
目次
ごあいさつ
寿司!(挨拶) もに倉です。
今回は、先日発生した大規模障害での謎に迫ります。
詳しく言うと、障害の対象となったアベイラビリティゾーンについてを解説します。
そもそも、アベイラビリティゾーンとは?
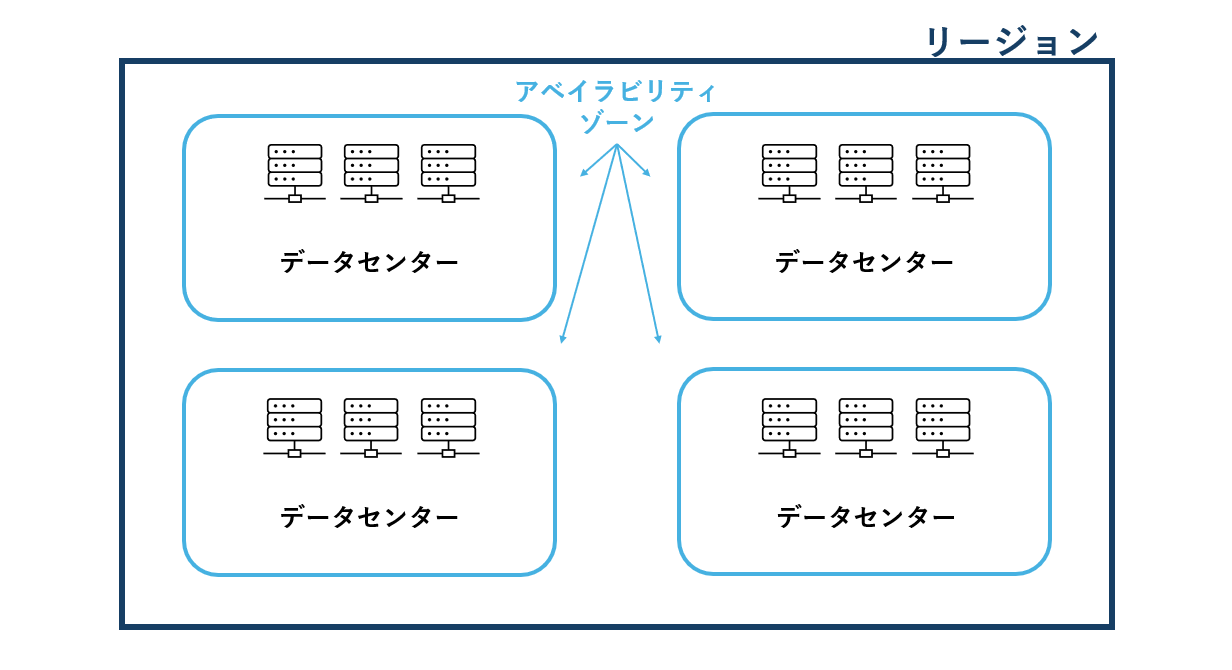
アベイラビリティーゾーン
https://docs.aws.amazon.com/ja_jp/whitepapers/latest/aws-fault-isolation-boundaries/availability-zones.html
アベイラビリティーゾーンは、AWS リージョン内で独立した冗長な電源設備、ネットワーク、接続を備えた 1 つ以上の個別のデータセンターです。
というわけで、同じリージョン内に存在するデータセンターをいくつかまとめて
アベイラビリティゾーン(以降AZとする)と称しています。
図にすると↓というかんじ
もっとわかりやすい(と一説では評されている)図はコチラ
{kind=link}
よく見るAZ
AWSを利用しているといやでも仲良くしないといけないAZ。
よく見かけるのは、東京リージョンの「ap-northeast-1a」や「ap-northeast-1c」でしょうか。
ほかにも、バージニア北部リージョンでは「us-east-1a」など、
「【リージョン名】a」といったような命名規則で名づけられているようですね。
EC2建てるときなど、AWSで何かしら作ろうと思ったらだいたい目に入ってきます。
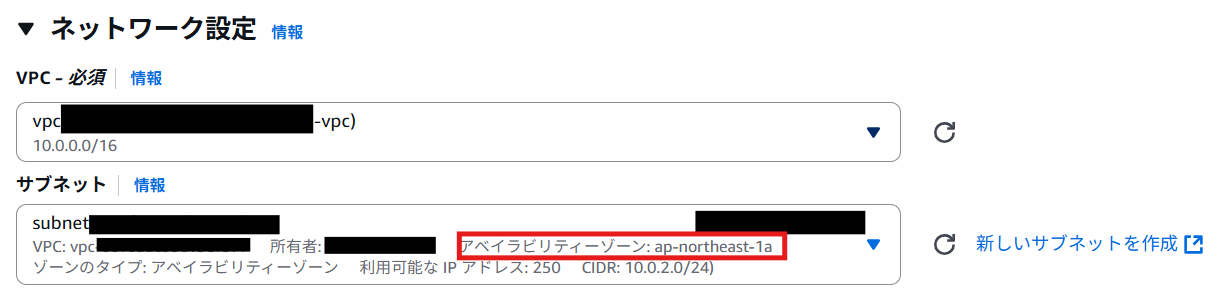
大規模障害で見たAZ
さて、それでは先日(2025/2/28)に発生した大規模障害についての通知文を見てみましょう。
AP-NORTHEAST-1リージョンの単一アベイラビリティゾーン(apne1-az4)のEC2インスタンスのサブセットに接続性の問題が発生しました。
これは、影響を受けたEC2インスタンスへのプライマリおよびセカンダリ電源が遮断された問題の結果でした。
この間、影響を受けたEC2インスタンスを使用する他のAWS APIとともに、
影響を受けたゾーンで起動したインスタンスのエラーレートとレイテンシが増加した可能性があります。
エンジニアは数分以内に自動的に対応し、直ちに緩和策の調査を開始しました。
この問題が再発することはありません。
残りの少数のインスタンスは、電源喪失によって悪影響を受けたハードウェア上でホストされています。
影響を受けたすべてのインスタンスとボリュームの復旧に引き続き取り組みますが、早急な復旧のためには、
可能であれば、影響を受けた残りのインスタンスまたはボリュームを交換することをお勧めします。
この問題は解決され、サービスは正常に稼働しています。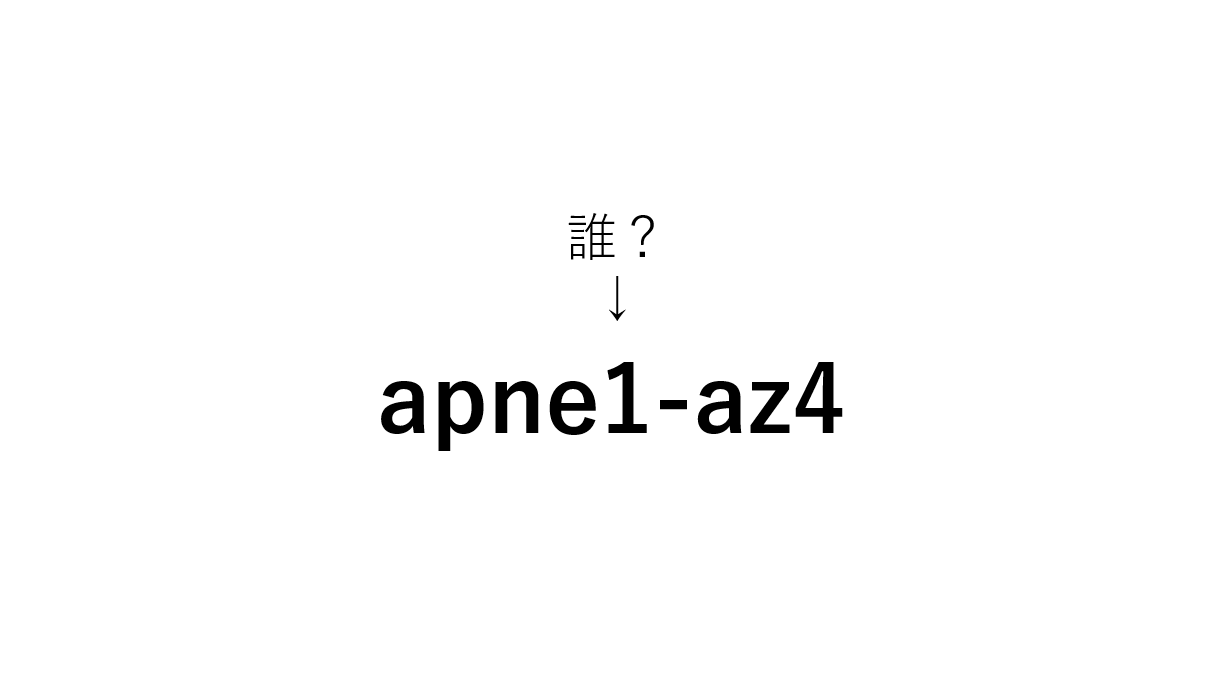
フツーに知らん人出てきました。びっくりしました。
大規模障害発生時は、このAZの存在を知るエンジニアに囲まれていたため
「あー、apne1-az4ね。はいはい、知ってますケド……」
という顔をしていましたが、フツーに知らん人でした。
私が知っているAZは「【リージョン名】a」というきれいな名前であって、こんなに無骨な名前じゃない……!!
apne1-az4って誰なの?!
結論から言うと、こいつは「AZ-ID」というもので、AZを一意に識別するためのものでした。
実は、見知ったAZ(「【リージョン名】a」など)はアカウントごとに使用しているデータセンターが違うようです。
同じ「【リージョン名】a」でも、アカウントAとアカウントBでは違うデータセンターを使っている・ということです。
一方で、AZ-IDはどのアカウントから見ても同じデータセンター。
「apne1-az4」はアカウントAから見たら「【リージョン名】a」だけど、
アカウントBから見たら「【リージョン名】d」である
ということみたいですね。
言葉にしてもわかりづらいよ~~;;
ということでわかりやすい図↓
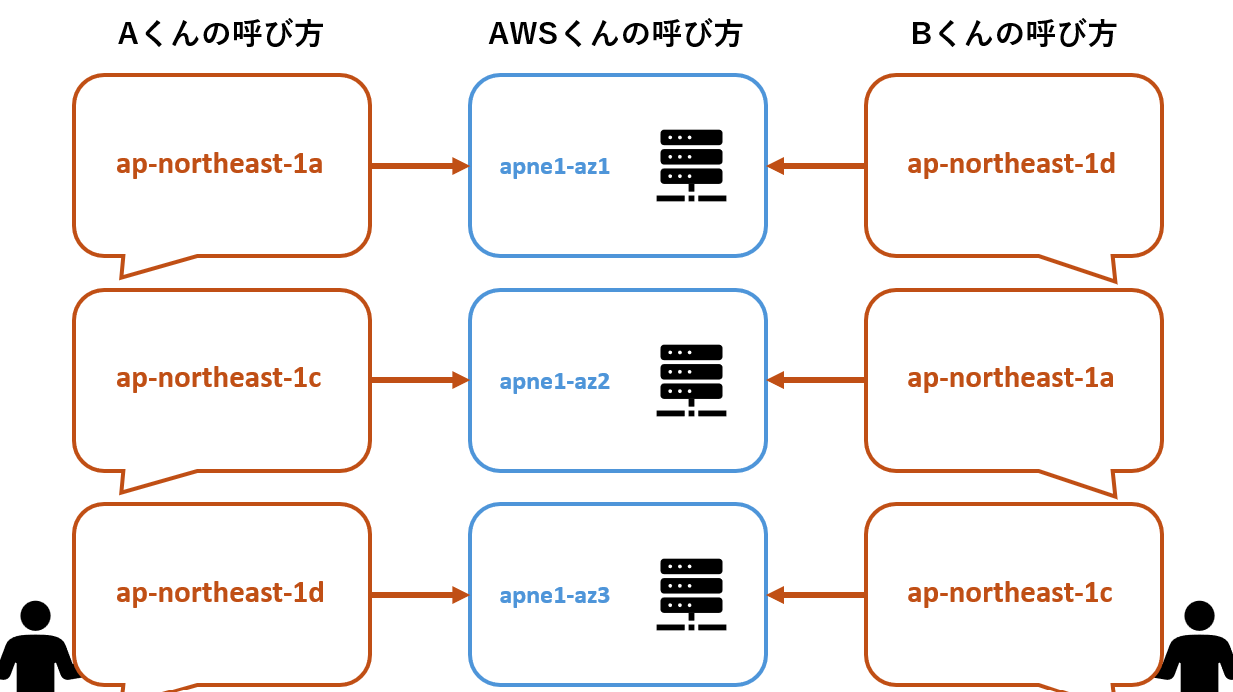
下の方切れちゃったネー
大規模障害の影響を受けたAZを確認してみる
じゃあ、うちのアカウントで大規模障害の影響を受けたAZは結局どこだったの?!
ということで、確認してみました。
EC2のコンソール → ダッシュボード へ……
※確認方法はいくつかあるのかなー・と思いますが、個人的にこれがいちばん早いと思います。
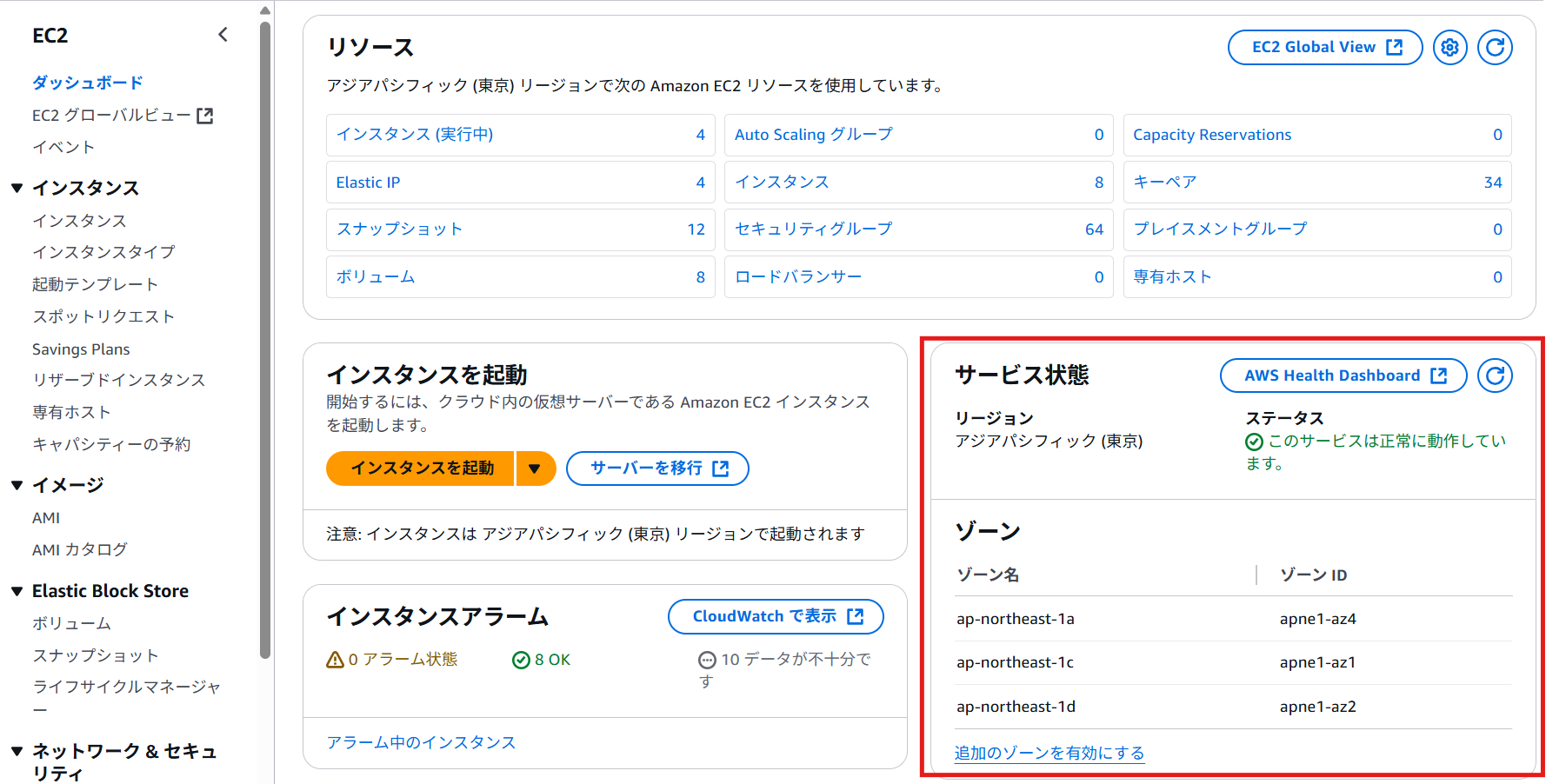
対応表がありました! わかりやすいね。
このアカウントで言うと、大規模障害の影響を受けたAZは「ap-northeast-1a」だったみたいです。
あとがき
またひとつ賢くなったね

たまごのひび割れから身が見え始めたエンジニア。