
目次
はじめに
お疲れさまです、寺井です。
皆さんBedrockしてますか??
今月の初旬頃に Knowledge Bases for Amazon Bedrockのデータソースにウェブクローラーが使えるようになったとのことなので、弊社のホームページをデータソースとして作成し、うまく回答が生成されるか検証してみたいと思います。
※執筆時点(2024-07-31)ではプレビュー版となっていますのでご注意ください。
Knowledge Bases for Amazon Bedrockについて
簡単にいうと、AWSのマネージドサービスで、簡単にRAG(検索拡張生成)が作れるサービスです。
S3などに設置したデータをソースとして、データをベクトル化して追加学習させることで、通常のLLMは知り得ないプライベートな回答を生成させたりできるようになります。
(Webに公開していない社内ドキュメント・個人情報など)
準備
・作成に必要なものは対象とするWebページのURLのみ
※Bedrockで利用するモデルの有効化処理は完了している前提で進めていきます。
詳しい手順は以下の公式ドキュメントを参照ください。
やってみる
Amazon Bedrock ナレッジベースの作成
Amazon Bedrock の左側のメニューの、「オーケストレーション」グループから「ナレッジベース」を選択し、「ナレッジベースを作成」に進みます。
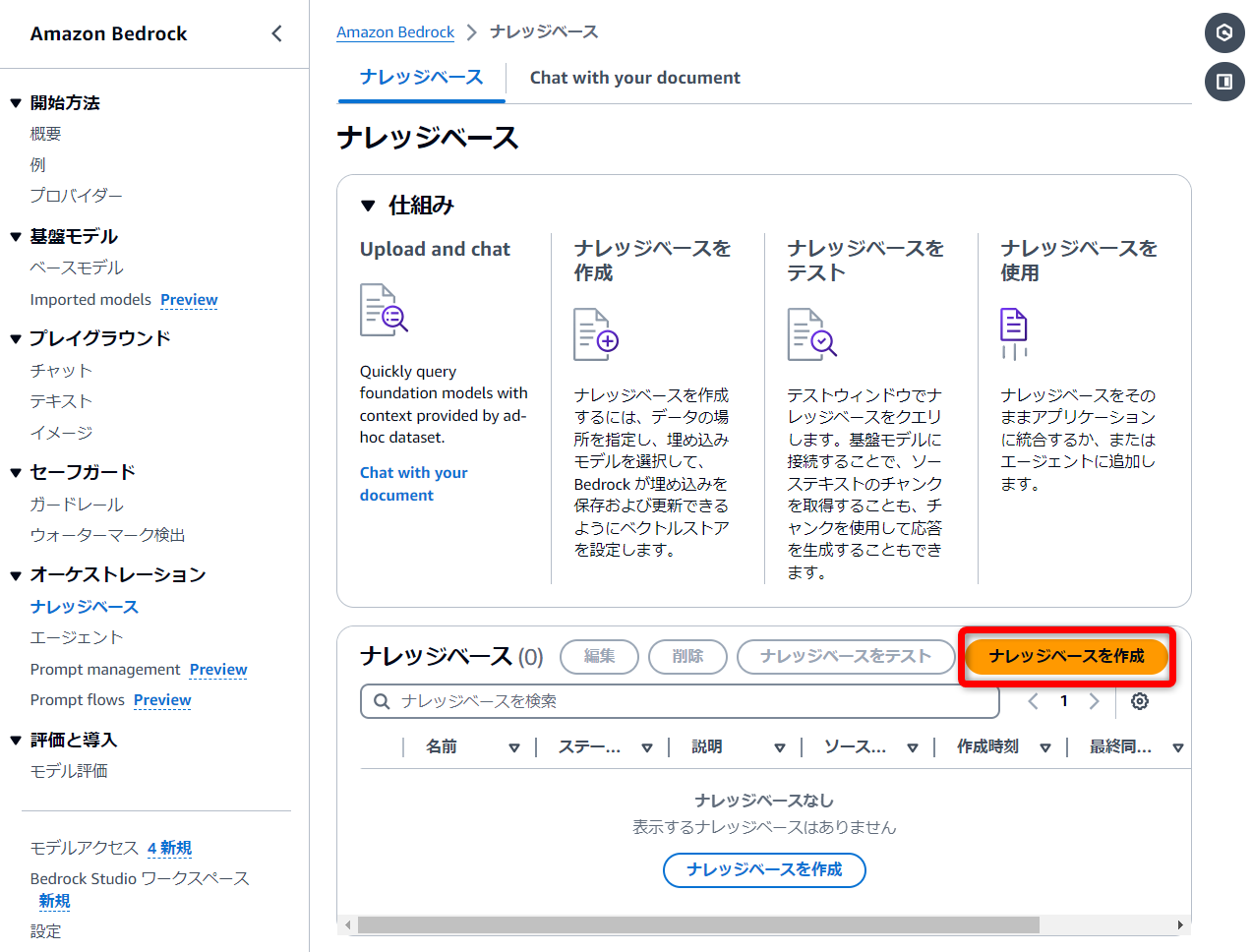
ナレッジベースの詳細
名前や説明は任意のもの
IAM 許可
デフォルトで進めると、ナレッジベースに必要なIAMポリシーとそれらが割り当てられたIAMロールが自動的に作成されます。
(モデル起動・S3アクセス等)
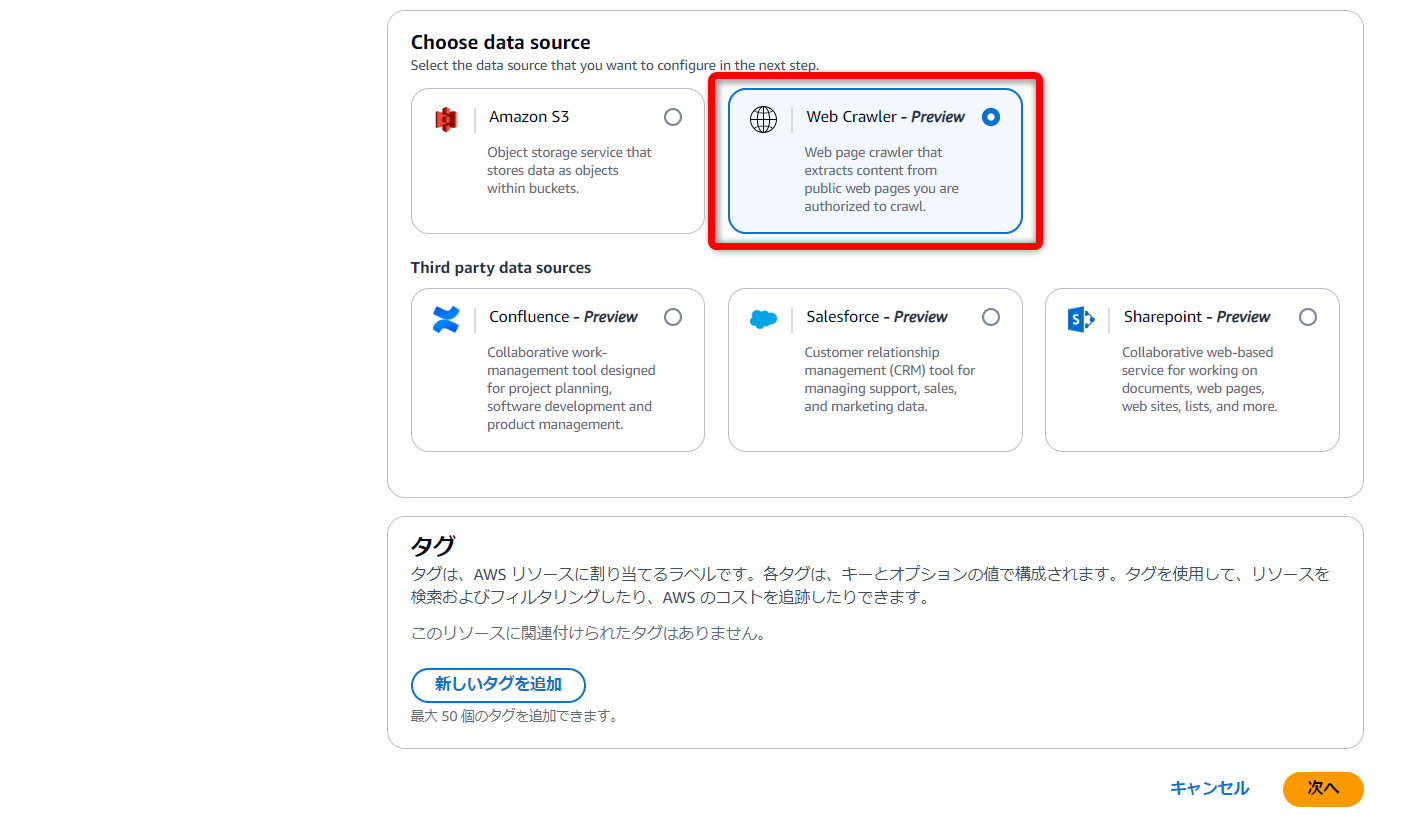
Choose data source
ここが今回のキモになる部分ですね
「Web Crawler - Preview」を選択します。
データソースの設定
名前や説明は任意のもの
Source URLs
対象となるURLを入力
最大10個まで同時に登録できるようです。
KMSキーのカスタマイズ等は行いません。
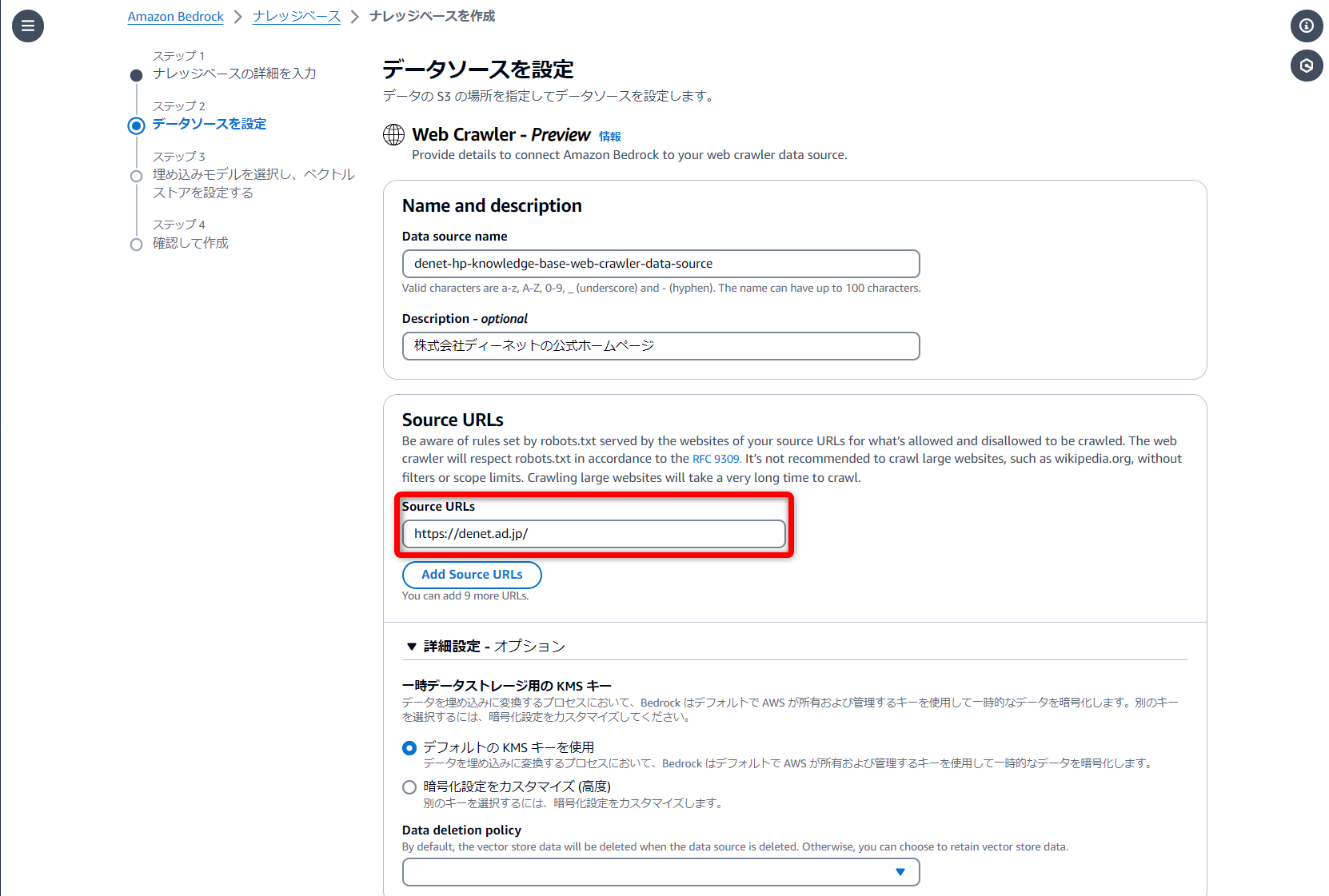
Sync scope
- Website domain range
どこまで対象URLを掘り下げるか、みたいな設定値
サブドメインまではクロールしないで欲しいので、今回は[default]で設定することにします。
(子以降のパスのみクロールする)

クロール対象となるURLのスコープに関しては、以下の公式ブログの表がわかりやすかったので、引用させていただきます。
- Default :同ホスト+子以降のパス
- Host only :同ホスト+兄弟含むパス
- Subdomains:サブドメインを含む+兄弟含むパス
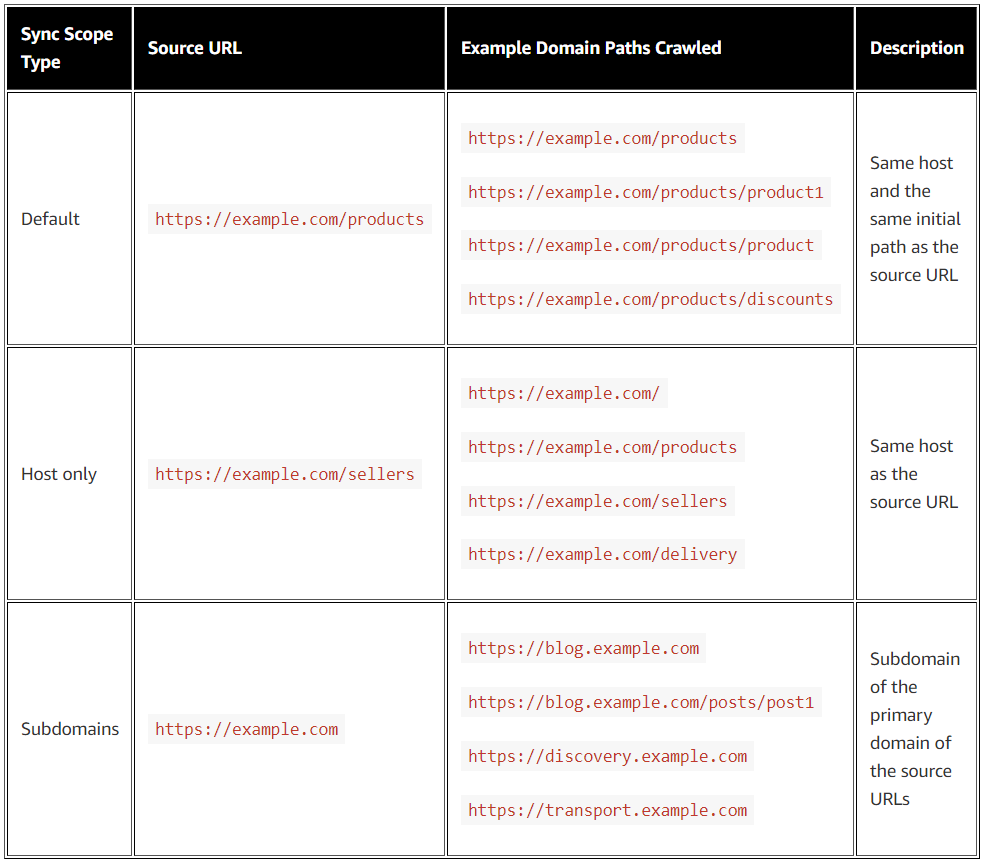
引用元:Implement web crawling in Knowledge Bases for Amazon Bedrock
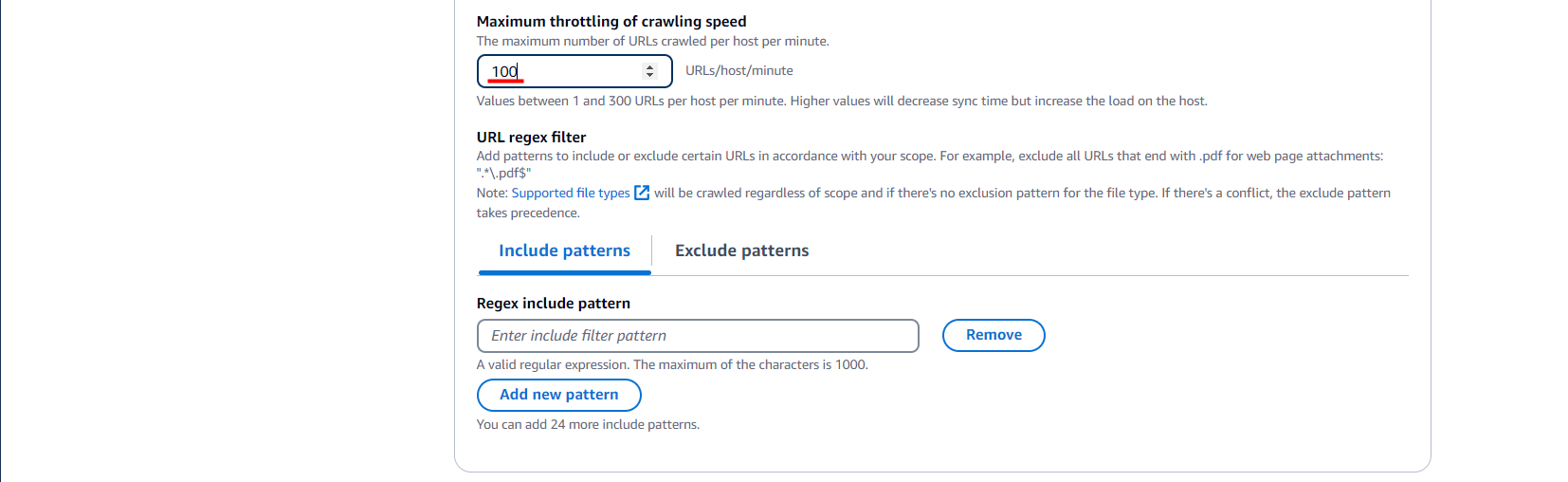
- Maximum throttling of crawling speed
1分あたりに何URL(ホスト)をクロールするかの設定値
あまり急激な負荷をかけたくない場合は値を減らして調整します。
デフォルトはMAXの[300URL/分]だったので、気持ち下げて設定してみます。
正規表現でフィルターもかけられるらしいですが、これも今回は特に触れません。
(".pdf"のみ含む/含まない とか)
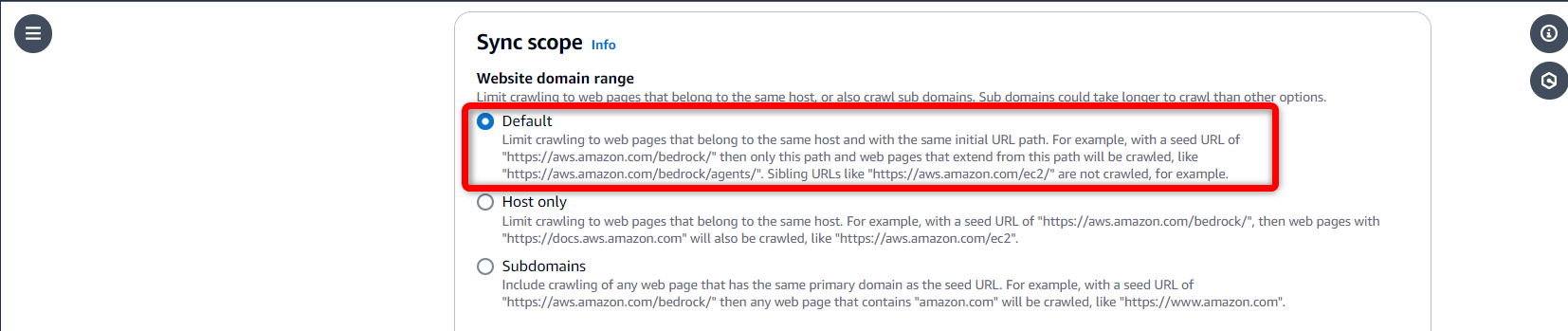
Content chunking and parsing
- Chunking and parsing configurations
チャンキング戦略を変更したり、Lambdaを使ってカスタマイズまでできるようですが、掘り下げるとこれだけで時間が溶けそうなので、デフォルトのままにします。
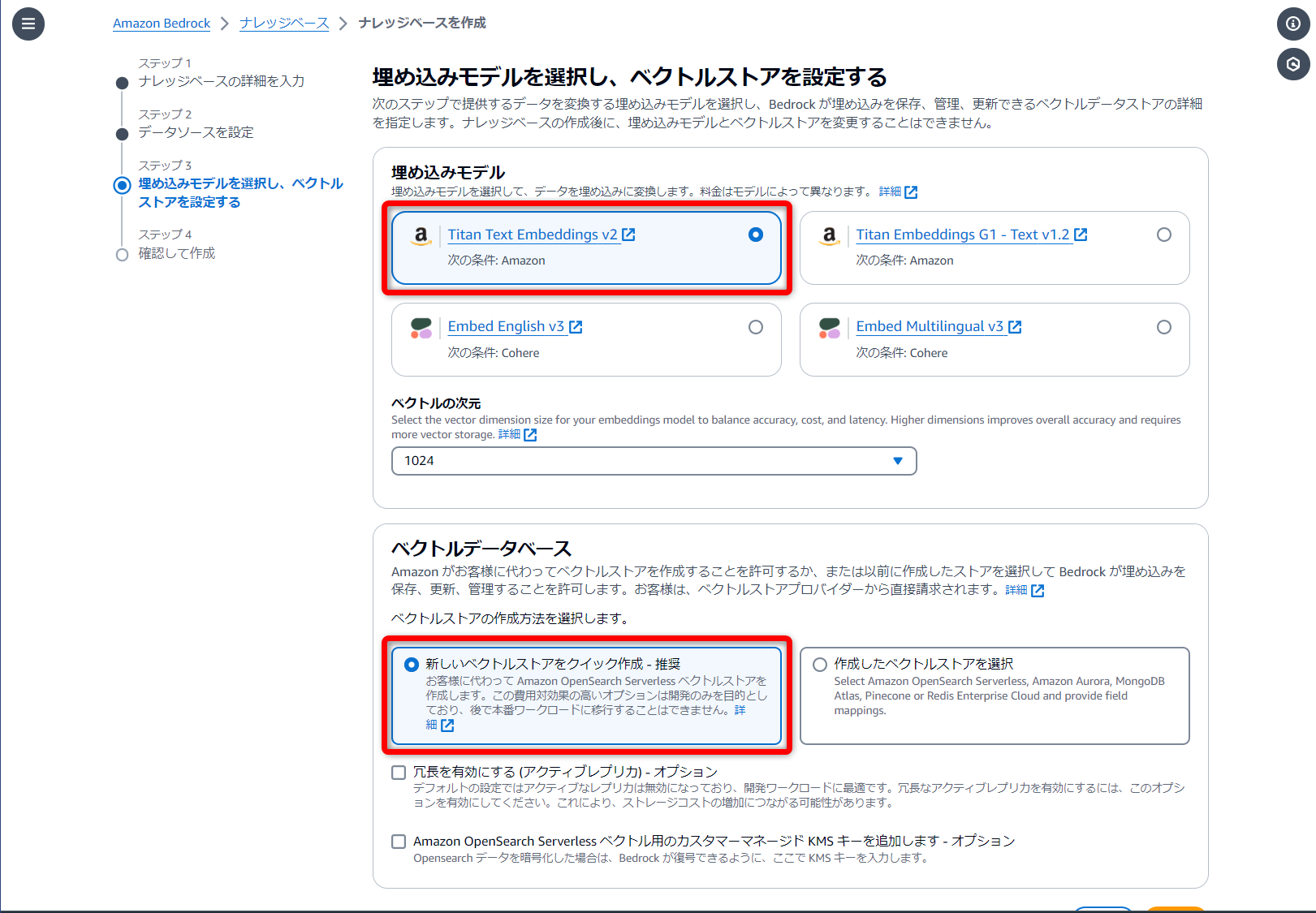
埋め込みモデル
[Titan Text Embeddings v2]を使用
ベクトルの次元はデフォルトの[1024]で進めます。
ベクトルデータベース
[ベクトルストアをクイック作成 - 推奨]を選択して、[Amazon OpenSearch Serverless 用ベクトルエンジン]を作成してもらいます。
[OpenSearch Serverless]の作成に約5分程度かかりますので、そのまま待ちます。
※この操作により作成されたOpenSearch Serverlessはナレッジベースを削除しても削除されないので、検証後は削除するようにしてください。
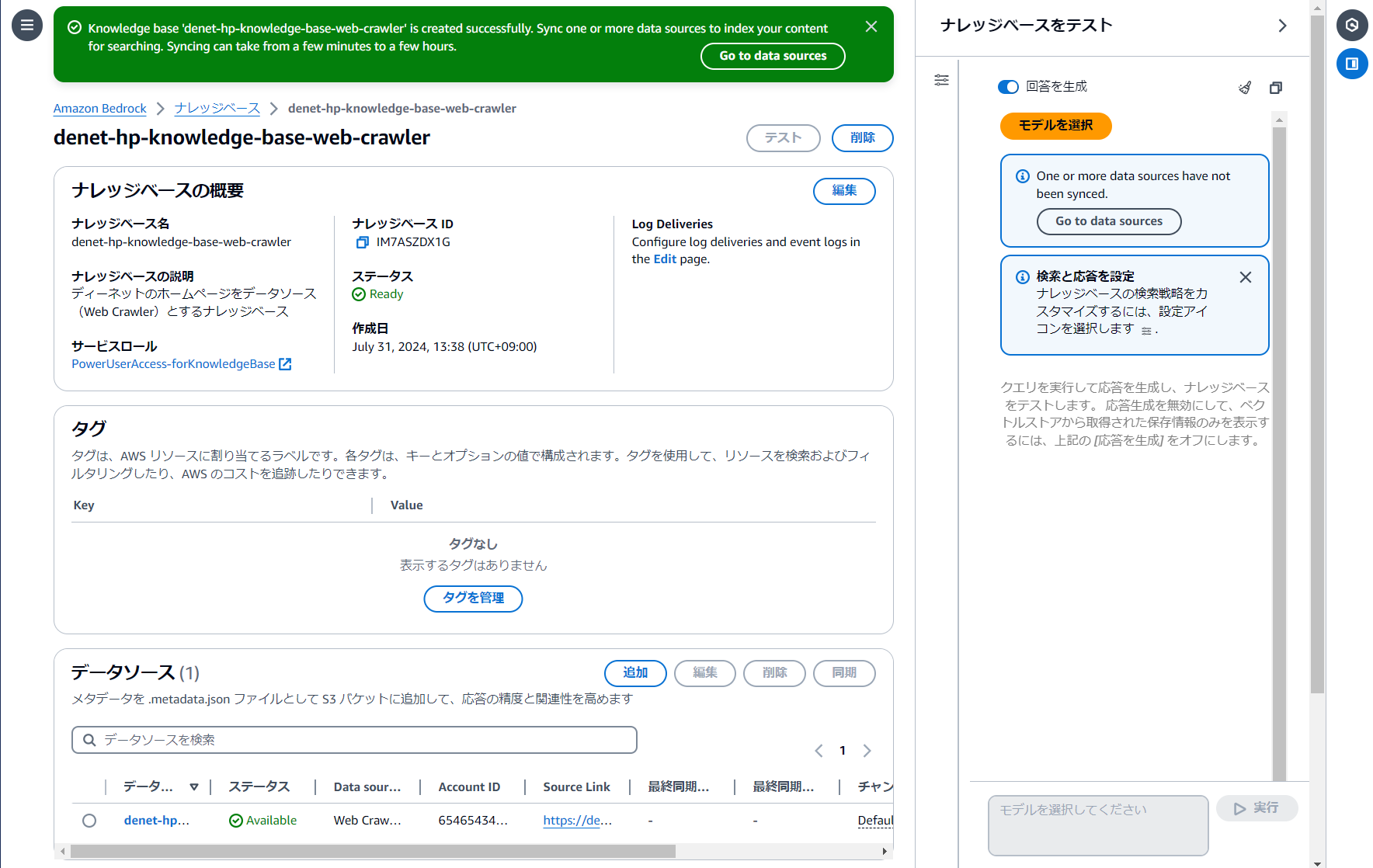
作成が完成すれば画面が遷移します。
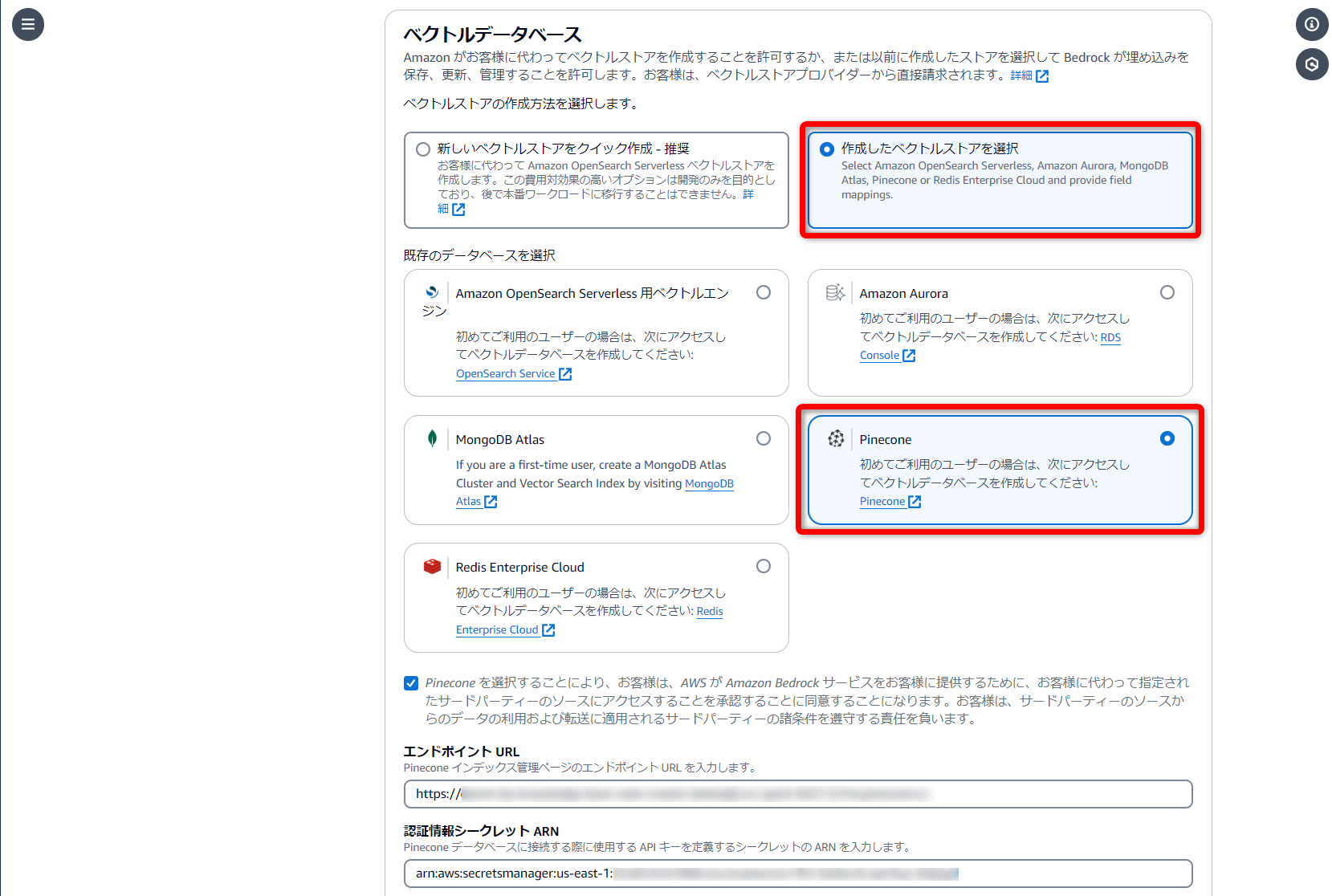
余談
軽い検証目的なので、安く済ませようと今回は[Pinecone]を採用しようと思ったんですが、データソースにウェブクローラーを利用する場合、現時点ではベクトルストアとして[OpenSearch Serverless]しか対応していないようでした。
作成完了画面までいってエラーが発生しました。🤤
(データソースをウェブクローラーにした時点で、選択できないようにしてほすぃ。)

データソースの同期
Web crawlerの同期を行います。
対象のホームページの規模感とかにもよるかと思いますが、こちらはだいたい10分程度かかりました。



ちゃんとできているのかテストしてみる
「テスト」を選択することで出てくるテストウィンドウから、回答生成に使用する任意のモデルを選択し、ナレッジベースをテストしてみます。
(設定アイコンみたいなやつ押せばウィンドウが大きくなります)
今回はテキスト生成に[Claude 3 Sonnet]を使用しています。
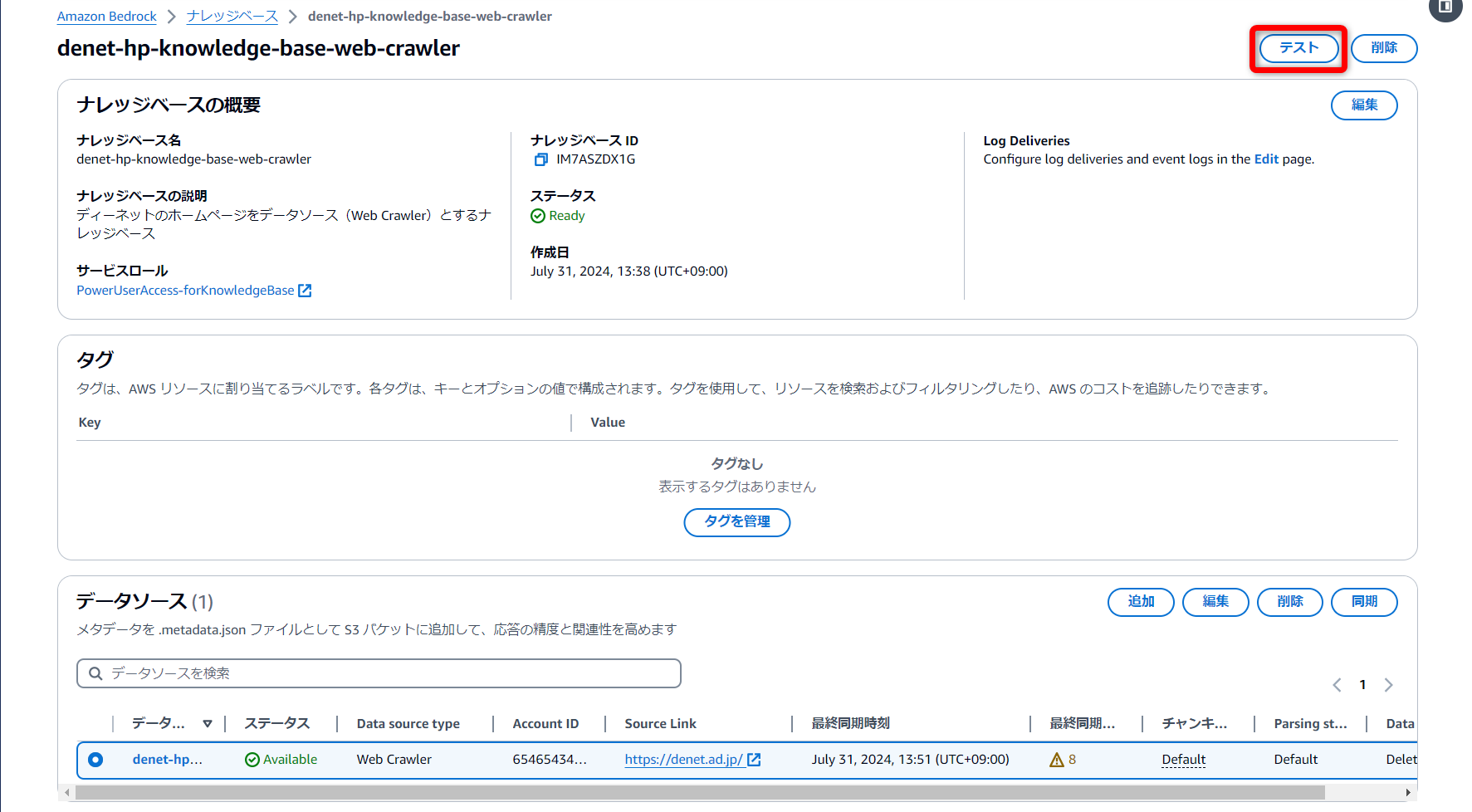
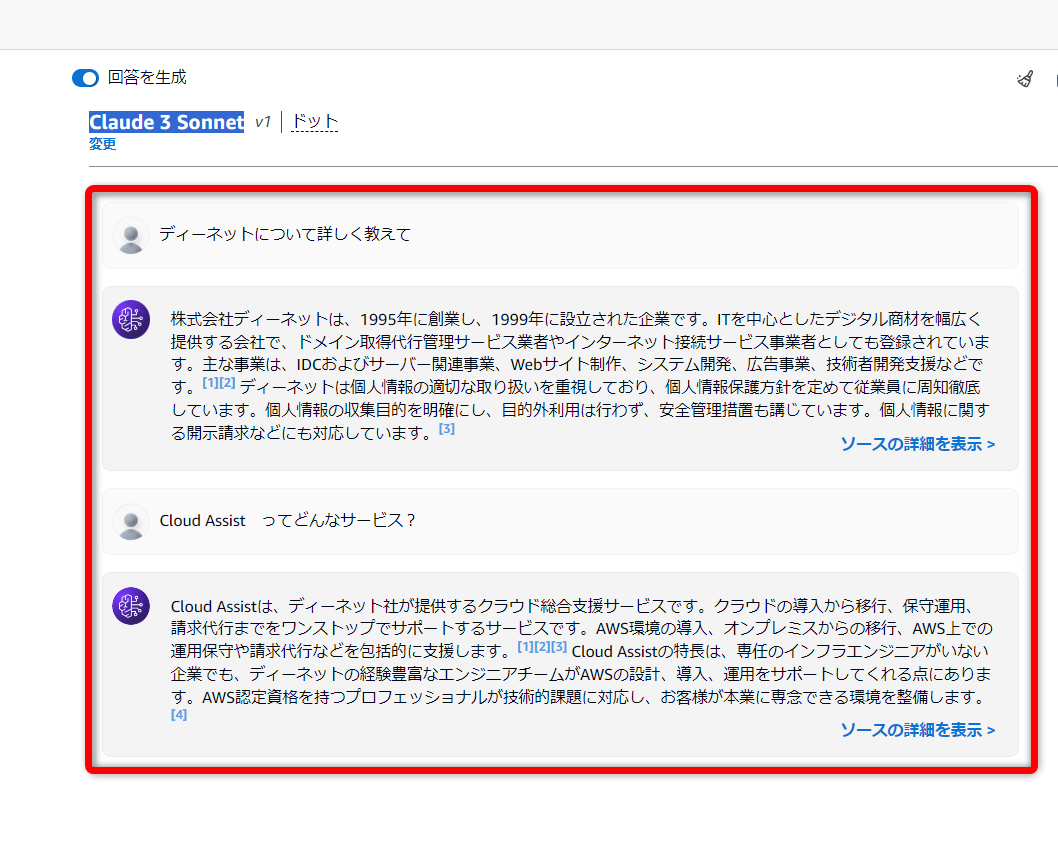
ウェブクローラーで学習させたナレッジベース
うまくいきました!!
なぜか個人情報の取り扱いに関するウェイトが大きいですけど、問題なく情報を取得できているようです😌
弊社が提供しているサービス名についても聞いてみましたが、こちらもちゃんと回答してくれました。👏
あとは、エージェントと組み合わせて回答の精度を上げたりフォーマットを整えたりして、アプリケーションと組み合わせることで、実際のサービスにも利用できるような気がしました。
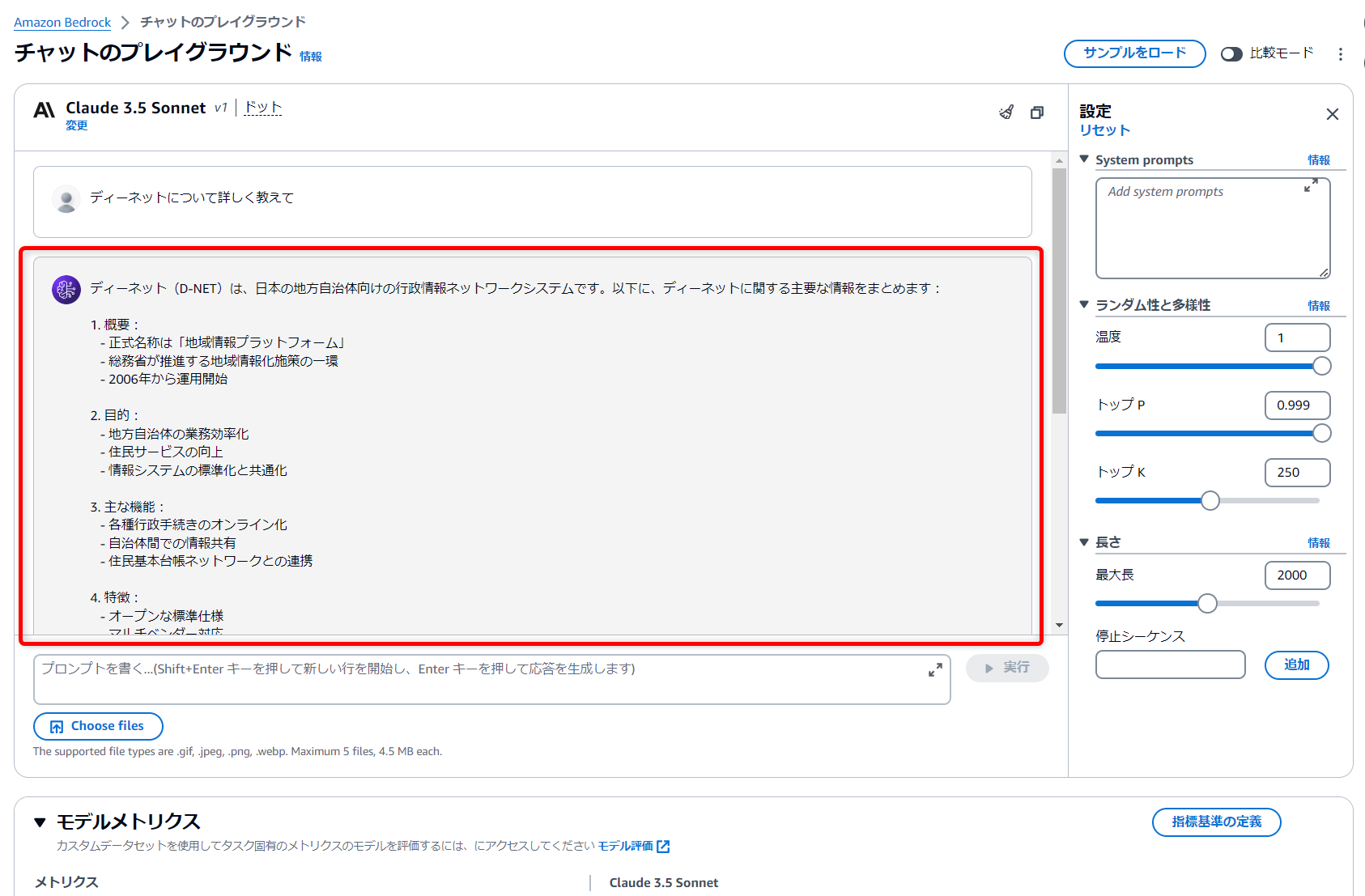
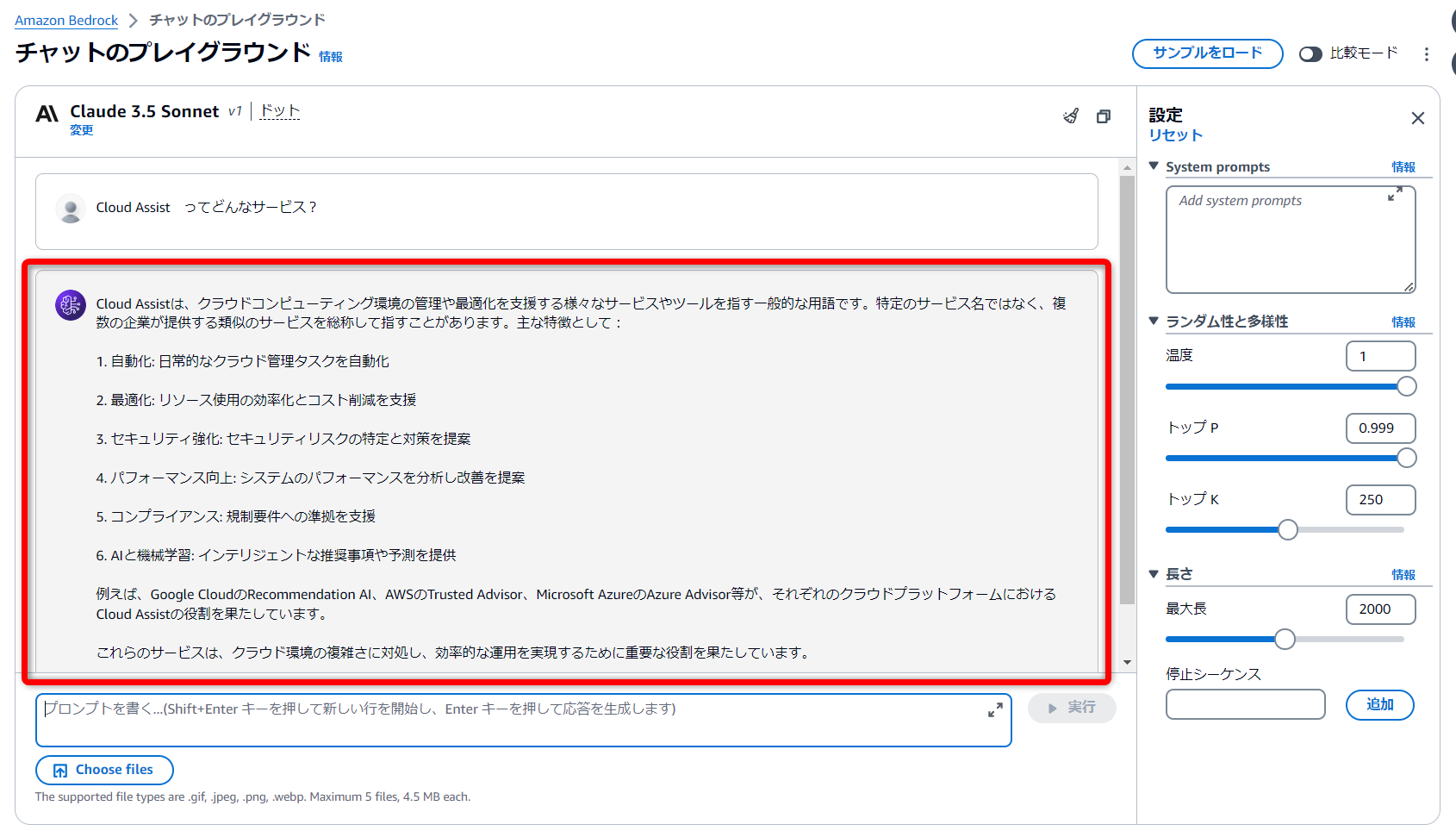
プレーンで未学習のLLMで確認
Bedrockのプレイグラウンド機能から、プレーンなLLMを利用して比較してみました。
予想通りですが、会社に関することや、弊社のサービスについても学習されておらず、期待する回答は得られませんでした。
感想
簡単すぎてビックリ。
やっぱりAWSのサービスだけで簡単にサクッとRAGが作れちゃうのはめちゃくちゃいいですね。
Webページの中で必要な情報を探すのって、サイトの構造によっては結構骨が折れることがあると思うんですが、このように自然言語で検索・チャットができると非常に便利だと感じました。
最後までお付き合いいただきありがとうございました~!

好きなこと:音楽、猫、お酒、ゲーム、効率化
経歴:テレビ業界AD → 通信回線販売代理店 → IT関連職業訓練 → 株式会社ディーネット
ちょうど試そうとしていたので、勉強になりました。