
目次
はじめに
こんにちは、omkです。
前回に引き続きApache Iceberg関連です。
前々回: AthenaでPySparkを用いてクエリしてみた
前回: Glue Data CatalogのテーブルをApache Icebergに対応させてみた
S3にデータレイクを構築しているとデータの実体がS3上にファイルとして保存されているため、レコードの更新が非常に面倒です。
Apache Icebergを使ってテーブルの管理を行うことでレコードの更新を容易に出来るのでやってみました。
前提
構成
こんな感じの構成を取ります。
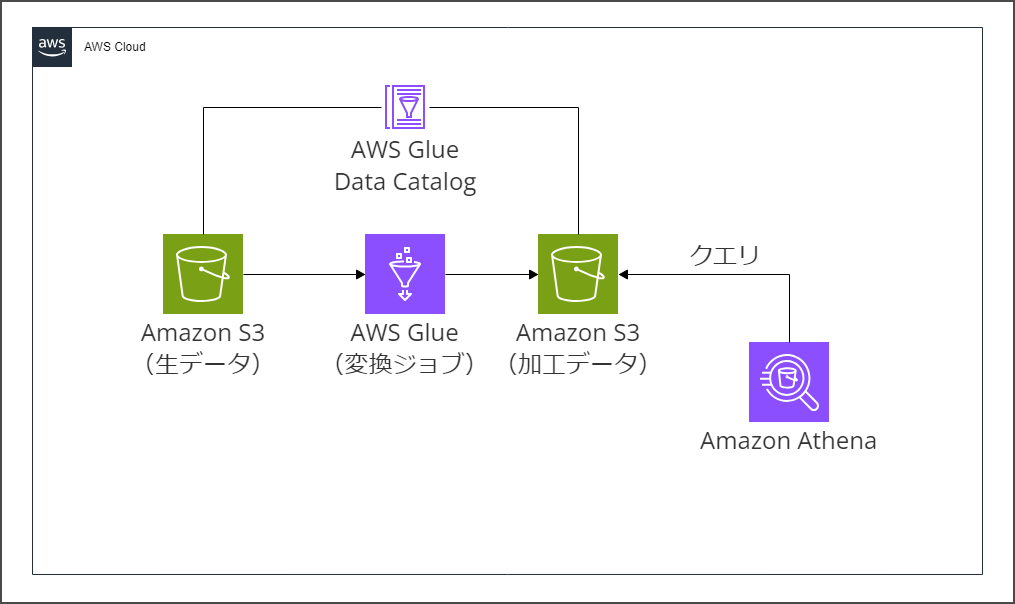
S3バケット(こっちはIceberg使わない)に元データのファイルを置いて、Glueジョブで変換処理を行い、加工後のデータを別のS3バケット(こっちはIceberg使う)に書き込みます。
Glueジョブではデータの更新を最小限にして整合性を保つ目的でジョブのブックマーク機能を利用し、テーブルに対してMERGE INTOで既存のレコードを更新、新規のレコードを追加します。
これにより後からのレコードの修正を可能にします。
取り扱うテーブル
以下の内容のテーブルを利用します。
炊飯器の製品に対してのレビューの結果、という体で作成されたものです。内容はすべてダミーです。

生データではこれがCSVで送られてきて、Glueジョブでnameの行を落として、加工済みデータとしてIcebergで管理するテーブルに更新をかけます。
やってみた
作成したジョブを記載します。ジョブはGlue4.0で作成しました。
ジョブの基本的な部分については以下の記事を参考にしています。
AWS Glue ETL を使用して、Apache Iceberg でマージ、パーティションの進化、スキーマの進化を実行する
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.conf import SparkConf
from pyspark.sql import functions as F
from awsglue.context import GlueContext
from awsglue.job import Job
import boto3
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME','AccountId','warehouse_path'])
GLUE_DATABASE = "ricecooker"
GLUE_RAW_TABLE = "survey1"
GLUE_PROCESSED_TABLE = "survey2"
conf = SparkConf()
conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
conf.set("spark.sql.catalog.glue_catalog", "org.apache.iceberg.spark.SparkCatalog")
conf.set("spark.sql.catalog.glue_catalog.warehouse", args['warehouse_path'])
conf.set("spark.sql.catalog.glue_catalog.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog")
conf.set("spark.sql.catalog.glue_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO")
conf.set("spark.sql.catalog.glue_catalog.glue.lakeformation-enabled", "false")
conf.set("spark.sql.catalog.glue_catalog.glue.id", args['AccountId'])
sc = SparkContext(conf=conf)
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 生データの取得
df1 = glueContext.create_dynamic_frame.from_catalog(database = GLUE_DATABASE, table_name = GLUE_RAW_TABLE, transformation_ctx = "df1").toDF()
# 新規データがある場合のみ以下を実行
if not df1.isEmpty():
# 不要カラムの削除
df1 = df1.drop('name')
# ビューを作成
df1.createOrReplaceTempView("input_table")
# 書き込み
merge_table = f"""
MERGE INTO glue_catalog.{GLUE_DATABASE}.{GLUE_PROCESSED_TABLE} AS target
USING input_table AS source
ON target.id = source.id
WHEN MATCHED
THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
"""
spark.sql(merge_table)
job.commit()シンプルな内容に収まりました。
ジョブのパラメータは画像のようにしています。
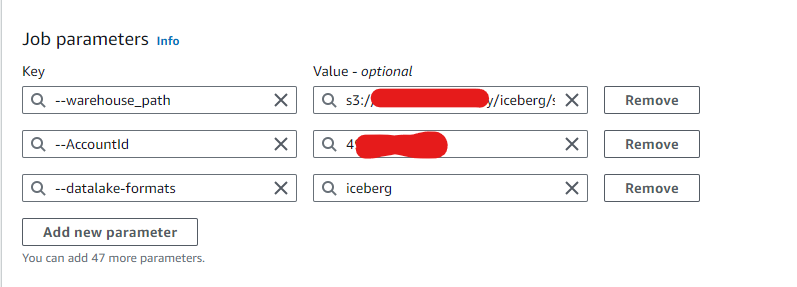
GlueでIcerbergを利用する際の必要なパラメータや注意点などは以下のドキュメントに記載があるのでこちらも合わせて参照ください。
AWS Glue での Iceberg フレームワークの使用
では作成したジョブを実行していきます。
まとまったデータで初回実行→追加のデータ挿入→データ書き換え、の流れで確認していきます。
まずは初回実行。。
レコードが書き込まれました。
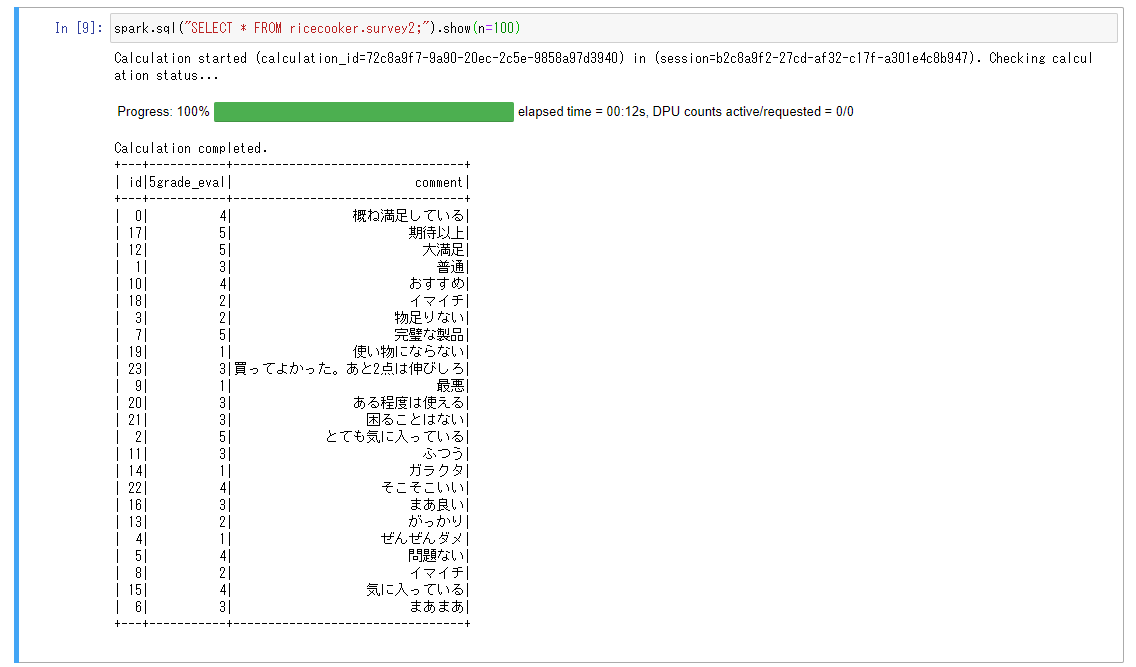
余談ですがIceberg側でテーブル定義を変更したら(データ自体を変更しても?)Data Catalog側のテーブルでも新しいバージョンが発行されていてちゃんと連携してるんだーって思いました。
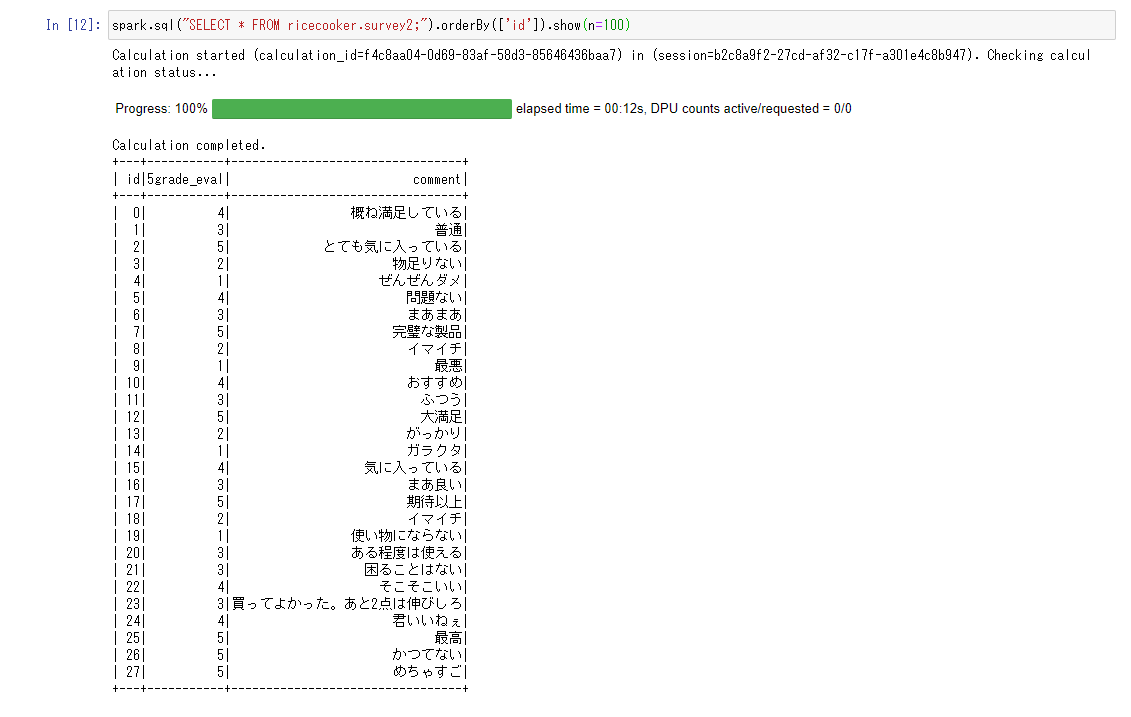
次に追加のデータを生データのバケットに置いて再度ジョブを実行します。
先ほどの結果が分かりづらかったのでソートしましたが、idが24から大きいレコードが新規に挿入されたものです。
最後にidが27のレコードを書き換えて再実行してみます。
無事書き換わりました。

データの内容にもよりますがブックマークが正常に効いていないと書き換えに失敗することがあるので注意です。
今回はファイルを別名で追加してこれまでの処理済みのデータもバケットに残したままでジョブを実行していたため、書き換えのソース側のレコード間でidに重複が生じてエラーになっていました。
なのでやり方によってはブックマークも要らないとおもいます。
おわりに
非常に便利ですね。もっと早く知っておけばよかったです。
他にもパフォーマンス改善やレイクでありがちなお困りポイントを解消出来るようなのでまた時間を見つけてやってみようと思います。
Glue4.0だとIcebergのバージョンは1.0.0みたいです。
2系への対応が待ち遠しいですね。
以上、最後までお付き合いありがとうございました。

アーキテクト課のomkです。
IoTが主食です。