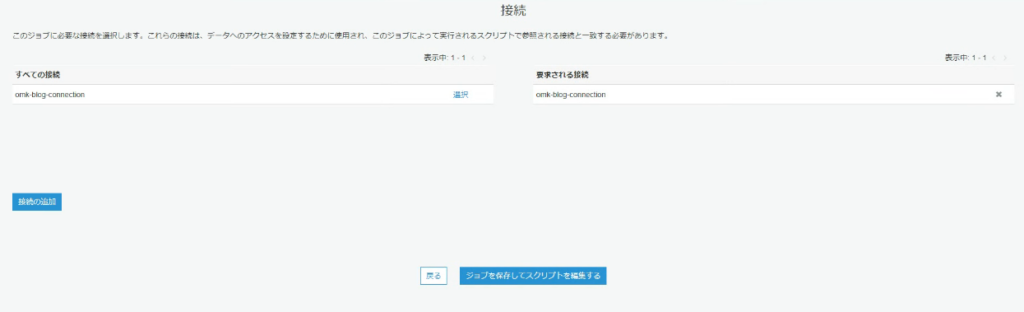
ジョブの設定で先程作った接続を割り当てる必要があります。
新規作成で「AWS Glue が生成する提案されたスクリプト」を設定した場合
それ以外で新規作成する場合
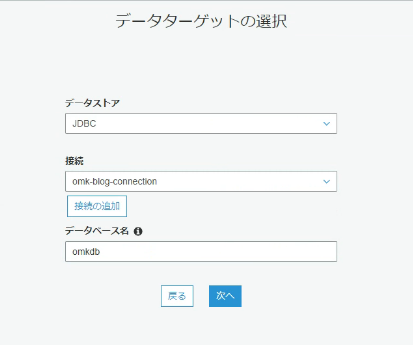
既存のジョブを変更する場合は「編集」から設定します。
あとはスクリプトを接続を用いて書き込むように記載します。
glueContext.write_dynamic_frame.from_jdbc_conf(
frame = {dataframe},
catalog_connection = "{接続名}",
connection_options = {
"dbtable": "{テーブル名}",
"database": "{DB名}"
}
)ユーザー名パスワードは接続に設定されているのでコードに記載する必要はありません。
これで設定は完了なのでジョブを実行します。
ジョブが完了したらMySQLにログインしてテーブルにデータが入っていることを確認します。
結果が取れたので完了です。
おわりに
Athenaはクエリの実行に時間がかかることがあるので、やはり安定的に速度を求める場合RDSをプロビジョニングするなどの対応が有効であると考えます。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/athena-queries-long-processing-time/
実際にMySQLクライアントからクエリを実行した結果、かなりの速度改善が見込まれました。
データの内容や容量などに合わせた適切なデータベースの選択が必要ですね。
以上、最後までお付き合いありがとうございました。

アーキテクト課のomkです。
IoTが主食です。