
目次
はじめに
こんにちは、omkです。
前回はAthenaでPySparkのノートブックを実行出来る環境を作成しました。
AthenaでPySparkを用いてクエリしてみた
今回はノートブックエディタを用いてGlue Data Catalogに既にあるテーブルをIcebergのテーブルに移行します。
前提条件
対象のテーブルについて
対象テーブルはS3にCSVを配置して、Glue Crawlerで Glue Data Catalogに登録したテーブルです。
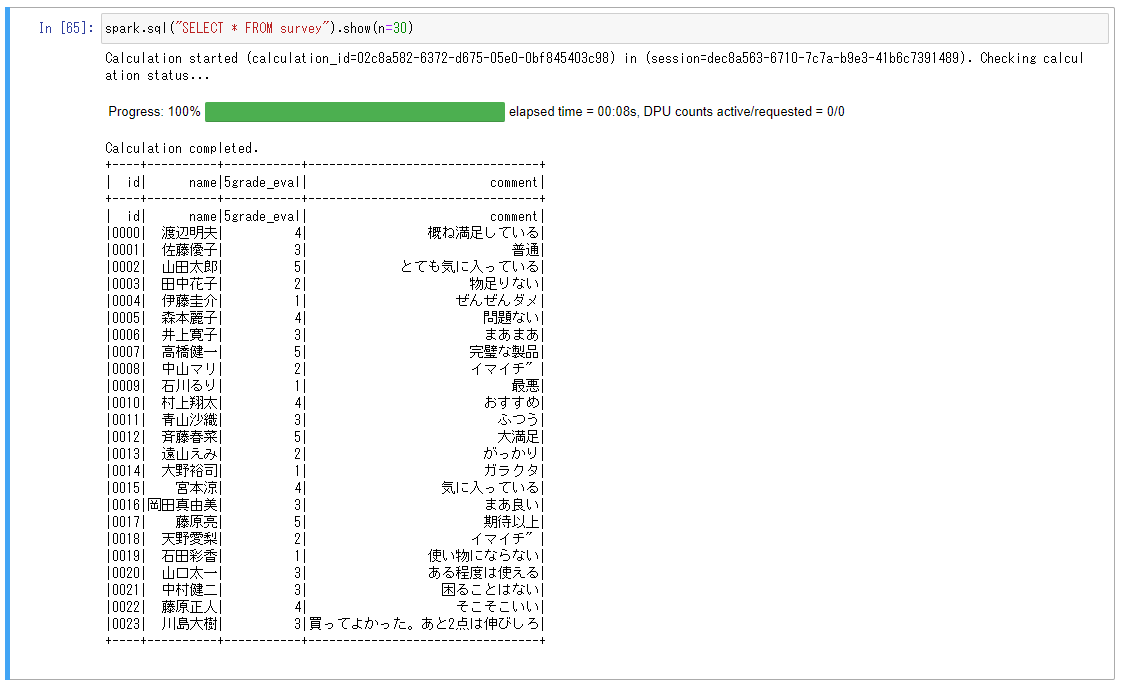
前回も利用しましたが、ある炊飯器の製品に対して5段階評価のレビューを実施した、という想定で作成したテーブルです。
回答のID、回答者の名前、評価点、コメントがテーブルに含まれます(よく考えたらこの手のレビューに名前が含まれてるのって違和感ありますね)。
実行環境
Athenaのノートブックエディタで実行します。
詳細は↓こちら。
AthenaでPySparkを用いてクエリしてみた
ノートブック作成時に追加のテーブル形式で「Apache Iceberg」を選択しておきます。
やってみた
テーブルの作成
基本的にはAmazonの公式のテーブル作成の流れに沿って実施します。
Apache Iceberg
データベース名、テーブル名、データを保存するS3のパスをそれぞれ指定しました。

データベースを作成します。

作成したデータベースに空のテーブルを追加します。
このときにIcebergを使うことを指定します。
TBLPROPERTIES ("format-version"="2")
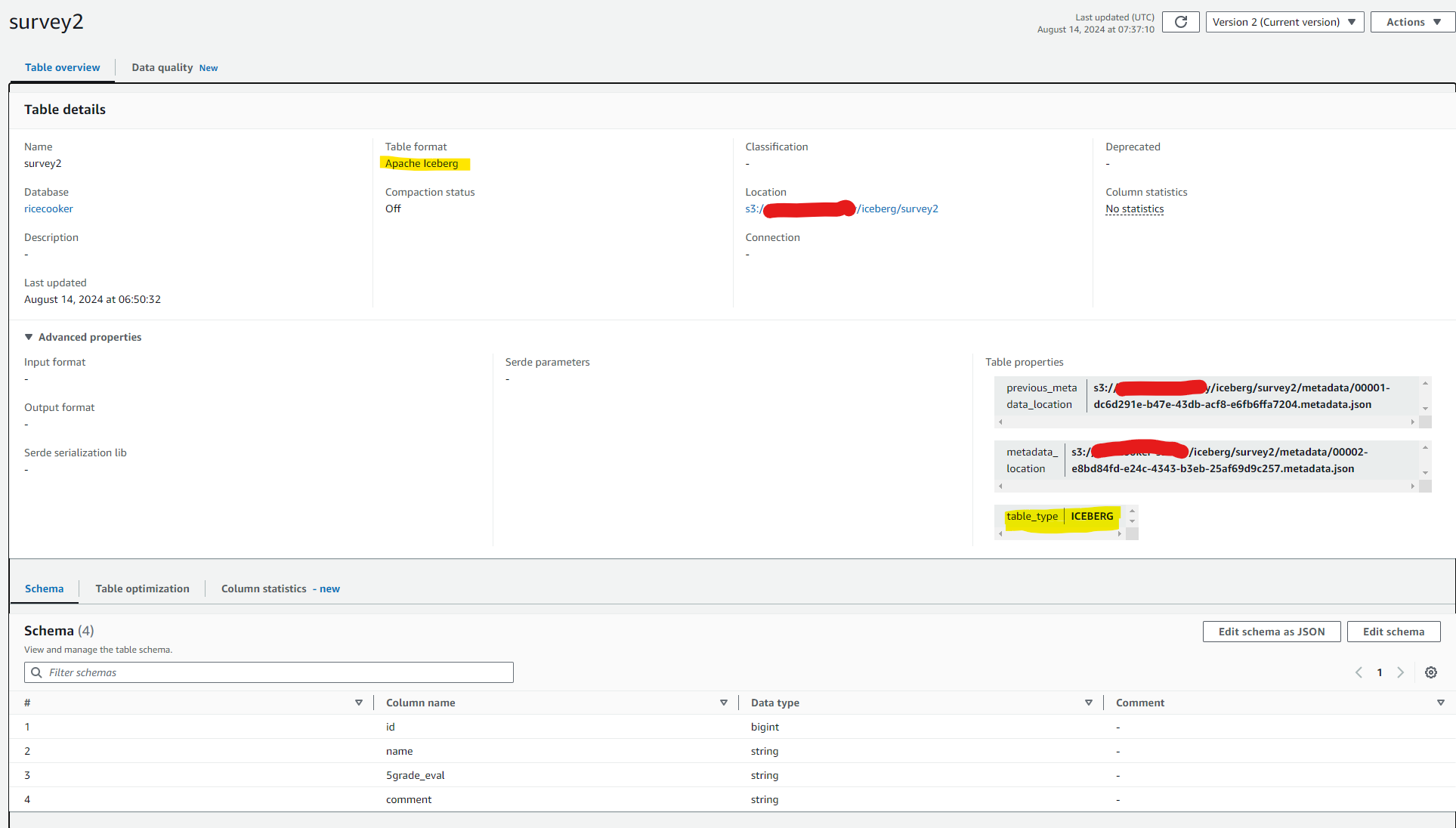
これでGlue Data Catalogにデータベースとテーブルが作成されました。
画像の黄色い部分を見ていただくとテーブルのフォーマットがIcebergで作成されていることが分かります。
ノートブック作成時に追加のテーブル形式で「Apache Iceberg」を設定することで、いくつかパラメータを設定してくれます。
"spark.sql.catalog.spark_catalog": "org.apache.iceberg.spark.SparkSessionCatalog",
"spark.sql.catalog.spark_catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"spark.sql.catalog.spark_catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"これらが作用していい感じにGlue Data Catalogに設定してくれるようになっています。
データの移行
では作成されたテーブルに元のテーブルのレコードを差し込んでいきます。
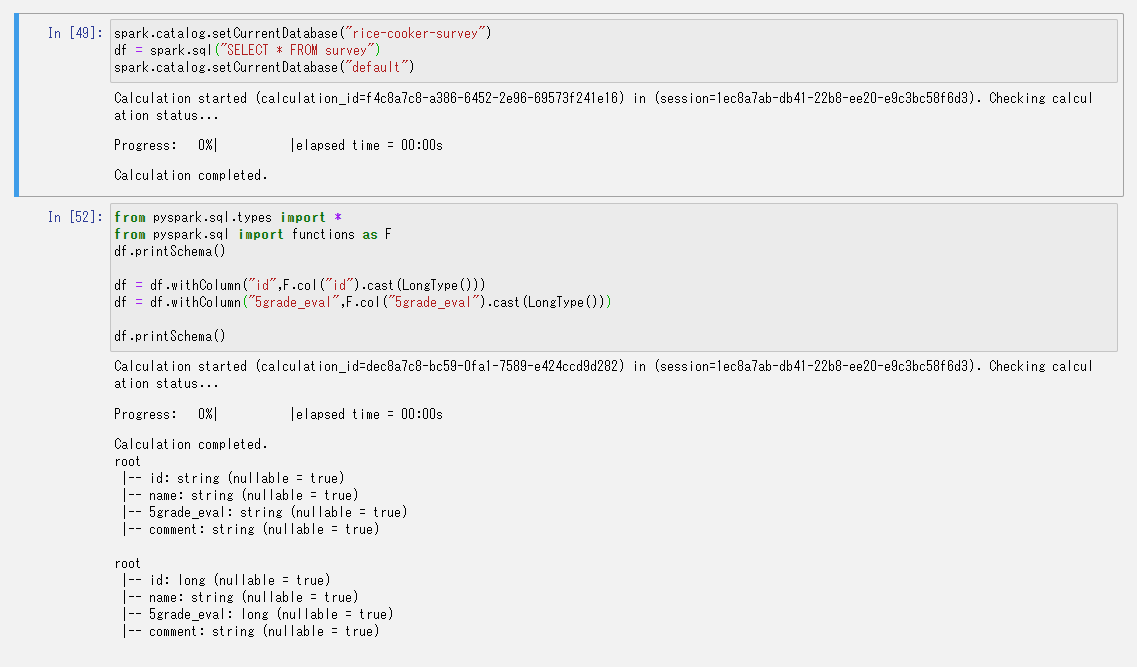
まずはデータの取得します。
そのままでは書き込めなかったので軽くDataFrameのスキーマをイジイジしました。
新しいテーブルに書き込みます。

書き込めました。
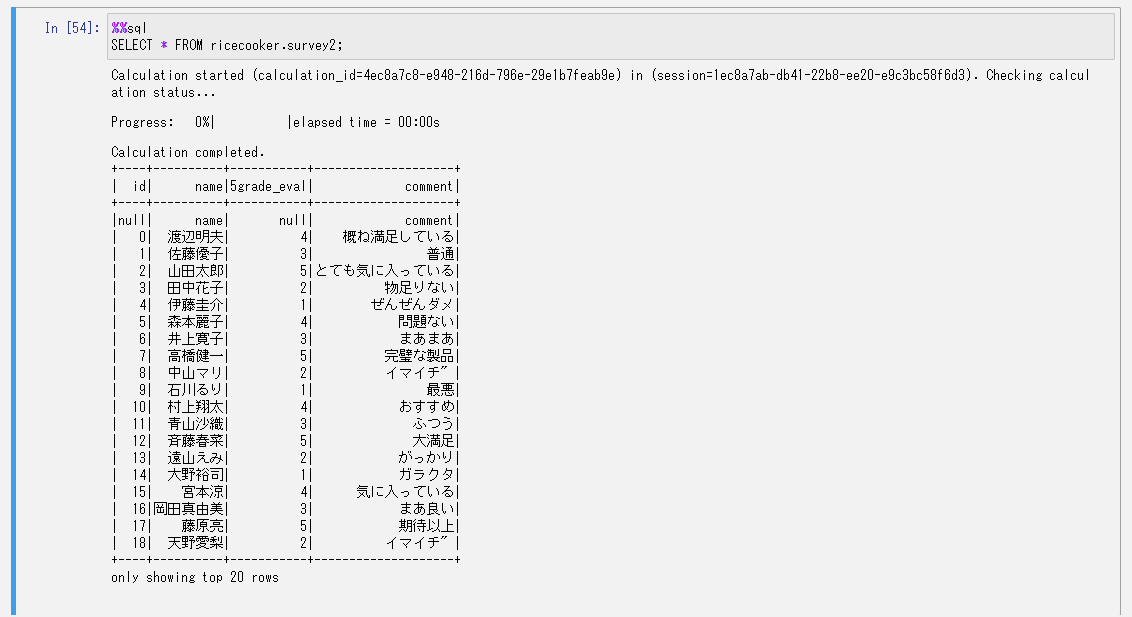
これでデータの移行は完了です。
リアルタイムでデータが入ってくる場合は元の書き込み先のテーブルを切り替えてやるかんじになりそうですね。
動作確認
これだけではIcebergの機能が使えているかわからないので色々試してみます。
更新の履歴を確認します。
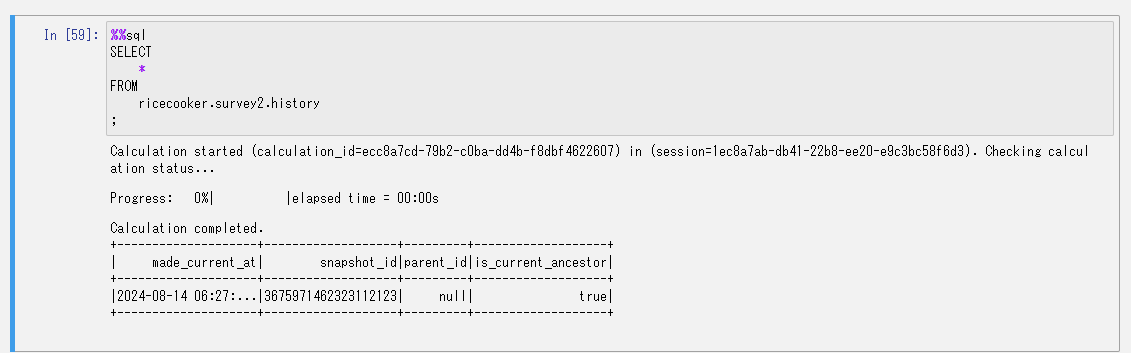
特定のレコードだけを書き換えてみます。
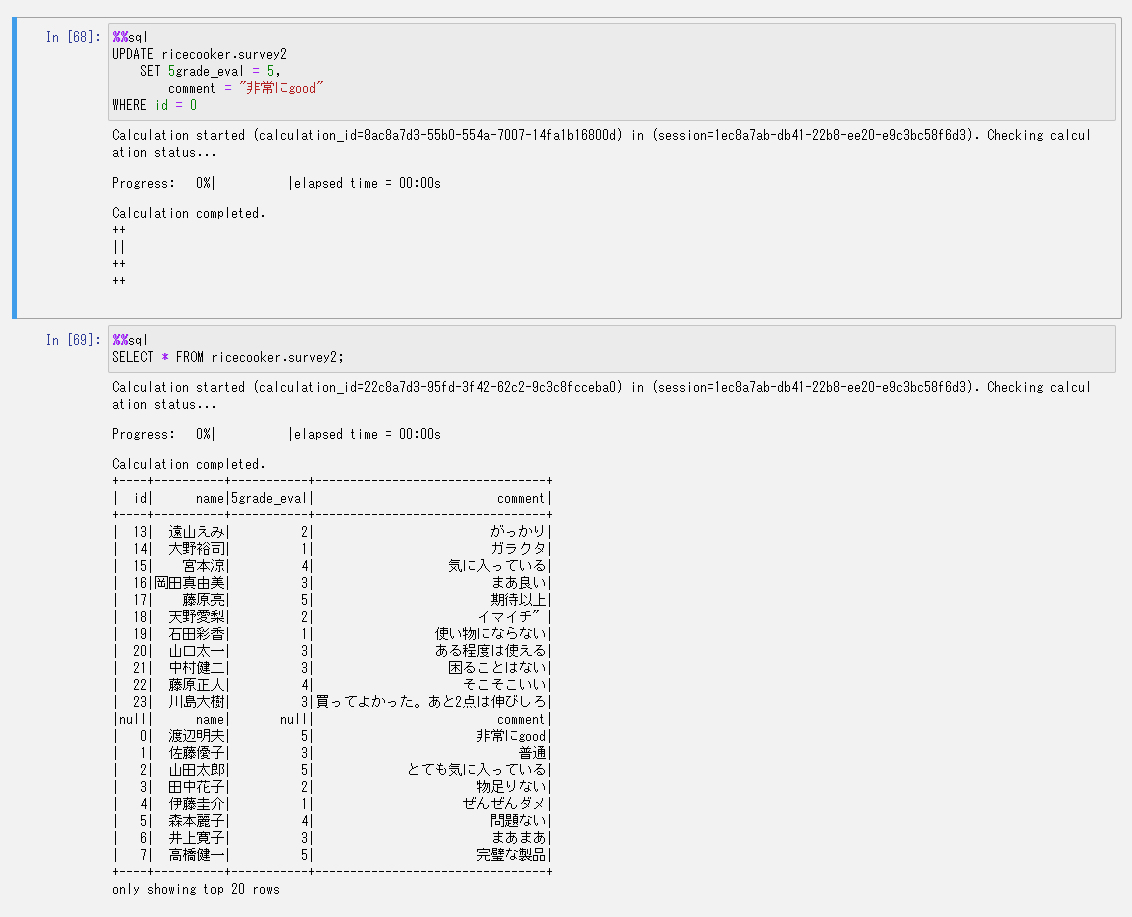
無事書き換わりました。
これがやりたかったんですよねぇ。
簡単に書き換えられて楽ですね~~!!
もう一度更新の履歴を確認します。
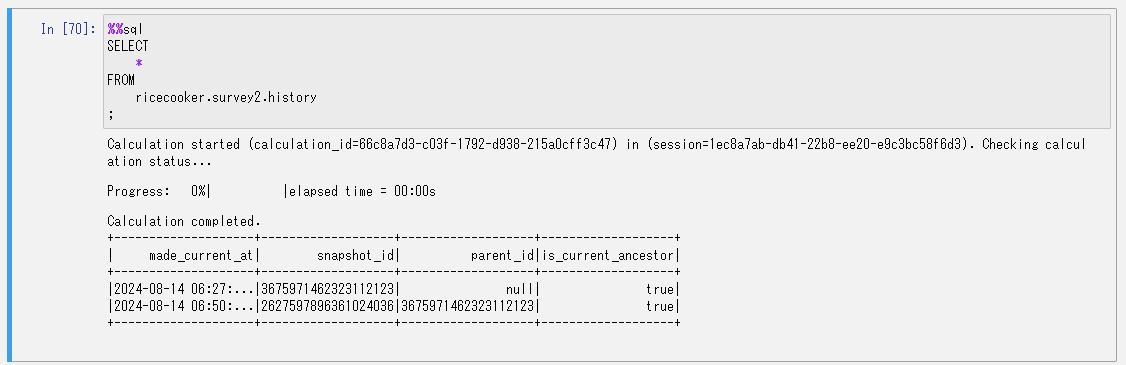
ヒストリーにスナップショットが追加されていますね。
では過去のスナップショットからタイムトラベルを……と思いましたが対応していないんですかね?エラーでうまく動かなかったので諦めます。
おわりに
もっと色々オープンテーブルフォーマットを使いこなせるとデータレイクの構築が楽になりそうですね。
以上、最後までお付き合いありがとうございました。

アーキテクト課のomkです。
IoTが主食です。