
目次
はじめに
こんにちは、omkです。
お盆休みもついに終わってしまいましたね。
ところで、皆さんはお盆休みに何かしましたか?
田舎に帰省ですか?海外旅行ですか?いいですねぇ。
私はタイムトラベルしていました。
Apache Icebergのタイムトラベルとは
Apache Icebergではテーブルの更新のたびに状態が都度スナップショットに記録されています。
つまり有効期限内のスナップショットを利用することで特定時点のテーブルに対してクエリすることが出来ます。
タイムスタンプを指定する方法とスナップショットのバージョンを指定する方法がありますが、
本記事では面倒くさいので両方タイムトラベルと呼ぶことにします。
やってみた
Icebergのテーブルを更新してタイムトラベルクエリを実行することで、現在と過去で異なる結果が得られること、過去の状態に戻せることを確認していきます。
まずIcebergのテーブルを準備します。最近良く使ってるテーブルで実施します。
テーブルの作り方はこちらに記載していますのでよければご参照ください。
Glue Data CatalogのテーブルをApache Icebergに対応させてみた
Athenaのクエリエディタを起動します。
(Athena PySparkでもやりたかったのですがおそらく対応していない?のでAthenaエンジンでやります)
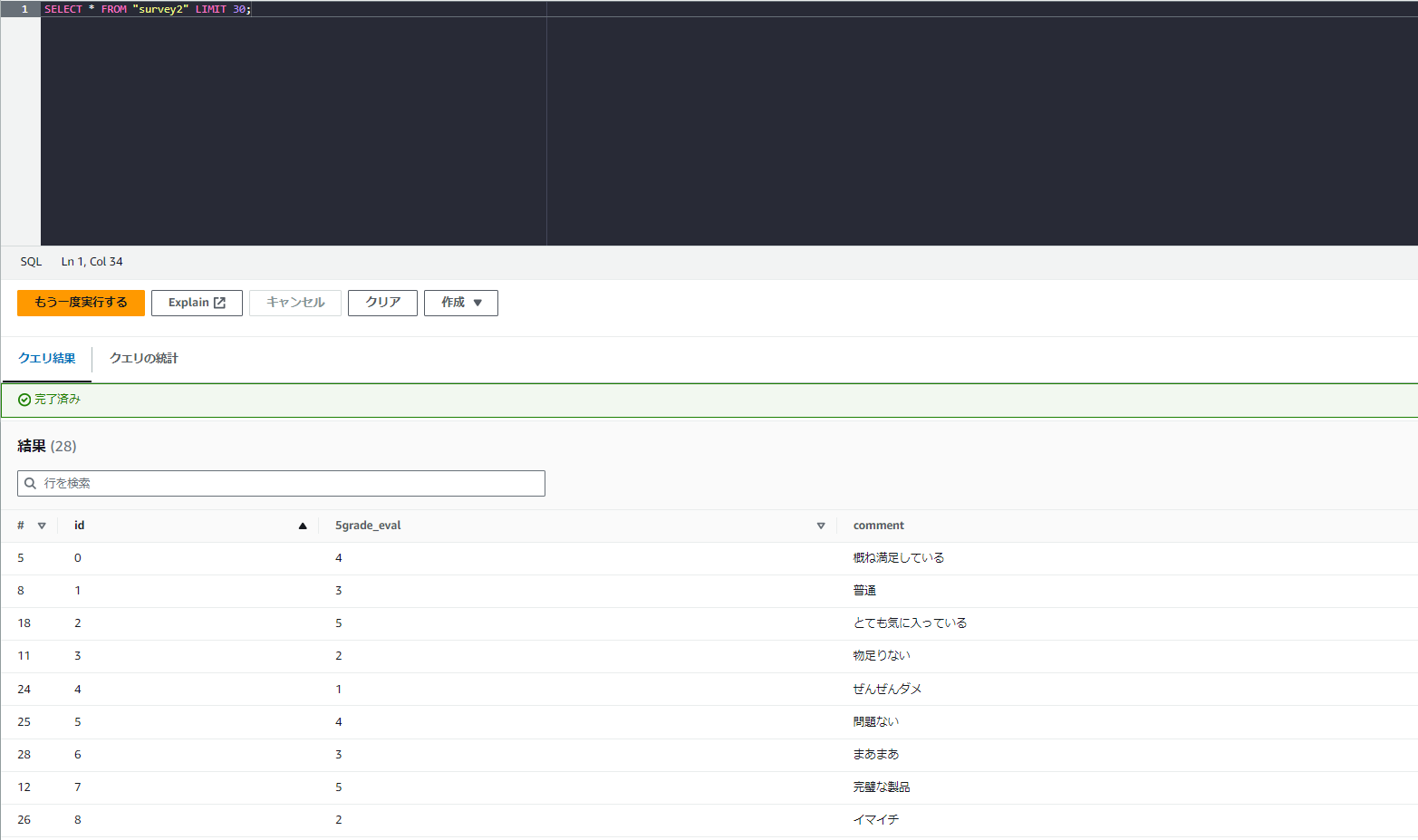
「survey2」というテーブルを利用します。
id、5grade_eval、commentという3つのカラムで構成されるテーブルで、レコードが20個程度入っています。
AthenaでのIceberg周りの操作は以下のドキュメントに記載があります。
こちらのほうが包括的に書かれていますので合わせて御覧ください。
Query Iceberg table data
Iceberg テーブルデータのクエリの実行
更新の履歴は以下のように記載します。
SELECT * FROM "dbname"."tablename$history"
実行してみます。
SELECT * FROM "survey2$history" limit 30;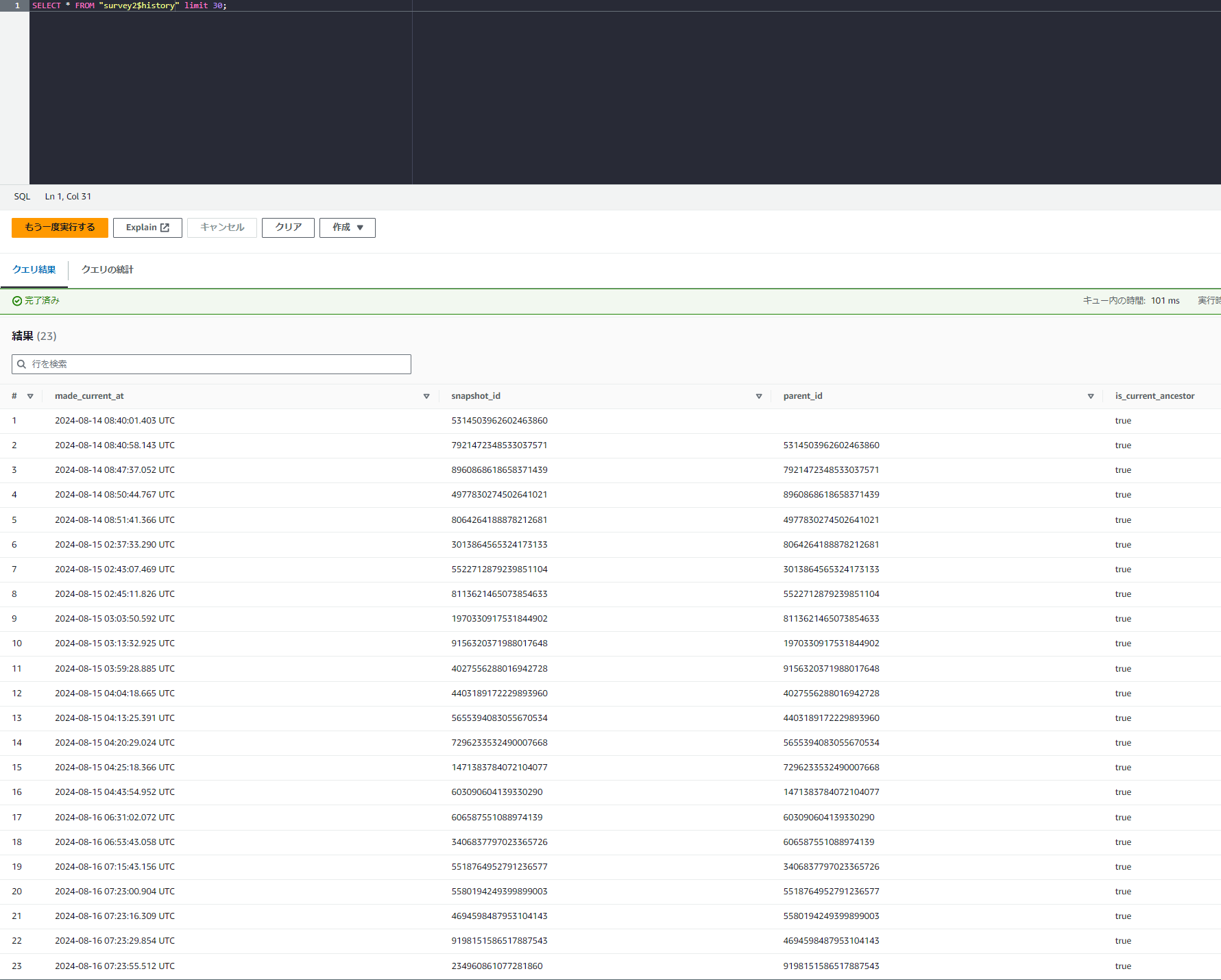
スナップショットの作成された時間やIDが出力されました。
誤ってレコードをすべて消してみます。
DELETE FROM "survey2" ;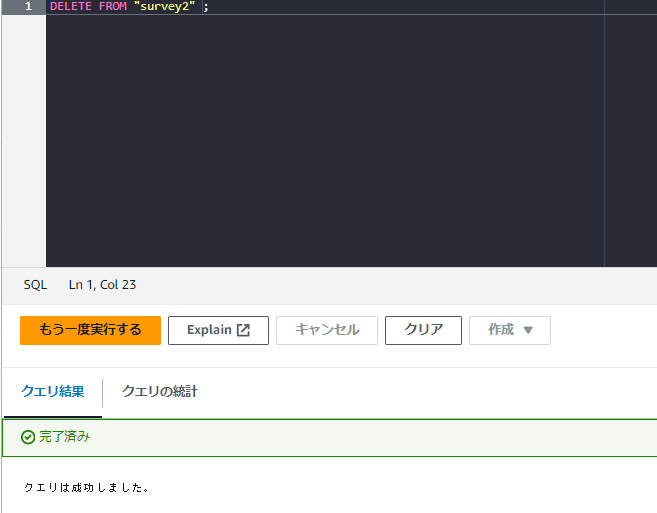
テーブルが空になってしまいました。そんなつもりじゃなかったのに……よよ……
SELECT * FROM "survey2" limit 30;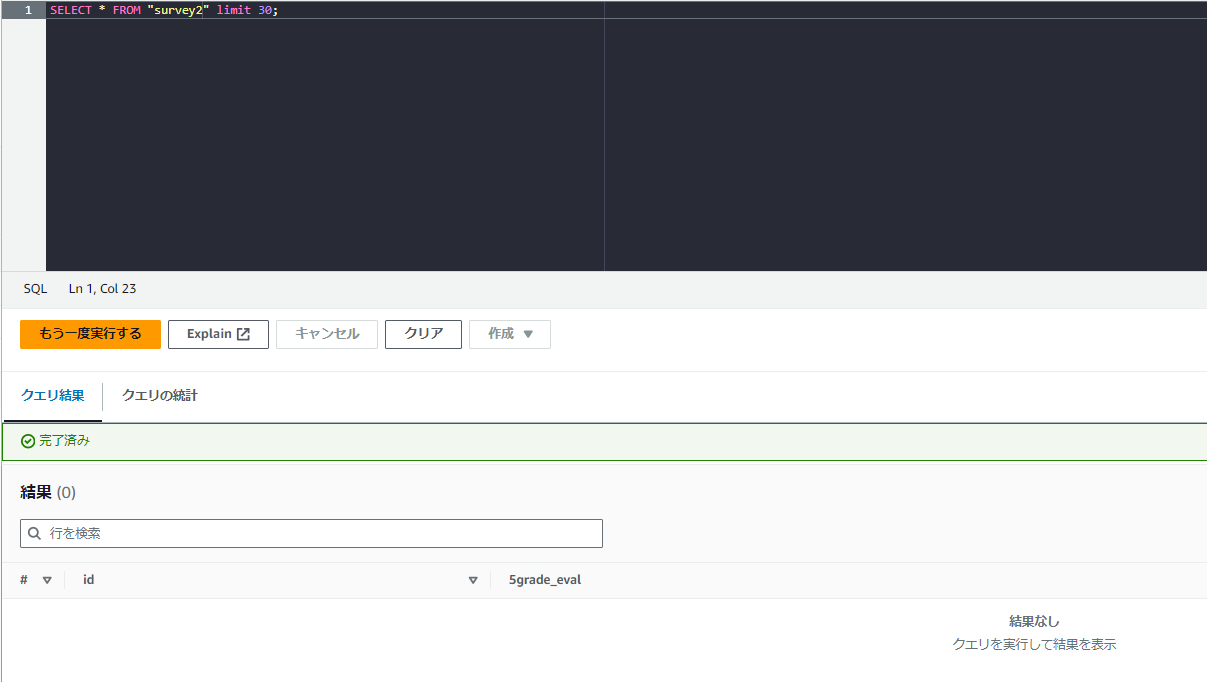
では頑張って消してしまったレコードを復旧していきます。
まずは変更前のスナップショットからタイムトラベルクエリを実行します。
SELECT * FROM iceberg_table FOR TIMESTAMP AS OF timestamp
もしくは
SELECT * FROM [db_name.]table_name FOR VERSION AS OF version
のように時間やスナップショットIDを指定することでその時点のテーブルにクエリ出来ます。
※SQLは先程のAWSのドキュメントから引用
それではやってみます。
SELECT * FROM "survey2" FOR VERSION AS OF 234960861077281860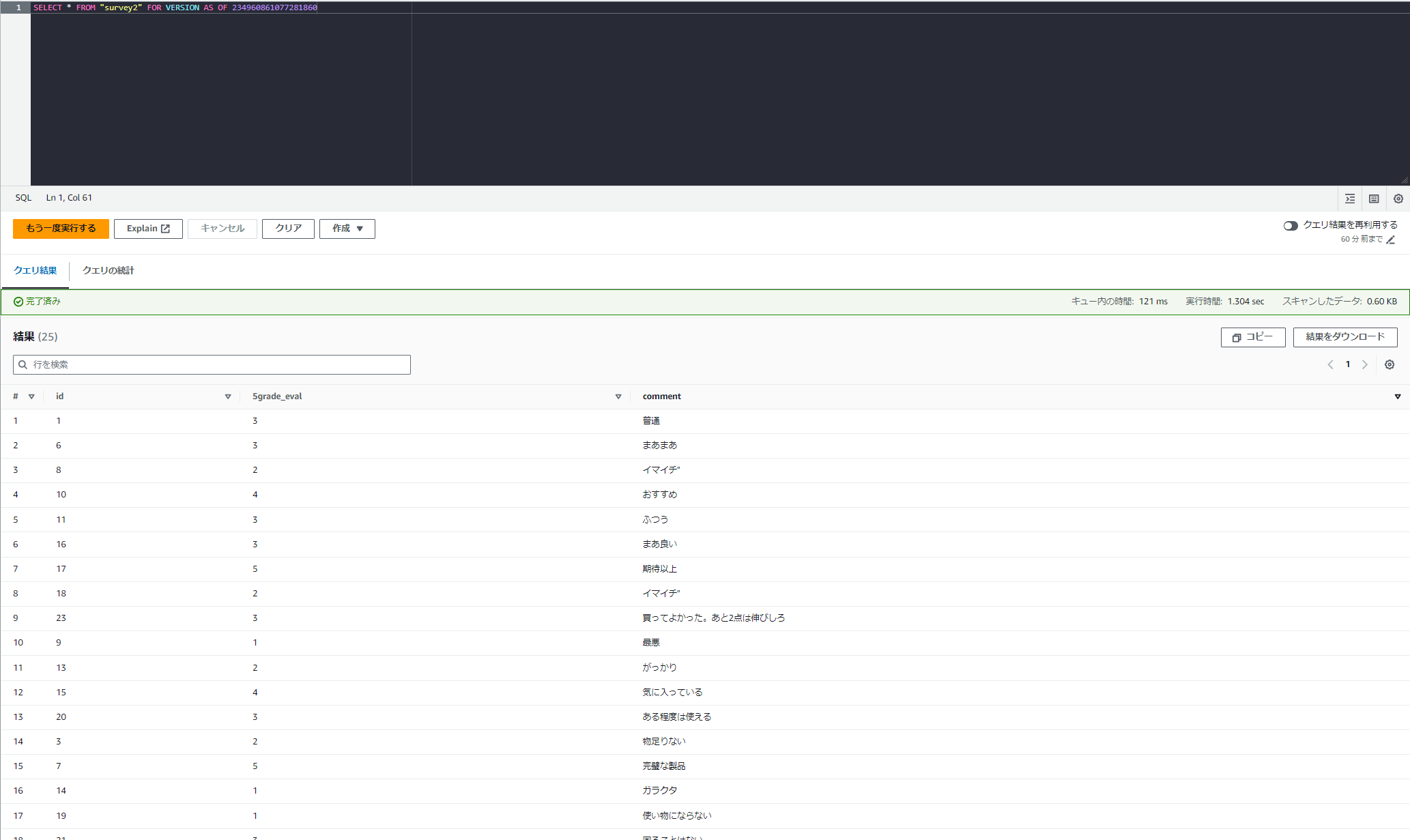
過去の状態のテーブルが記録されていました。
では、これを用いてこの時点の状態にテーブルを戻していきます。
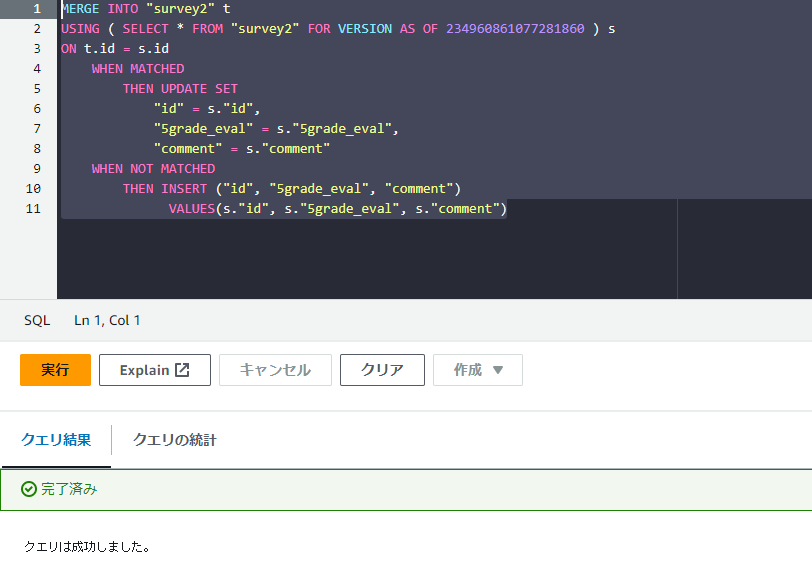
MERGE INTO "survey2" t
USING ( SELECT * FROM "survey2" FOR VERSION AS OF 234960861077281860 ) s
ON t.id = s.id
WHEN MATCHED
THEN UPDATE SET
"id" = s."id",
"5grade_eval" = s."5grade_eval",
"comment" = s."comment"
WHEN NOT MATCHED
THEN INSERT ("id", "5grade_eval", "comment")
VALUES(s."id", s."5grade_eval", s."comment")レコードを全消ししたのでそのままINSERTしてしまっても良かったのですが、部分的に消していたり、条件が複雑だったりの場合に向けてMERGE INTOで書き戻します。
現在の「survey2」テーブルに過去バージョンの「survey2」テーブルを使ってidが一致すれば過去バージョンで上書き、現在の「survey2」テーブルにないidが過去バージョンにあれば新規挿入、という内容です。
書き戻されたことを確認します。
SELECT * FROM "survey2" limit 30;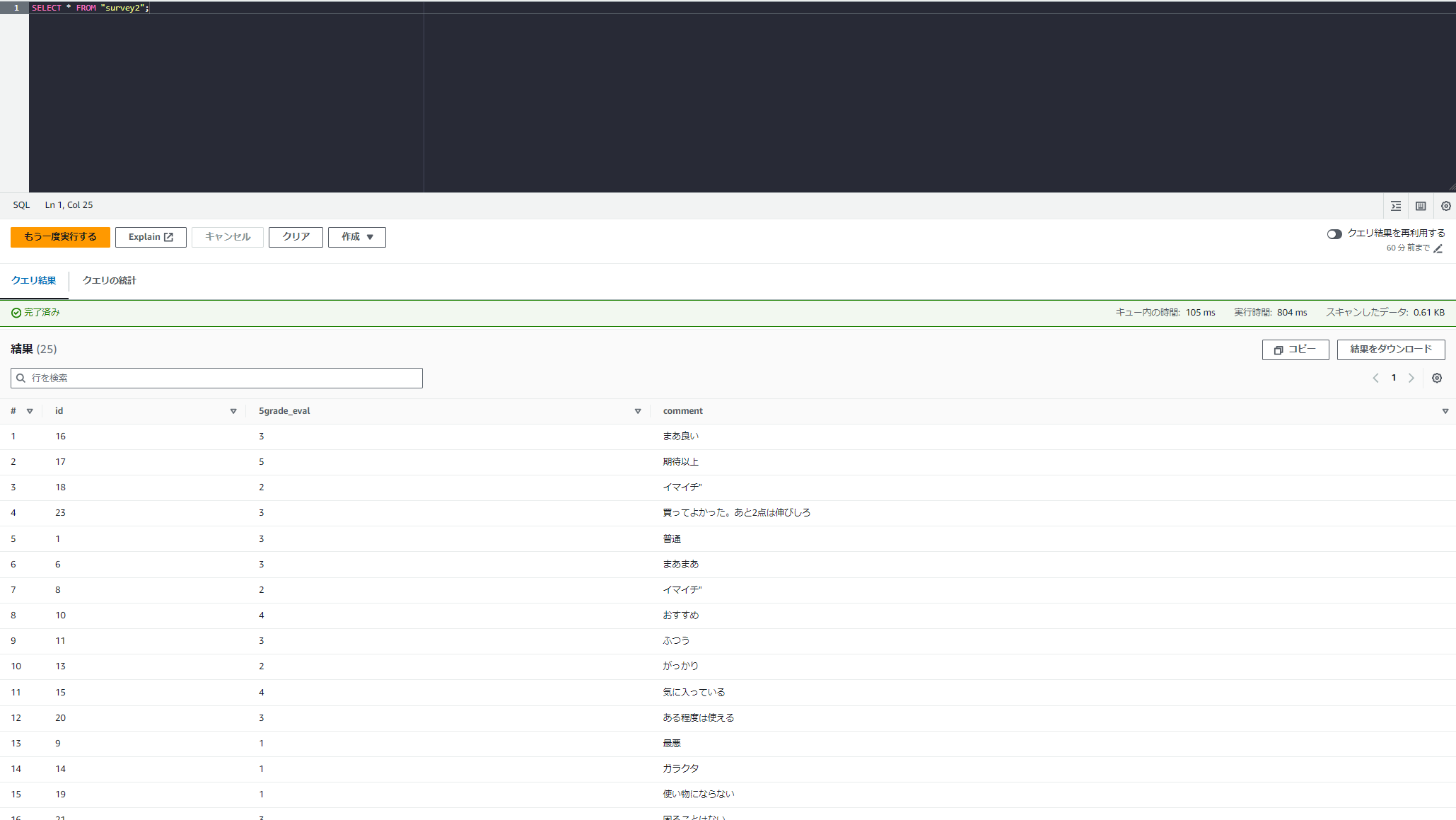
無事戻りました。
※追記(2024/09/02)
rollback_to_snapshot
ちゃんとロールバック用にプロシージャが用意されていることを初めて知り、大変勉強になりました。ありがとうございます。
ですが、調べてみたところ現時点でAthenaでは対応していないようで結局Athenaで操作しようと思うとこのような実装になりそうです。
↓参考↓
Athena を使用して Apache Iceberg テーブル エラーをトラブルシューティングするにはどうすればよいですか?
注意:テーブルをロールバックするには、Athena クエリエディタではなく、AWS Glue や Amazon EMR などの Spark 環境を使用する必要があります。
テーブルを特定のスナップショット ID にロールバックするには、次のようなApache Iceberg コマンドroll_to_snapshotを実行します。
CALL catalog_name.system.rollback_to_snapshot('your-db.your-table', your-snapshot-id)
※引用文はGoogle Translateにて翻訳したものを記載しています。
おわりに
データレイクに直接クエリしていると割と以前の状態を参照したいときがあり(変なデータが流れて来てテーブルがおかしくなったり)、
こういうことが出来るといいなーと思っていたので丁度いい感じにできました。
以上、最後までお付き合いありがとうございました。

アーキテクト課のomkです。
IoTが主食です。