
目次
はじめに
こんにちは、omkです。
前回はEmbeddingを行って、過去のブログ記事から入力に応じた関連する記事を紹介するシステムをつくりました。
【Amazon Bedrock】Titan Embeddings Generation 1を利用して過去のブログ記事から入力に関連する記事を出力してみた
結果としてはちゃんと関連した記事が返ってきましたが、各記事間でどれだけ類似しているのかがよく分からなかったので2次元で理解できるように散布図にしてみました。
結論
そもそもデータに関連性が低いのか高次元のベクトルから次元数を2まで削減しているせいか正直よくわからない結果になりました。
よくわかっていないのはそもそも私がちゃんとしたやり方を理解していないまま進めているのもあります。
※追記 3次元で表現したらわりと関連性が見えるようになりました。記事の下の方に追記しています。
必要な次元数を持たせた上でクラスタリングを行うのが良いと思います。
プログラム
次元削減には主成分分析を利用し、そのために「scikit-learn」を使用します。
図の描画には「matplotlib」を利用します。
Embeddingsの結果はJSONファイルでマシン上に置いています。値の取り方は前回の記事にありますのでそちらをご参照ください。
プログラムはEmbedding(エンベディング)の概念を理解してみた、複数のplt.textで重なる文字をなんとかできる。を参考にさせていただきました。ありがとうございます。
import json
import numpy as np
from sklearn.decomposition import PCA
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
from adjustText import adjust_text
embeddedfile = './embedding.json'
outputfile = './scatter.png'
jpfont = './ipaexg.ttf'
fontfamily = 'IPAexGothic'
def main():
with open(embeddedfile) as f:
vectors = json.load(f)
pca = PCA(n_components=2)
pca_vec_list = pca.fit_transform(list(vectors.values()))
X = pca_vec_list[:,0]
Y = pca_vec_list[:,1]
font_manager.fontManager.addfont(jpfont)
plt.rcParams['font.family'] = fontfamily
plt.figure(figsize=(16, 16))
plt.rcParams["font.size"] = 6
plt.scatter(X,Y,s=10)
plt.grid(True)
texts = [plt.text(x, y, title, ha='center', va='center') for title, x, y in zip(vectors.keys(),X,Y)]
adjust_text(texts)
plt.savefig(outputfile)
plt.show()
if __name__ == '__main__':
main()結果
散布図になりました。距離が近いものが意味的に近い内容になっています。

目測でなんとなくこうかな?と思った感じに線を引いてみました。
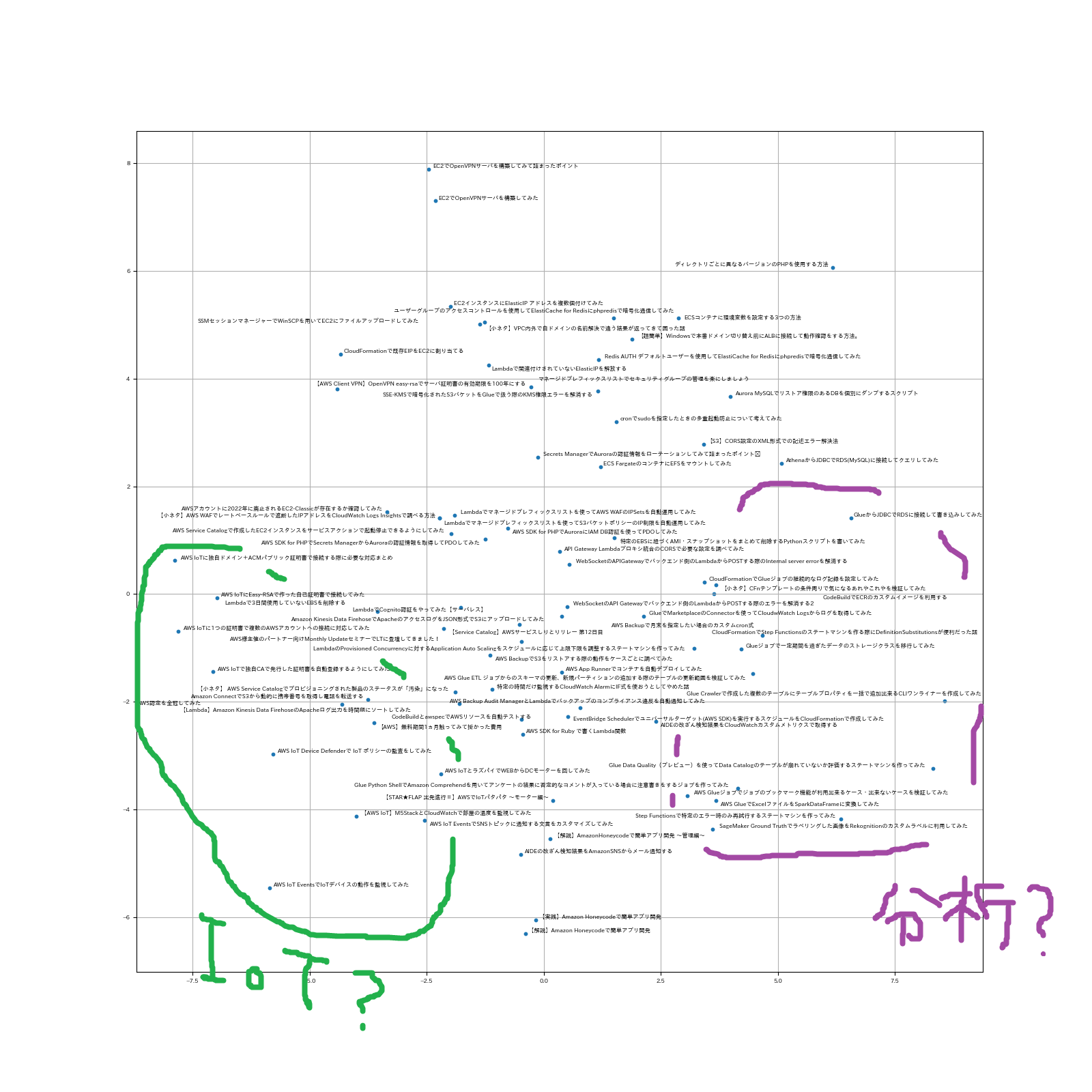
GlueとIoT周りは色々と記事を書いているのである程度の塊が見られました。
それ以外はあまり記事同士で関連性が見られなかったのか「ここはこればっかりだよね」となるブロックは見つかりませんでした。
かなり次元を落としているので位置関係も合っているんですかね……
※追記
3次元で表現したところそれなりにまとまりが見えるようになりました。(見づらいのです別ページで拡大して見てみてください)
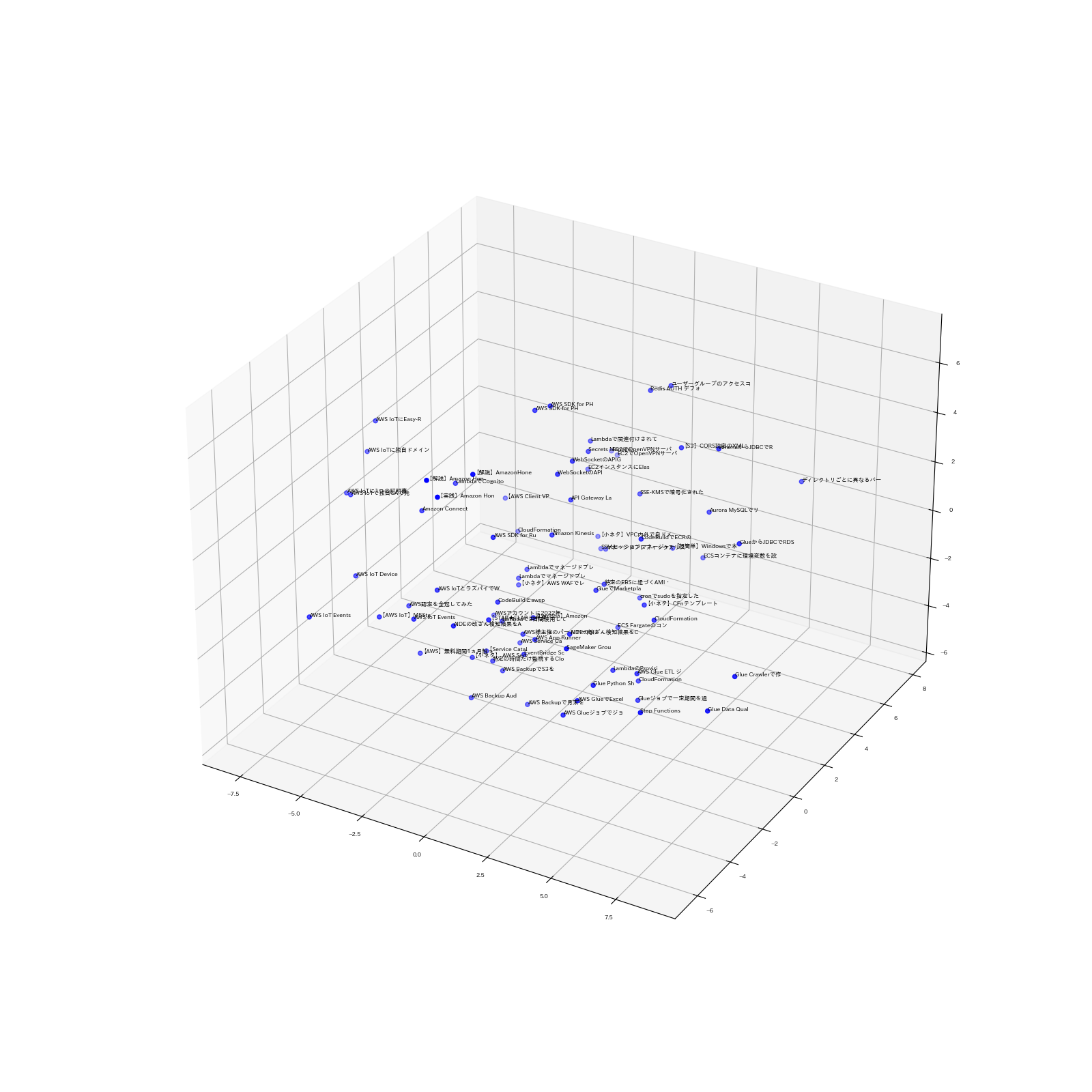
ごちゃごちゃするので記事のタイトルは先頭15文字しか表示していませんが、それなりに関連性が見えます。
おわりに
ちゃんとした手法に則ってやっていないので、まぁ何か面白かったなで留めておこうと思います。
ちゃんとやったら価値のあるものになると思うのでそれまでレベル上げしておきます。
以上、最後までお付き合いありがとうございました。

アーキテクト課のomkです。
IoTが主食です。