こんにちは。構築担当の下地です。
私は会社でも自宅でも親指トラックボール派です。
でも最近親指を酷使しすぎたのか、付け根が痛くて腱鞘炎気味なので、泣く泣くマウスに乗り換えました。
早く治るといいのですが・・
さて、今日はCloudWatchのアラームについてお話します。
よろしくお願いします。
目次
CloudWatchのアラーム
CloudWatchは説明不要なほどAWSでよく利用するサービスですが、もっと詳しく知りたいと思い少しずつ触っています。
色々検証でアラームを設定すると次はそのアラームをチェックしたくなるのですが、手動でテストのためにアラームを発報させる方法ってどうするんだっけ?と気になったので調べてみました。
まずアラーム設定
簡単なアラームをセットして試してみます。
テスト用にEC2(MyTestServer01)を1台作成し、アラームをセットしました。
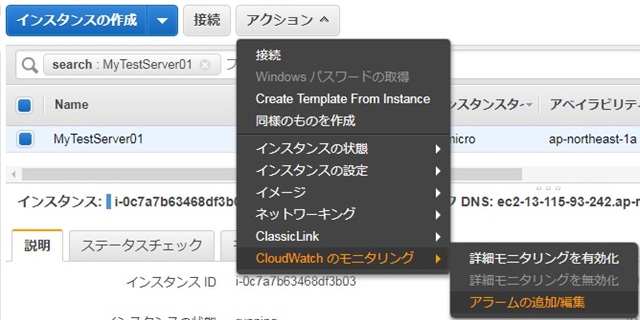
アラーム内容は以下の通りです。
・通知の送信先:自分のアドレス
・アクションを実行:インスタンス再起動
・発生条件:ステータスチェック(インスタンス)に失敗
・最低期間:1分間以内に1回発生
・アラーム名:MyTestEC2Alarm
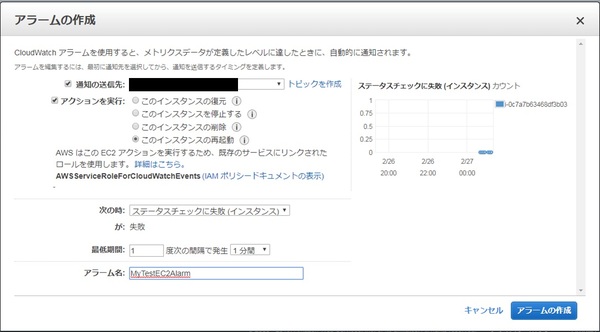
これでアラームのセットができました。
CloudWatchのマネジメントコンソール画面(以下マネコン)からもアラームが作成されていることを確認します。

テストでアラーム発報①:本当にアラーム発生条件に該当する状態にする
まず1つ目の方法としては、当たり前ですが「EC2をアラーム発生条件に当てはまる状態に設定する」です。
今回のアラーム発生条件はインスタンスのステータスチェック失敗ですので、試しにNICをダウンさせてみます。
これによりわざとステータスチェックが失敗する状態にします。
SSHでテスト用サーバにログインして、eth0をダウンさせます。
[root@webtestserver ~]# ifdown eth0これでOKです。
実行すると直後にSSHが切断されます。
この状態でマネコンを見てると、しばらくしてインスタンスのチェック失敗が表示されました。

CloudWatch側でもアラーム状態に遷移しています。

これでアラーム発生時のアクションを再起動にしているため、自動でサーバ再起動が実施されます。
再起動後はNICが正常に戻るはずです。
またしばらく待っていると、EC2のインスタンスヘルスチェックが正常に戻りました。

CloudWatch側も再び「OK」のステータスに遷移しています。
これがまず1つ目の方法となります。
テストでアラーム発報②:アラーム発生条件の閾値を手動で調整する
二つ目の方法は、アラーム発生条件の閾値を手動で変更して、通常時なのにアラーム発生条件に含まれるようにします。
例えば今回のアラームは、閾値が初期状態だと以下の通りになっています。

判定に使われるのは「StatusCheckFailed_Instance」で、この値が「1以上」になるとアラームを発報します。
このステータスは通常時が0で、インスタンスチェック失敗時に1になります。
そこで、この閾値を0以上に変更します。
すると通常の状態でも常にアラーム発報状態となります。
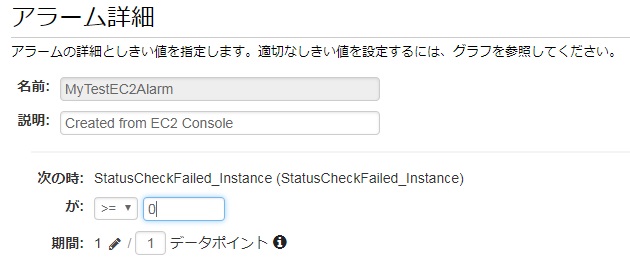
こんな感じで変更。
すると以下の通りマネコンに反映されます。
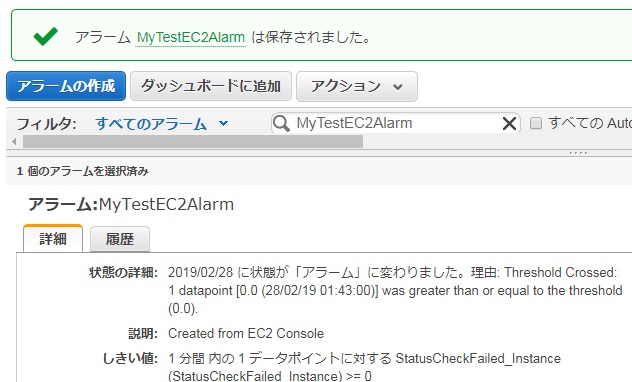
またこの変更を反映すると直後にSSHが切断されました。
すぐに再起動がかかったようです。
CloudWatchでもアラーム状態となっています。

数十秒後に再びSSH接続できました。
ただ、この手法ですとアラーム発報でリブートがかかっても依然アラーム状態が継続します(閾値が0以上なので当然ですが・・)。
EC2のマネコンでもアラーム状態のままとなっています。

またアラーム状態は継続しますが、再起動がかかかるのは1回のみでした。
これが2つ目の方法です。
テストでアラーム発報③:set-alarm-state コマンドを使用してアラーム状態の変更する
3つ目の方法は、aws cliを使って設定したアラームの状態を変更します。
参考:https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/US_AlarmAtThresholdEC2.html
今回は該当のEC2にSSH接続して、そこでCLIを実行してみます。
このEC2には事前にIAMロールを割り当ててCLIが実行できる権限を渡しています。
コマンドは以下の感じ。
[root@webtestserver ~]# aws cloudwatch set-alarm-state --alarm-name "MyTestEC2Alarm" --state-value ALARM --state-reason "alarmtest"これでOKです。
この方法ですと、実行後にマネコン側では変化を確認できませんでした。
ただ、
・実行直後にSSHが切断されたこと
・通知先メールアドレスにアラーム通知メールが届いていること
![]()
・サーバ側でリブート履歴が残っていること
![]()
から、アラームが発報して再起動がかかっていることがわかりました。
これが3つ目の方法です。
まとめ
今回は3つ方法を紹介しましたが、もしかしたら他にも何か方法があるかもしれません。
また今後はEC2だけでなく他のサービスでも色々CloudWatchの検証しようと思います。
お読み頂きありがとうございました。
おまけ
アラームを色々設定した後にアラーム名を変更しようとしたら、マネコンのどこを触っても変更箇所が出てきませんでした。
おかしいなと思ってマニュアル見ると、
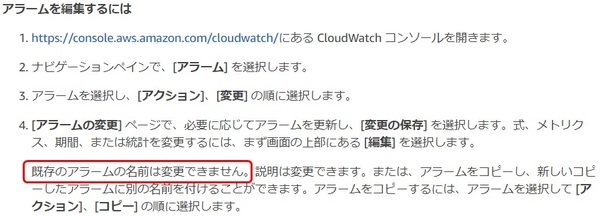
既存アラームの名前変更不可とのこと。。
まじですかー
参考:https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/Edit-CloudWatch-Alarm.html