
目次
はじめに
お疲れさまです、寺井です。
re:Invent 2024 最高でしたね!!
日本に帰ってきたら、行ったときよりもめちゃくちゃ寒くなっててびっくらこきました。
いよいよクリスマスやで…。🎅
re:Inventの熱気がまだ冷めやらぬ中、DENETアドカレ2024の12/13担当として、期間中に発表された「Bedrock」の新機能をピックアップしてご紹介します!💪
新機能:Amazon Bedrock ナレッジベースが構造化データ取得をサポートするようになりました
「Amazon Bedrock Knowledge Bases」の新機能として、構造化データ(「Redshift」など)にクエリを実行する機能が追加されました!
構造化データへのクエリ結果から回答を行うようになるため、似通った(意味的に近い)検索結果を使用することなく、ハルシネーションの軽減などが見込めそうです。
RAG大好き人間としては放っておけないので、実際に試してみようと思います!!✊️
前提と準備
本作業の全般は“us-east-1”リージョンにて実施しています。
試す際は、適宜使用するリージョンに読み替えてください。
今回試す構成について
「Bedrock Knowledge Bases」のデータソースとして「Redshift」を使用する構成とします。

以下のWhat's Newでは、『~~「SageMaker Lakehouse」もサポート対象~』とありますが、執筆時点(2024/12/12)では「Redshift」しか選べませんでした。
そもそも「SageMaker Lakehouse」というサービス自体re:Invent期間中に発表された新機能なので、ガッチャンコが間に合ってない感じなんですかね?🤔
Bedrock Knowledge Bases supports structured data retrieval from Amazon Redshift and Amazon SageMaker Lakehouse at this time and is available in all commercial regions where Bedrock Knowledge Bases is supported.
Amazon Bedrock Knowledge Bases now supports structured data retrieval - AWS
Bedrockにて使用するモデルアクセスの有効化
以下ドキュメントを参考に、「Knowledge Bases」にて回答生成に使用したいモデルアクセスを有効化しておきます。
テストデータの準備(Redshiftに保存してBedrockからクエリさせる情報)
今回はCSV形式で、ユーザのプロフィール情報のようなテストデータを用意しました。
| id | name | aws_certifications | skills | hobbies | created_at | |
|---|---|---|---|---|---|---|
| 1 | 山田太郎 | taro.yamada@example.com | SAA, AIF | Python, AWS Lambda, Redshift | ゲーム, 読書 | 2024-12-08 |
| 2 | 鈴木花子 | hanako.suzuki@example.com | DAS | SQL, ETL, Data Pipeline | 料理, 写真 | 2024-12-09 |
| 3 | John Doe | john.doe@example.com | DOP | Docker, CI/CD, CloudFormation | 旅行 | 2024-12-10 |
※Redshiftで“date”型を使用する場合、日付は“YYYY-MM-DD”形式である必要があります。
(適切な形式でない場合、テーブルへのデータインポート時にエラーが発生します)
S3バケットの作成とデータアップロード
後からRedshiftにデータをロードできるように、適当なS3に先ほど用意したテストデータをアップロードしておきます。
後ほど、このアップロードしたファイルのS3 URIを使用しますので、コピーしておきます。
例)s3://{バケット名}/{パス}/{ファイル名}.csv
やってみる
「Redshift Serverless」の作成
ワークグループを作成
Amazon Redshift Serverless > サーバーレスダッシュボード > [ワークグループを作成] へと進みます。
「Redshift」のコンソールからServerlessへ進んだ場合、初回構築時はワンクリックセットアップのような画面が出ますが、今回は使用しません。
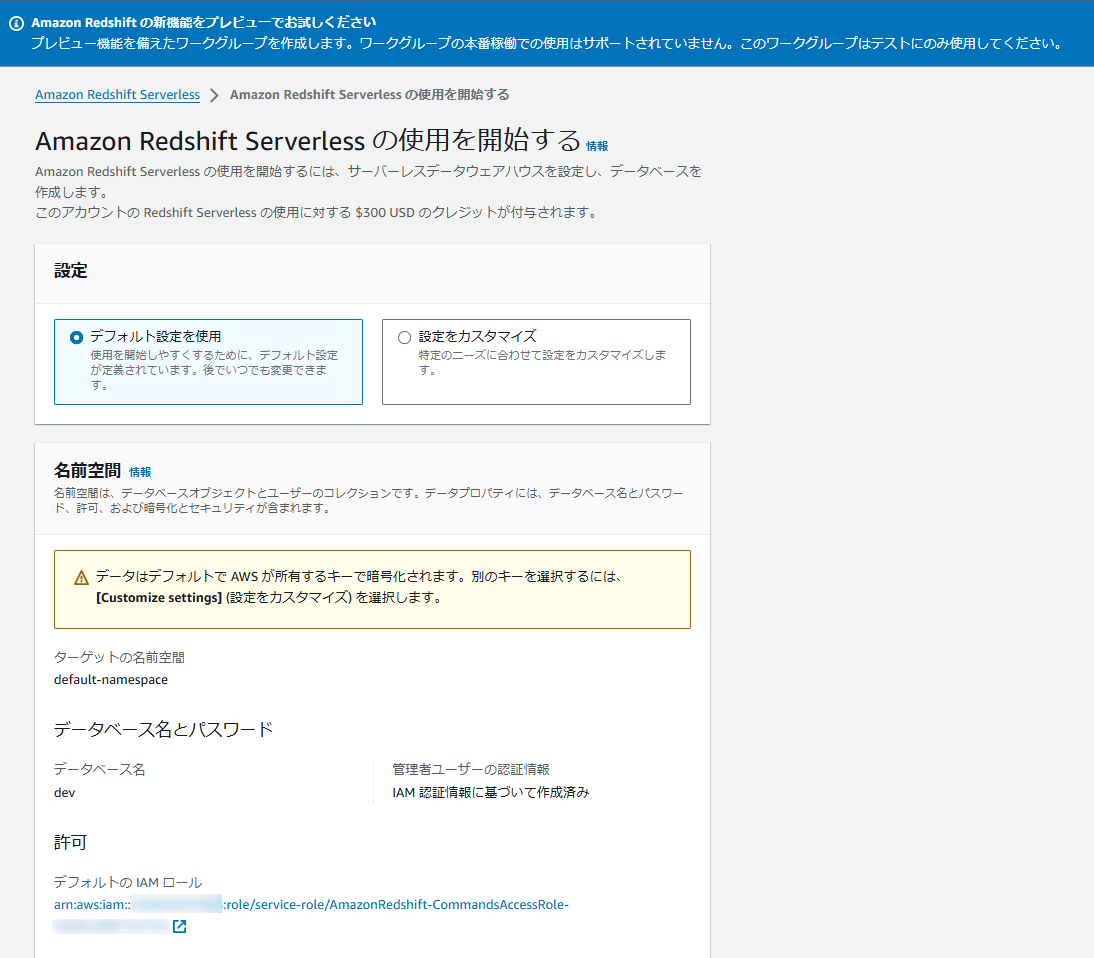
任意のワークグループ名を入力して、[Performance and cost controls]はデフォルトだと“128”が選ばれているので、今回は最低容量の“8”にします。
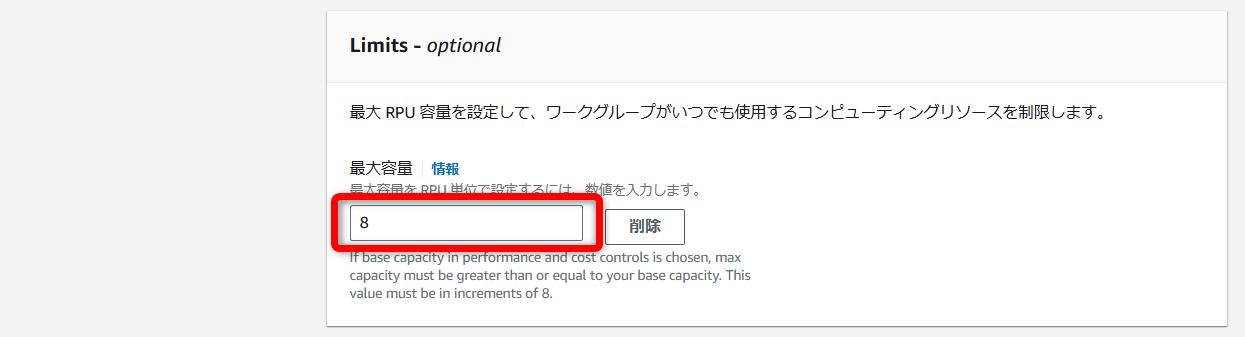
オプションで最大容量も設定できるので、必要に応じて設定します。
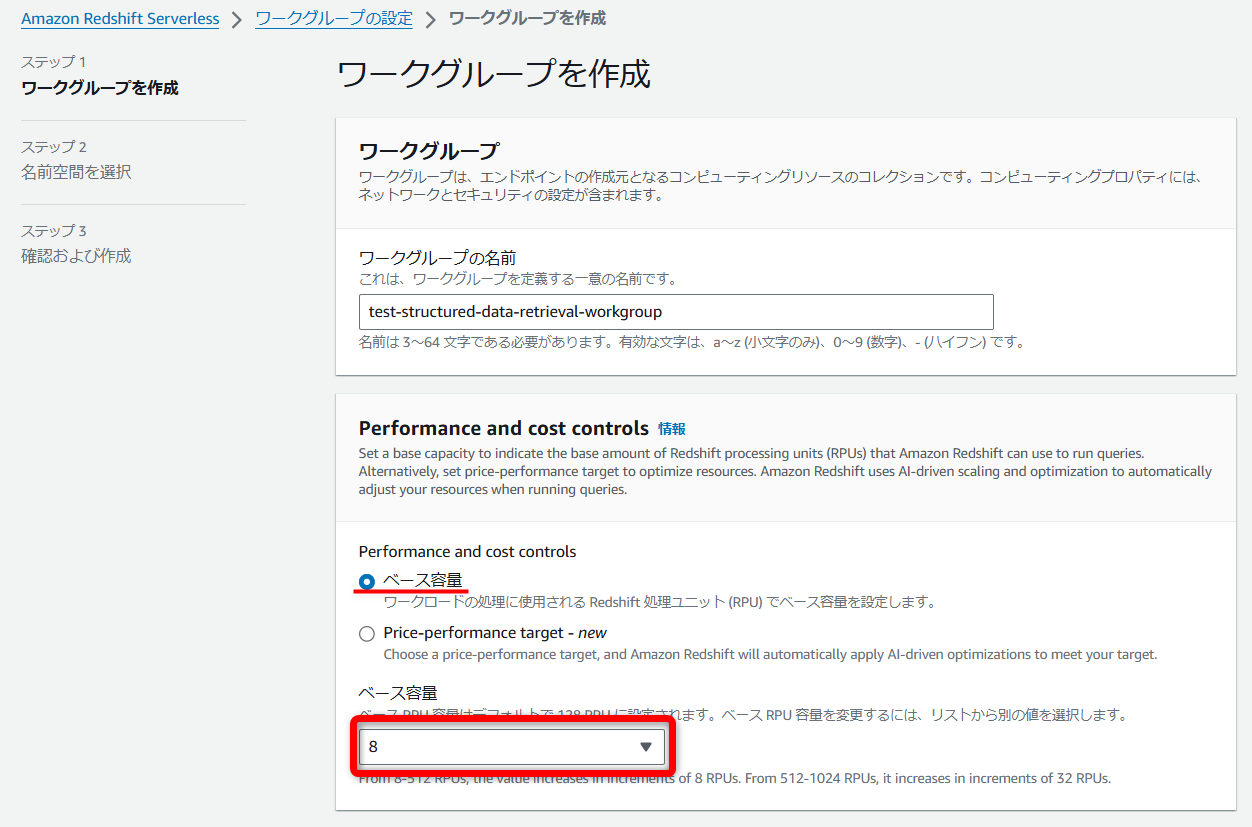
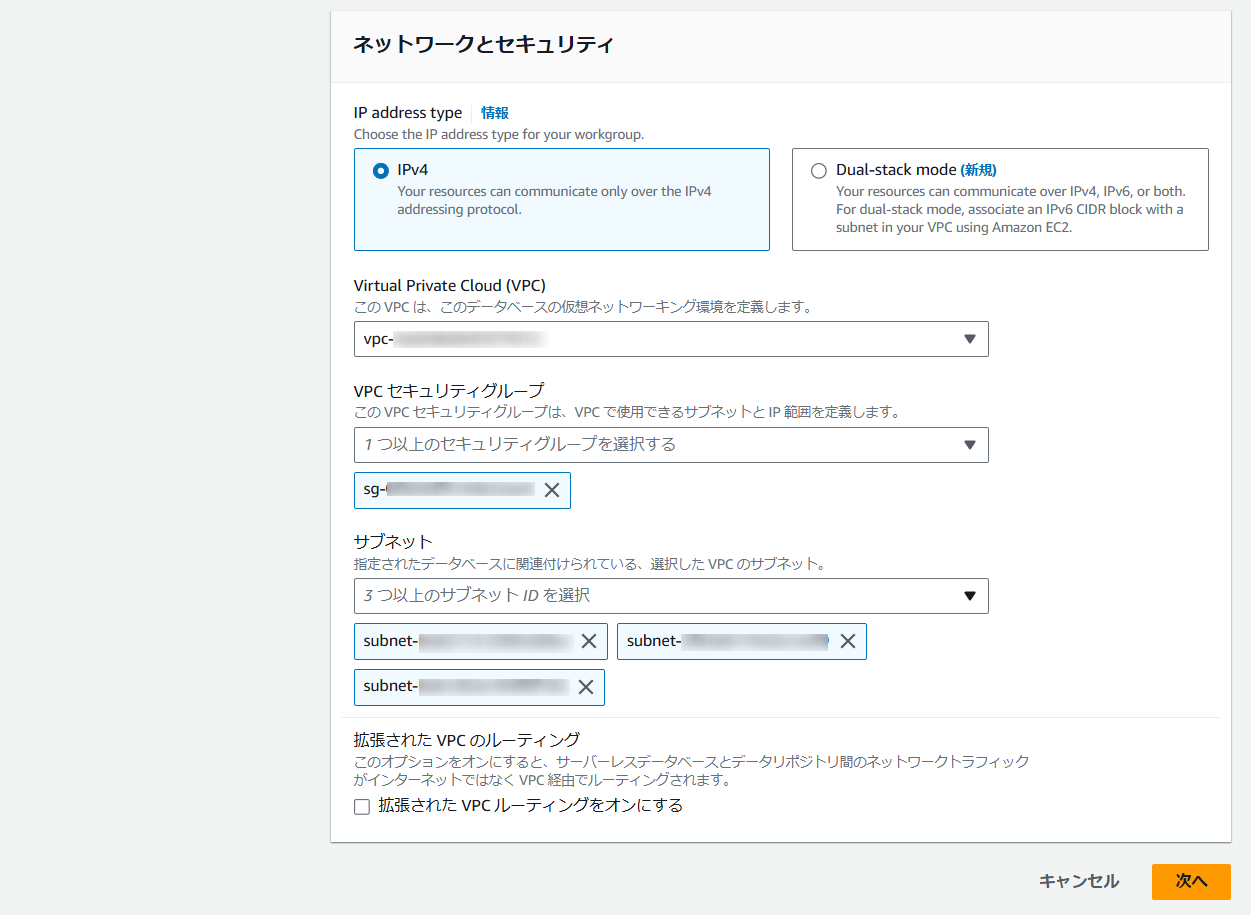
「Redshift」を設置する任意のVPCとセキュリティグループを選択します。
※最低3つ以上のサブネットに配置する必要があります。
その他の設定値は特に変更せずデフォルトのまま進めます。
[新しい名前空間を作成]を選択して任意の名前空間を入力します。
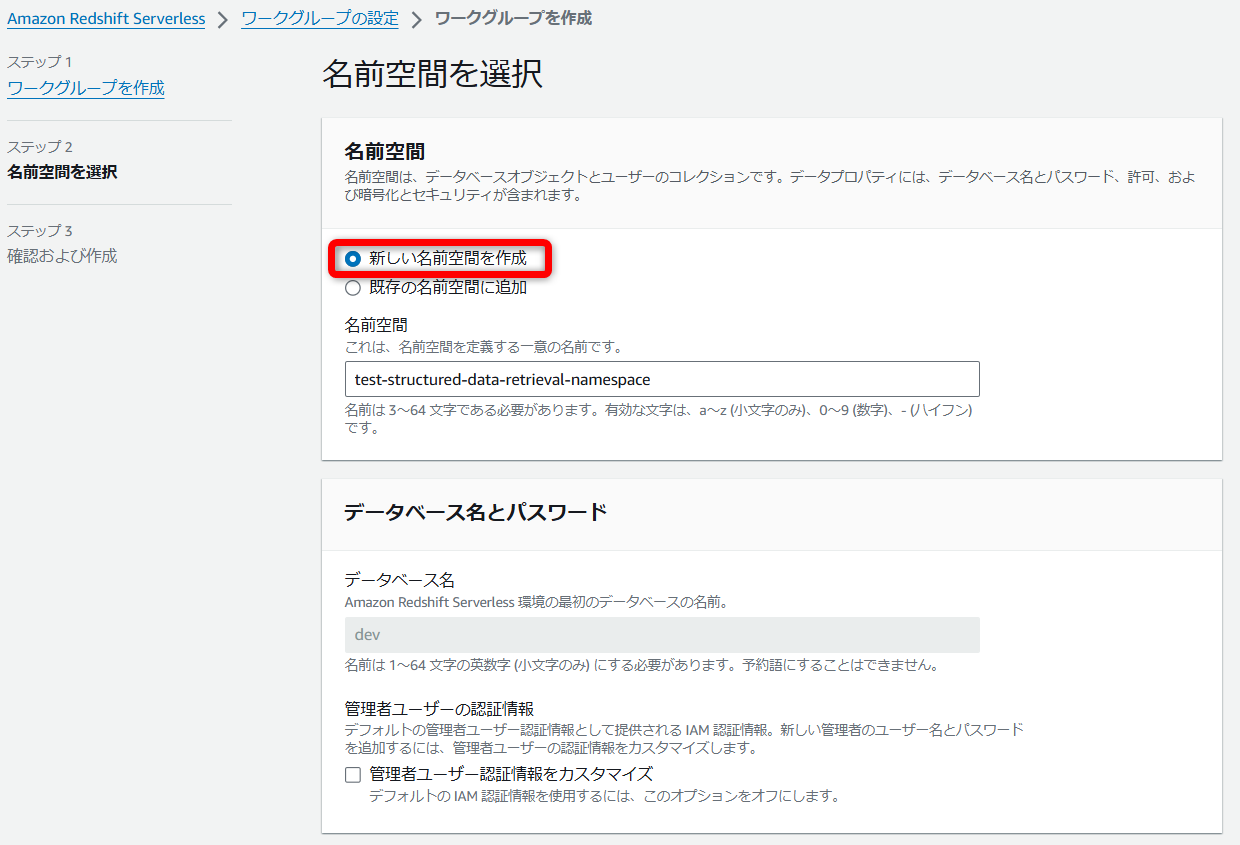
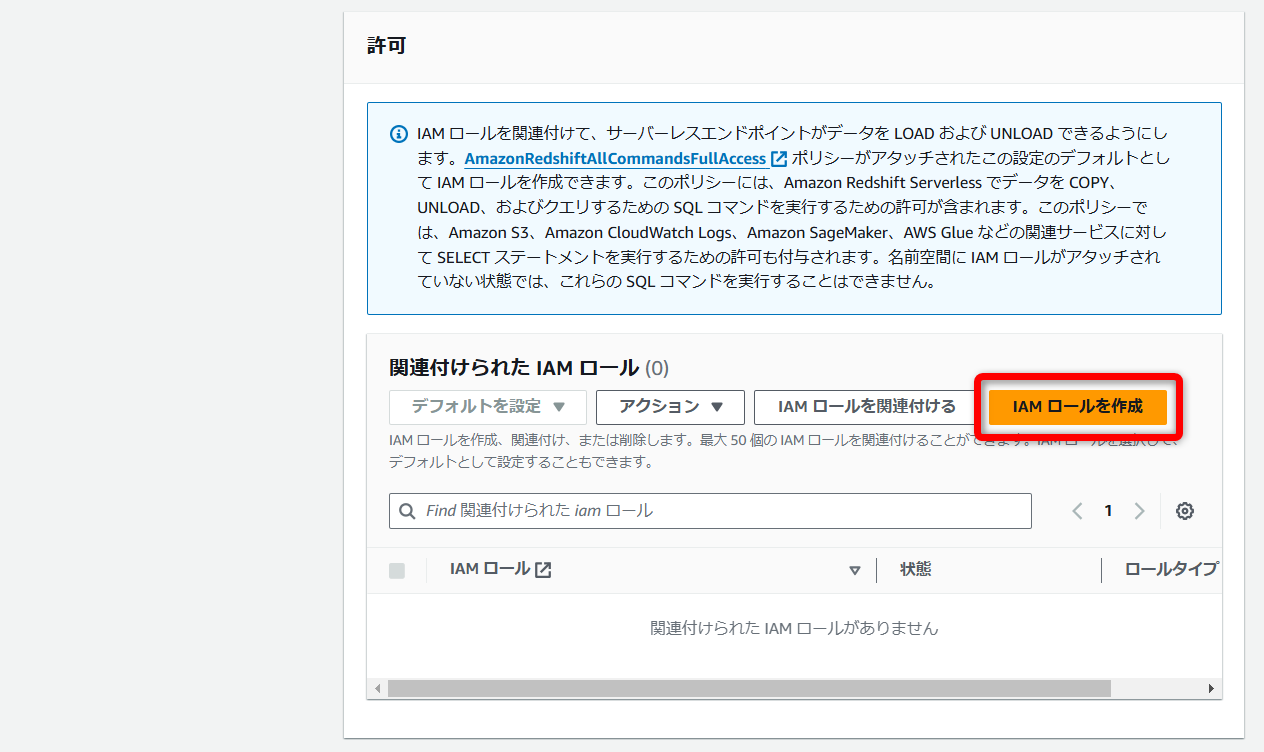
[IAM ロールを作成]から「Redshift」が使用する「IAMロール」を作成します。
(S3のRead関連のアクションが付与されたIAMポリシーが作成され、“AmazonRedshiftAllCommandsFullAccess”と一緒にアタッチされた状態になります。)
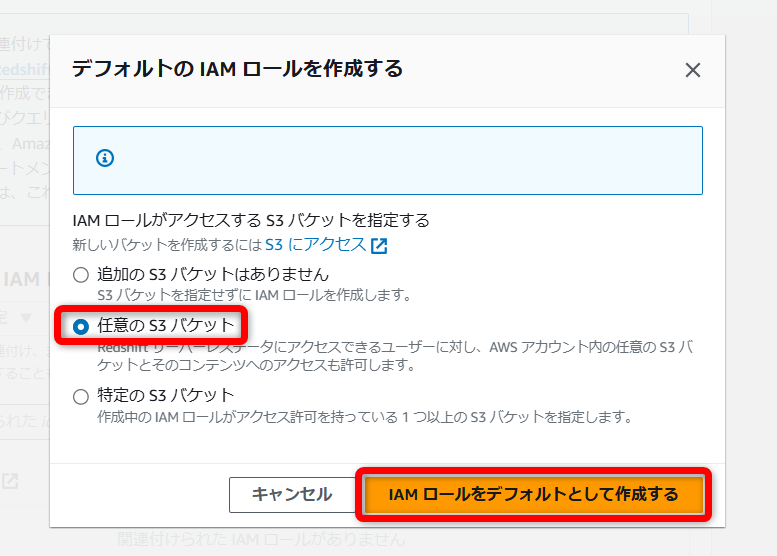
今回は検証のため[任意の S3 バケット]を選択していますが、[特定の S3 バケット]を選択することで、アクセスを許可するS3を限定できます。
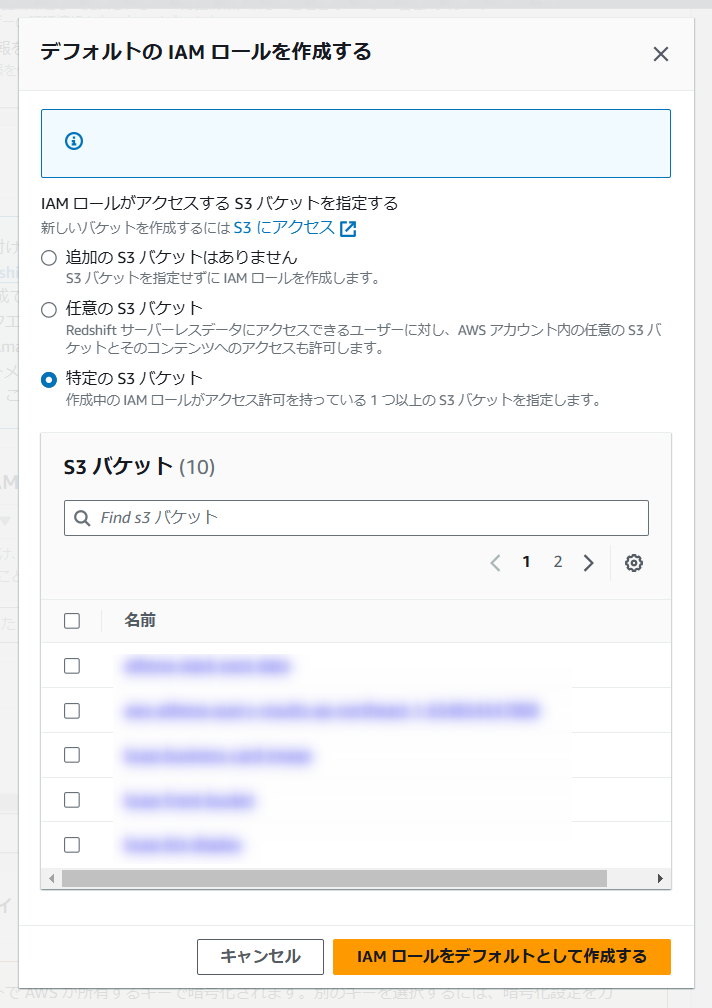
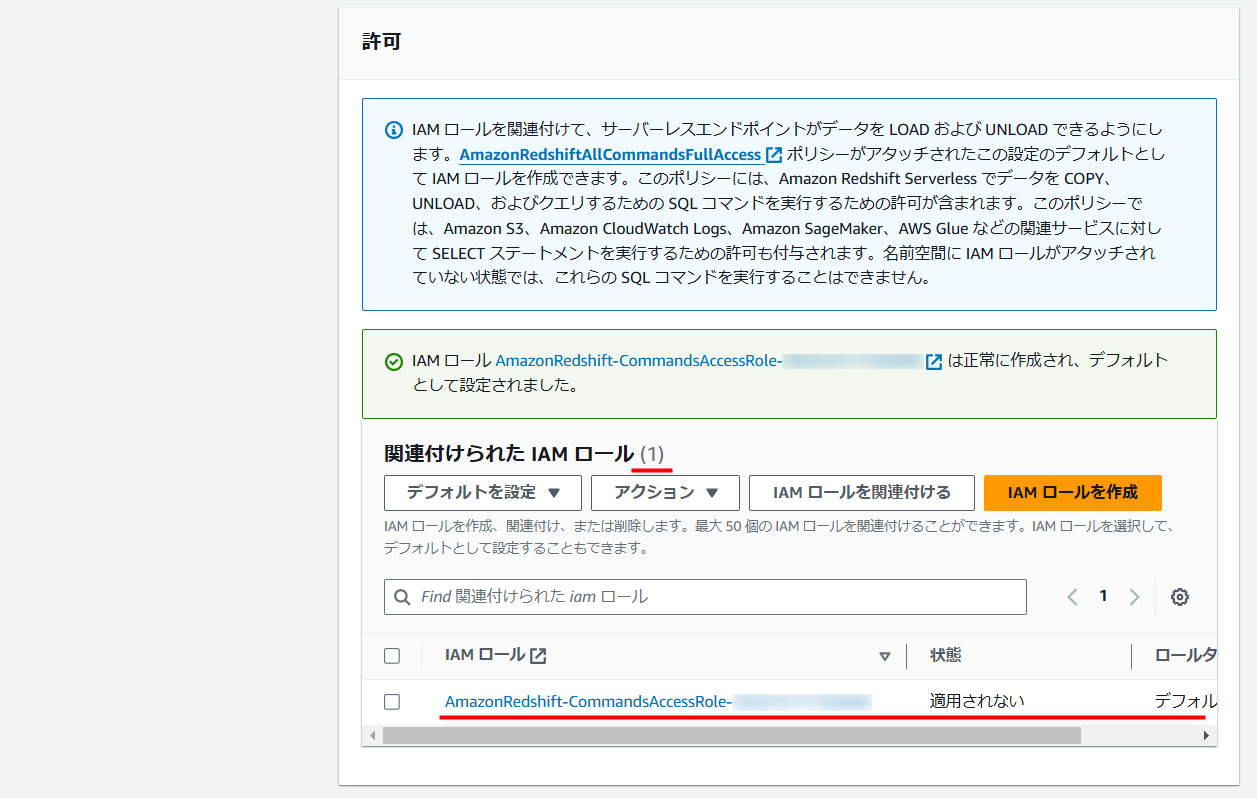
「KMS」を用いた暗号化のカスタマイズや、監査ログの設定などが行えますが、今回は特に設定せずデフォルトのまま進めます。
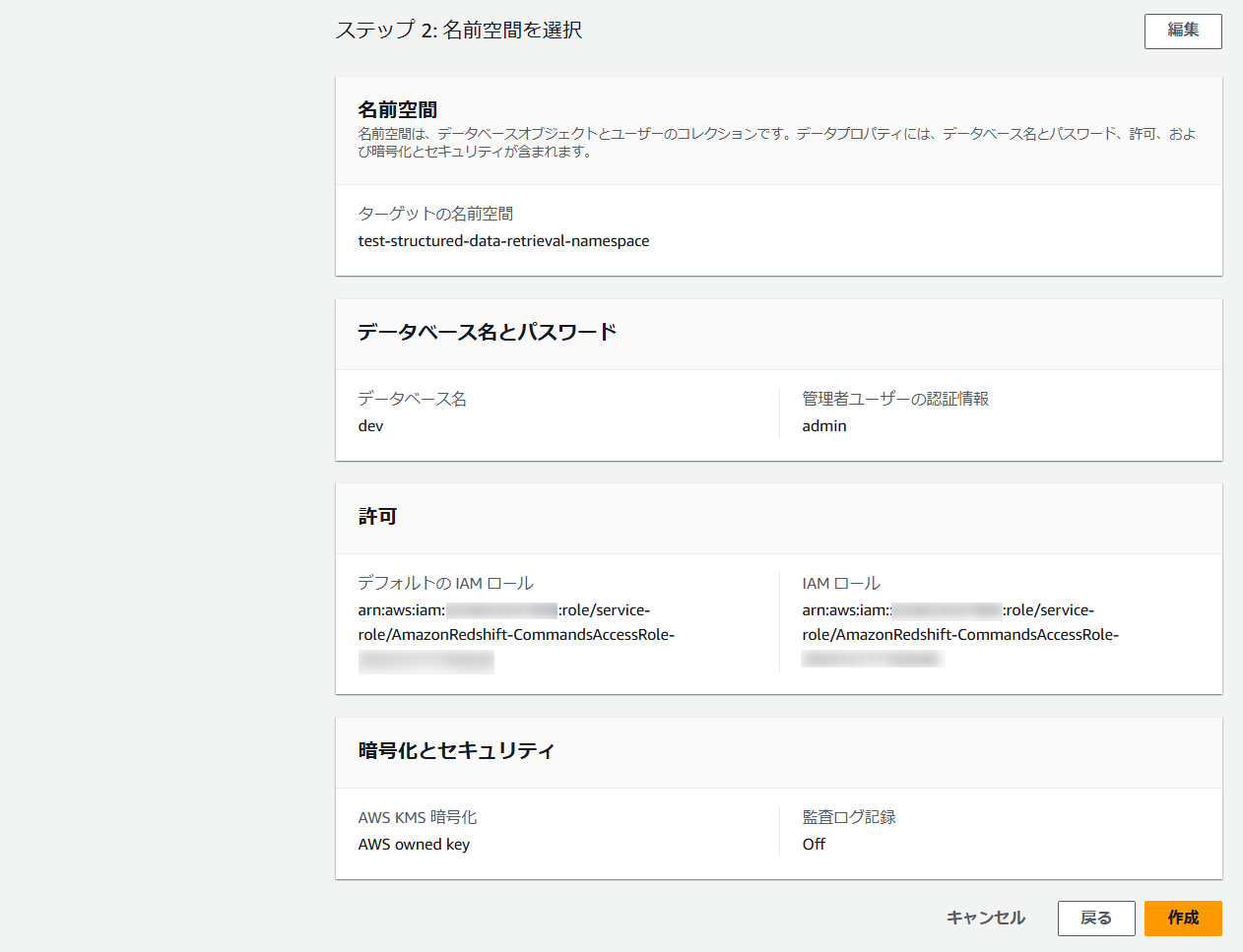
1~2分ほどで作成が完了します。
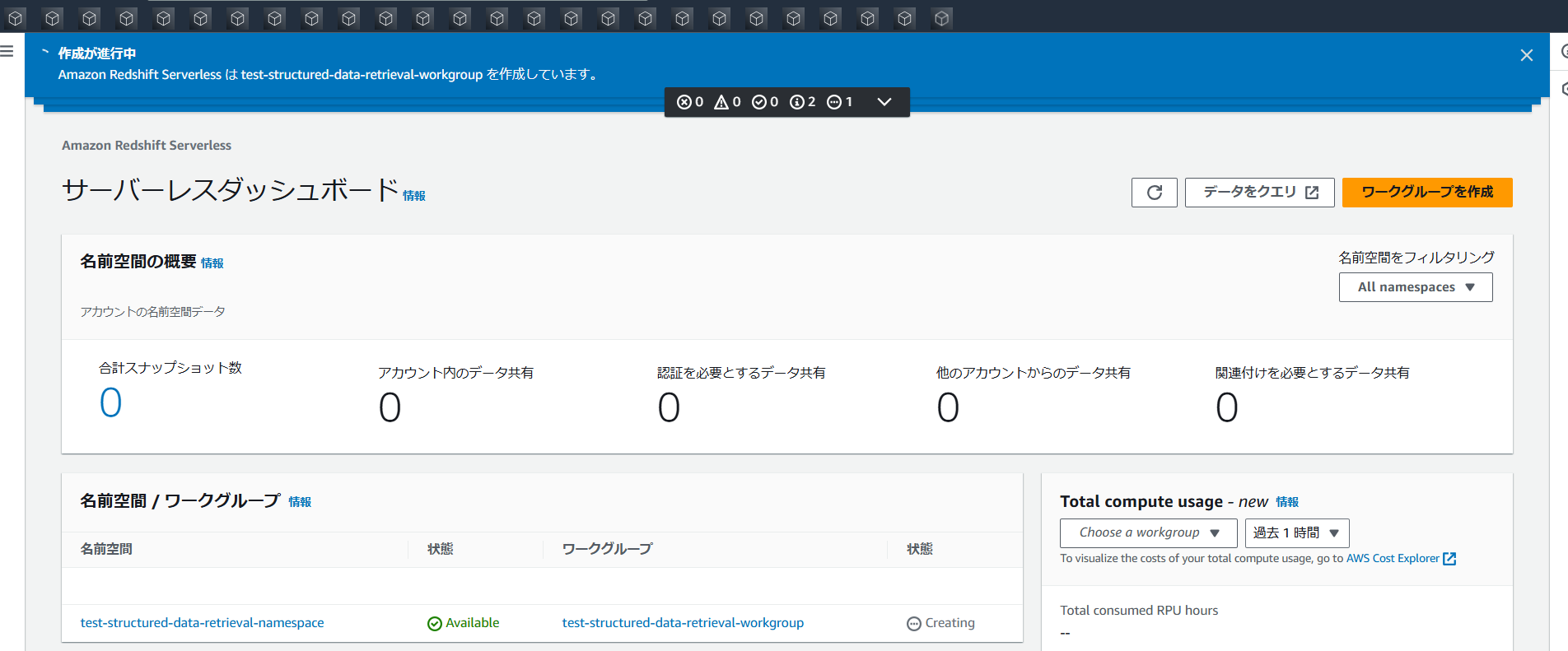
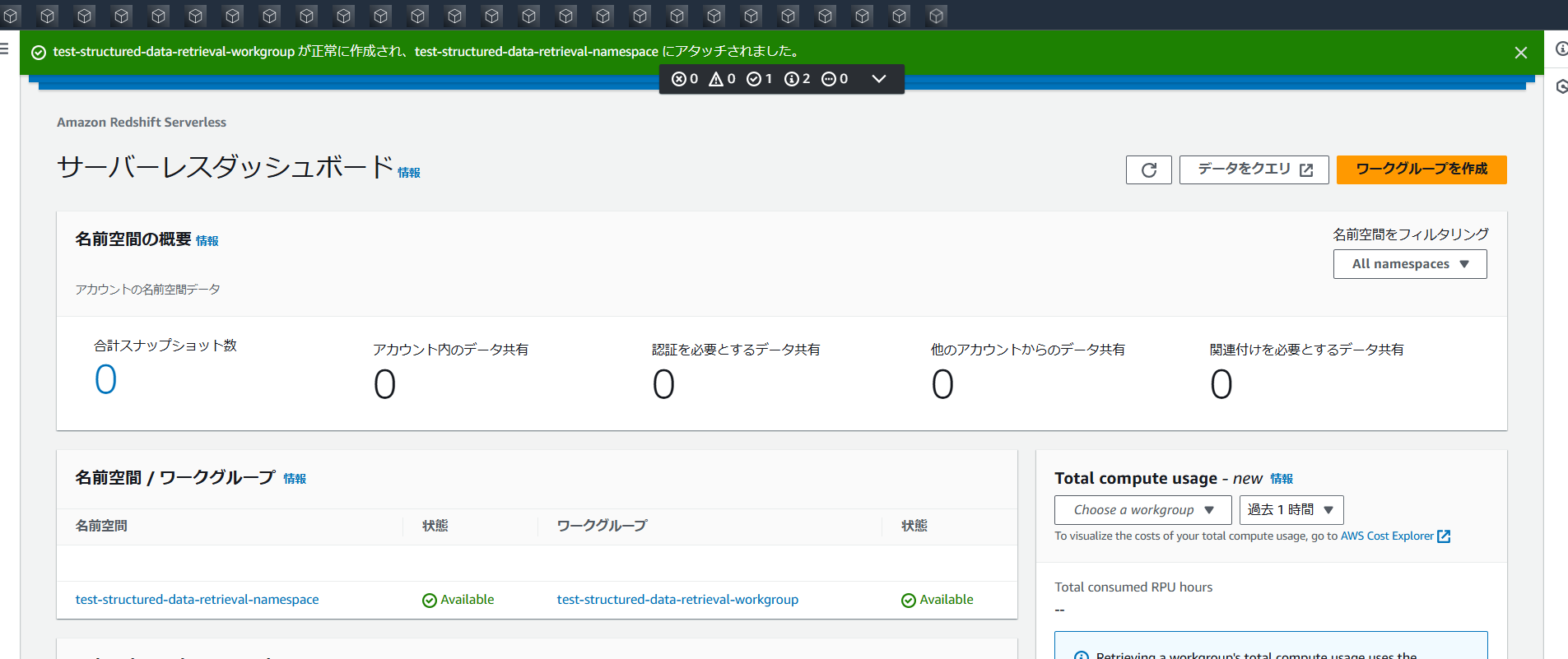
作成完了!!
[データをクエリ]から、クエリを実行するクエリエディター画面を起動します。
(なぜかショートカットのAWSアイコン画像が読み込まれていない謎には触れずにいきましょう………。😇)
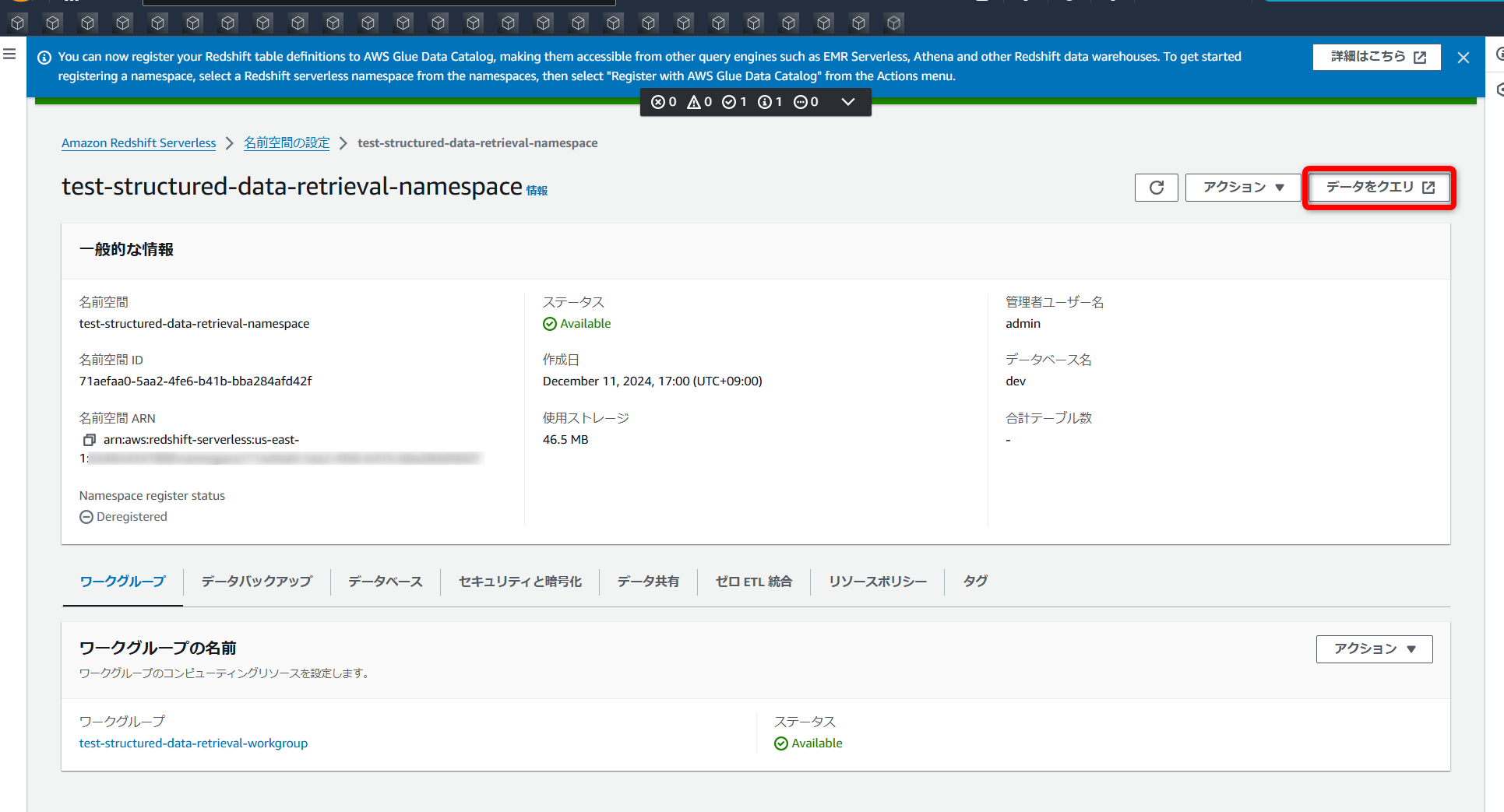
「Redshift Serverless」でテーブル作成~S3からデータのロード
データベース作成
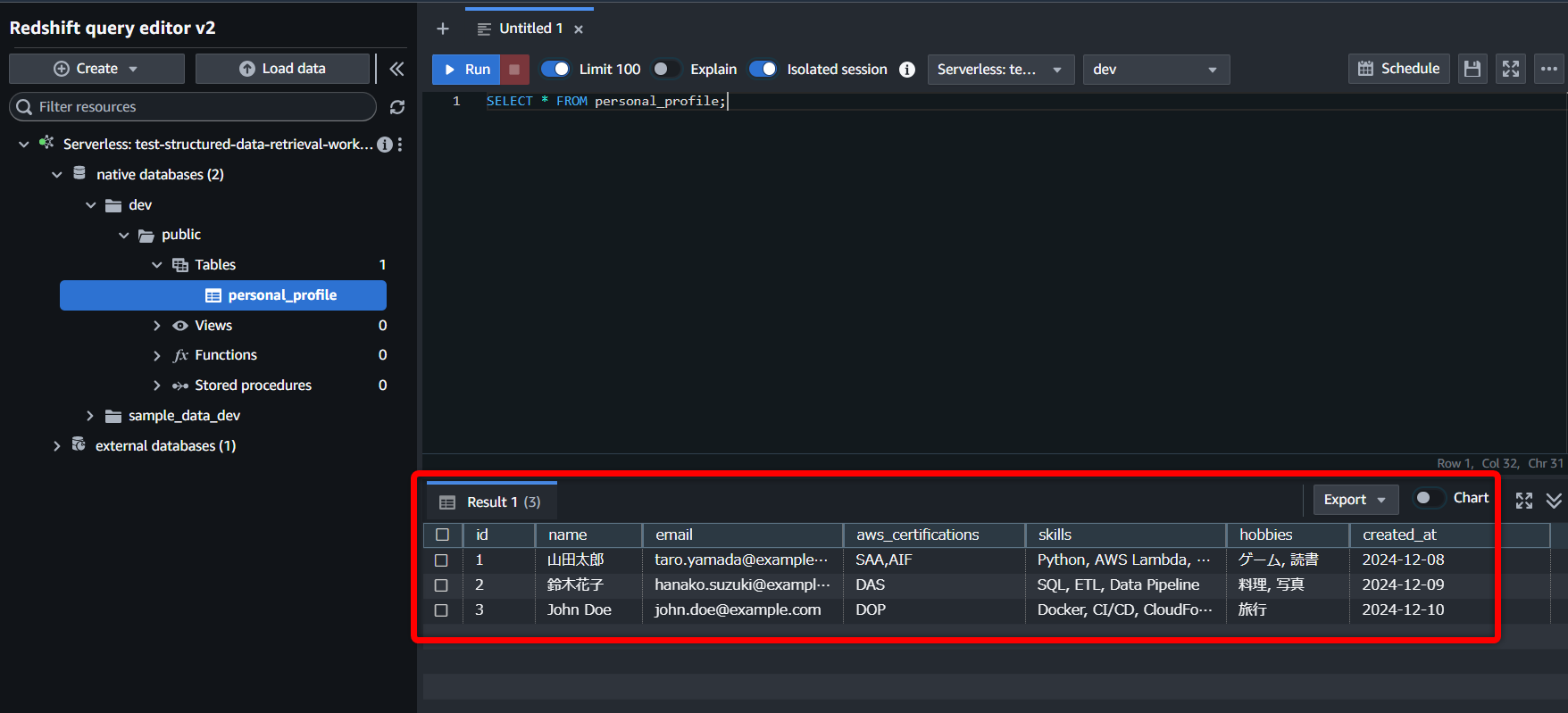
クエリエディターを開いたら、先程作成したワークグループを選択します。
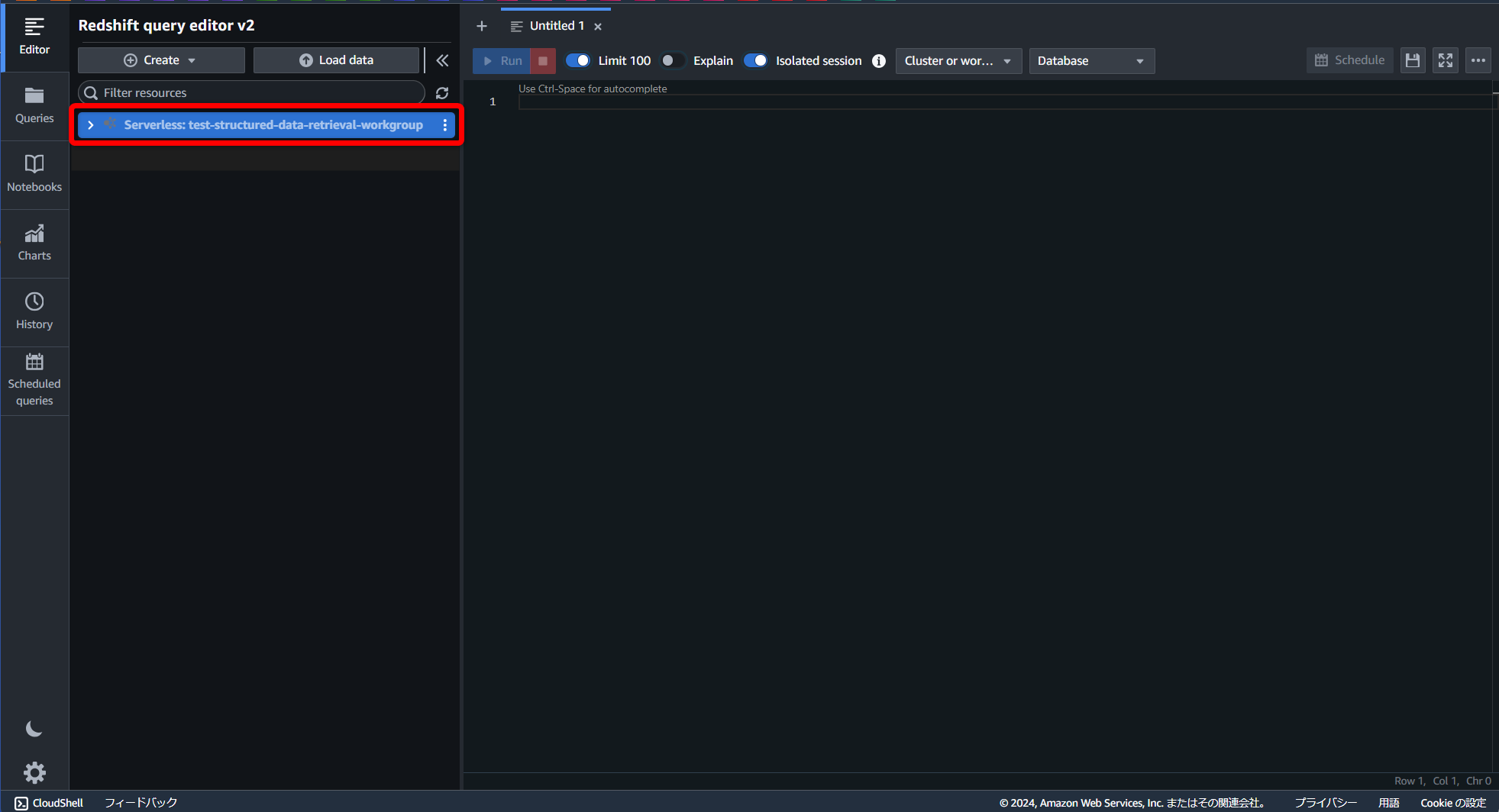
ワークグループに接続する際に使用する認証情報を聞かれますので、[Federated user]を選択して進めます。
(クエリエディターがパスワードを生成して一時的に認証を行う方式)
データベース名はデフォルト入力の“dev”のまま進めます。
“native databases”配下に、“dev”データベースが作成されました👏
テーブル作成
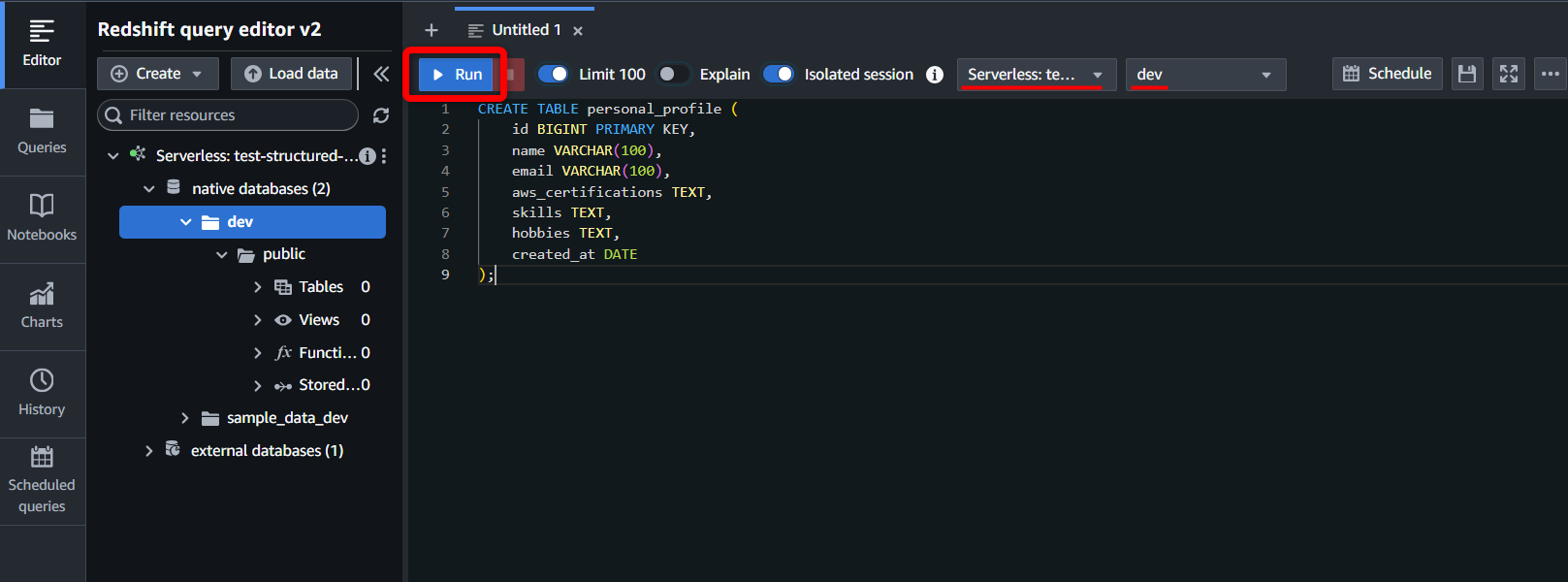
この後インポートするデータに合わせて、SQLでテーブルを作成します。
実行先のデータベースが正しいことを確認して、[Run]で実行します。
今回は“personal_profile”という名前のテーブルを以下のSQLで作成しました。
CREATE TABLE personal_profile (
id BIGINT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
aws_certifications TEXT,
skills TEXT,
hobbies TEXT,
created_at DATE
);
“public”配下の“Tables”を見ると、無事“personal_profile”テーブルが作成されています👏
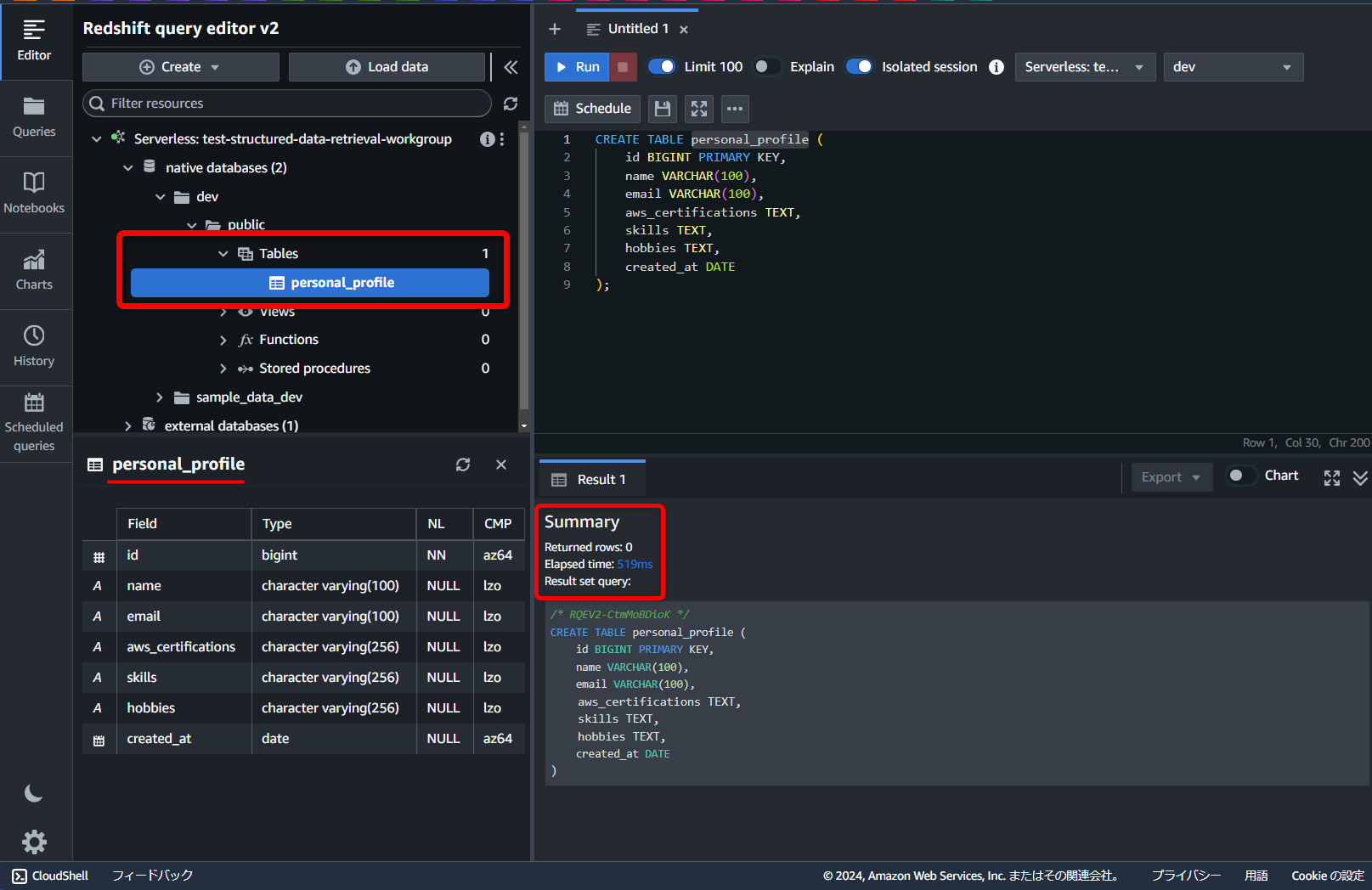
S3からデータのロード
以下のクエリで「S3」にあるデータからコピーしてきます。
COPY dev.public.personal_profile
FROM '{コピー対象オブジェクトが保存されている S3 URI}'
IAM_ROLE '{Redshiftに割り当てられた IAMロールarn}'
IGNOREHEADER 1
REGION 'us-east-1'
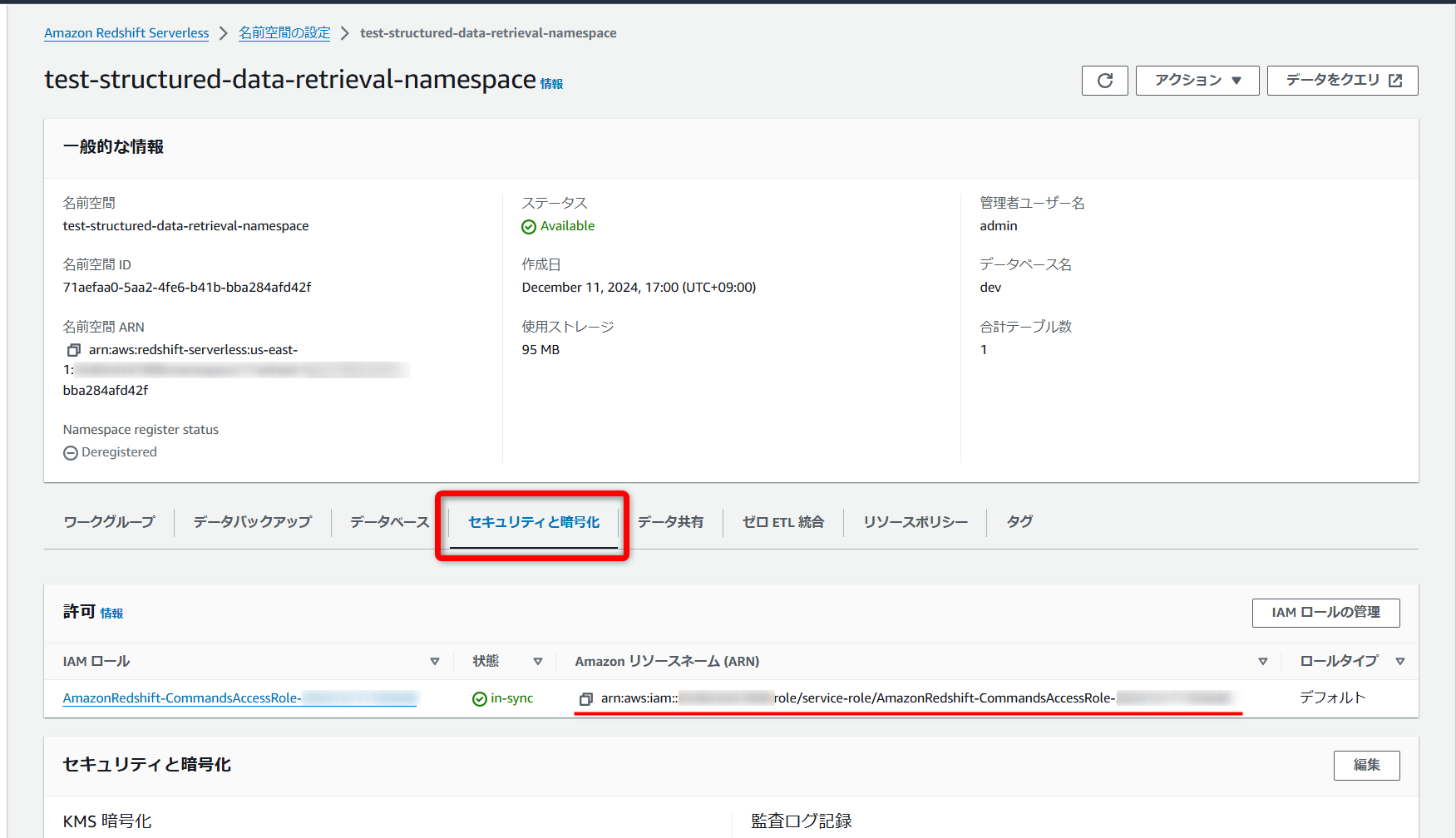
FORMAT AS CSV; →「Redshift」に関連づけたIAMロールのarnは名前空間の詳細ページにある[セキュリティと暗号化]タブから確認できます。
無事データがコピーされました!👏
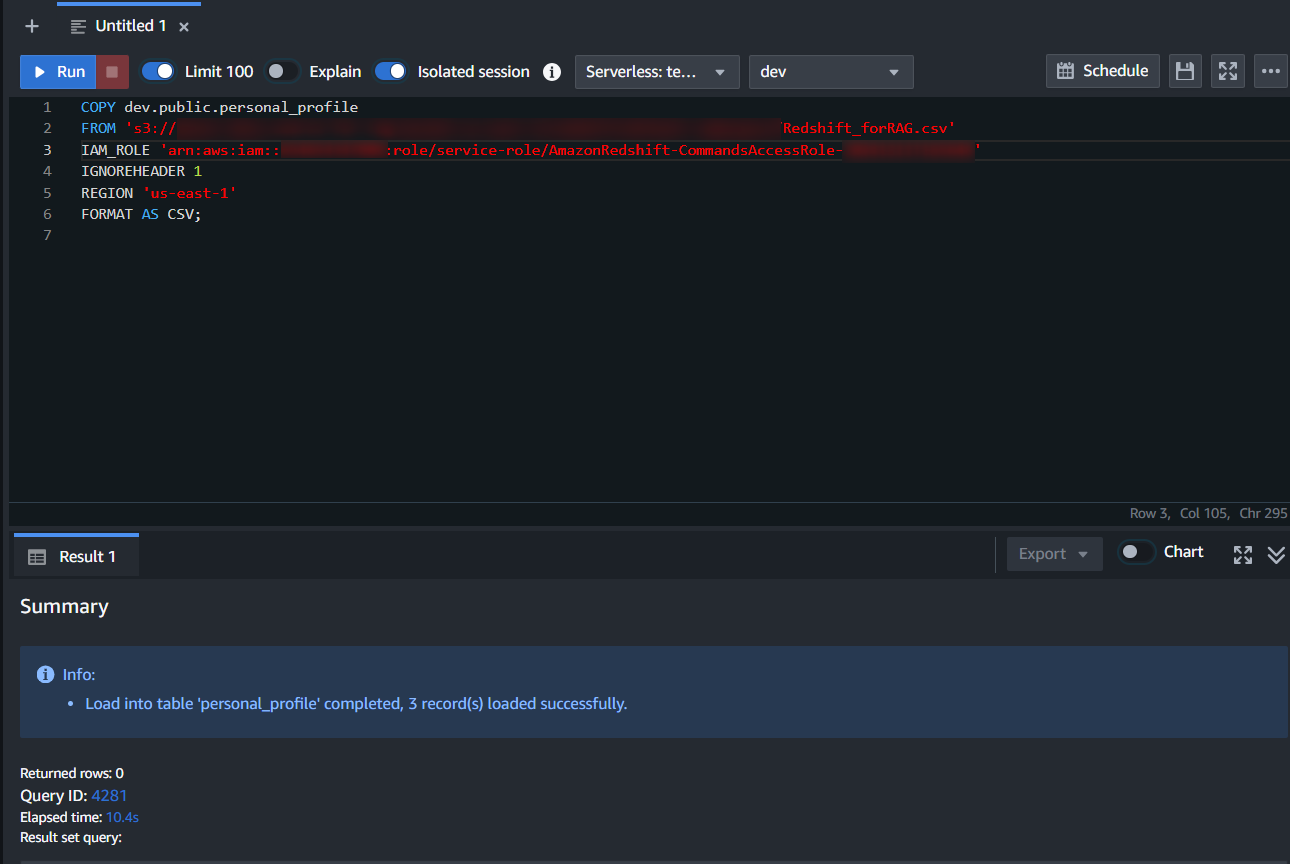
若干躓いたんですが、“IGNOREHEADER 1”という構文を使用しないとエラーで弾かれますのでご注意を。🥺
(CSVのheader行となる1行目を無視する必要があるため)
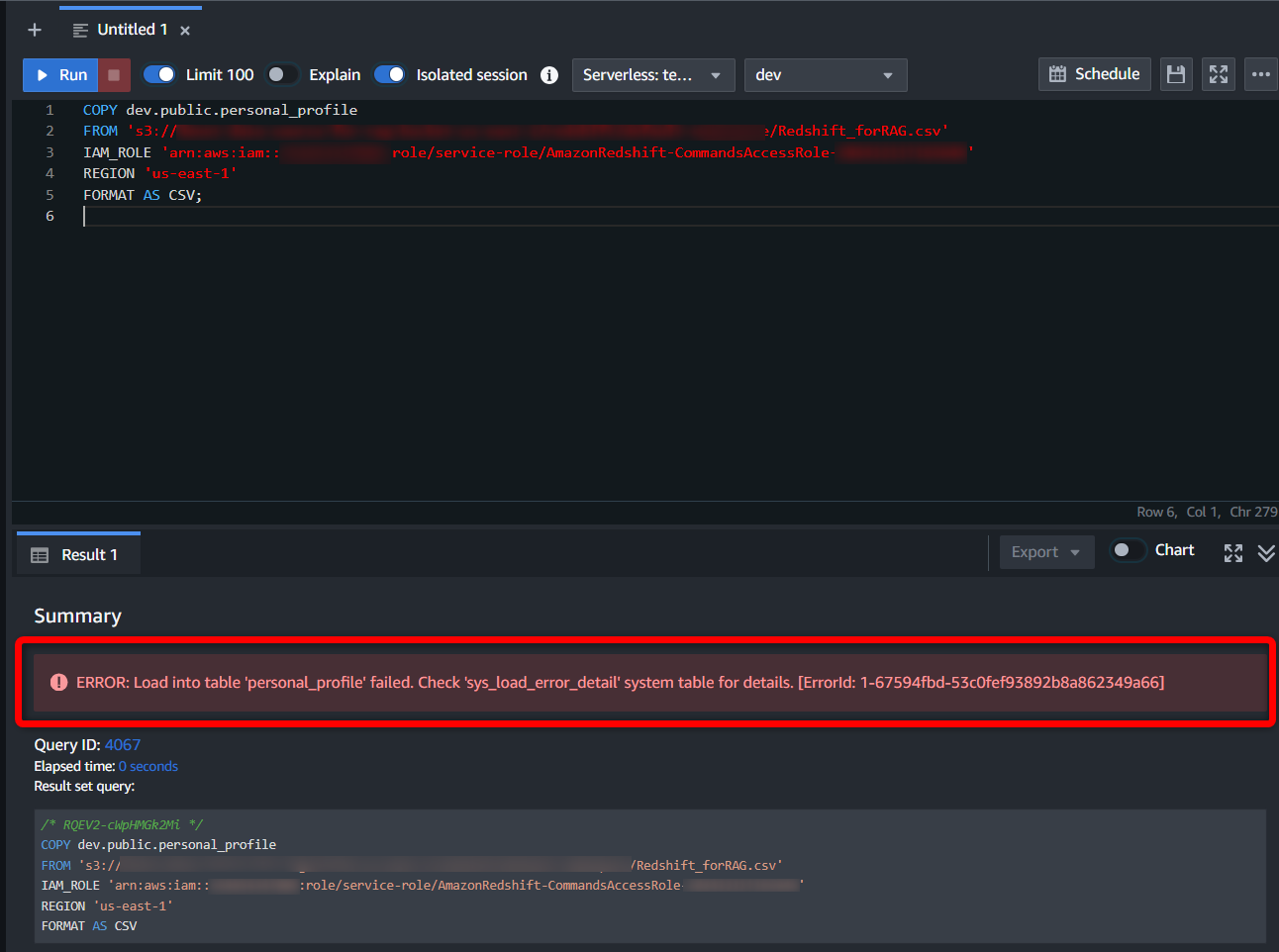
これにてソースとなる「Redshift」の準備が完了したので、お待ちかねの「Bedrock」作業を進めていきます。
「Bedrock Knowledge Base with structured data store」の作成
Amazon Bedrock > ナレッジベース > [ナレッジベースを作成]から[Knowledge Base with structured data store]へ進みます。
([Knowledge Base with vector store]が従来のベクトルデータベースを使用したもの)
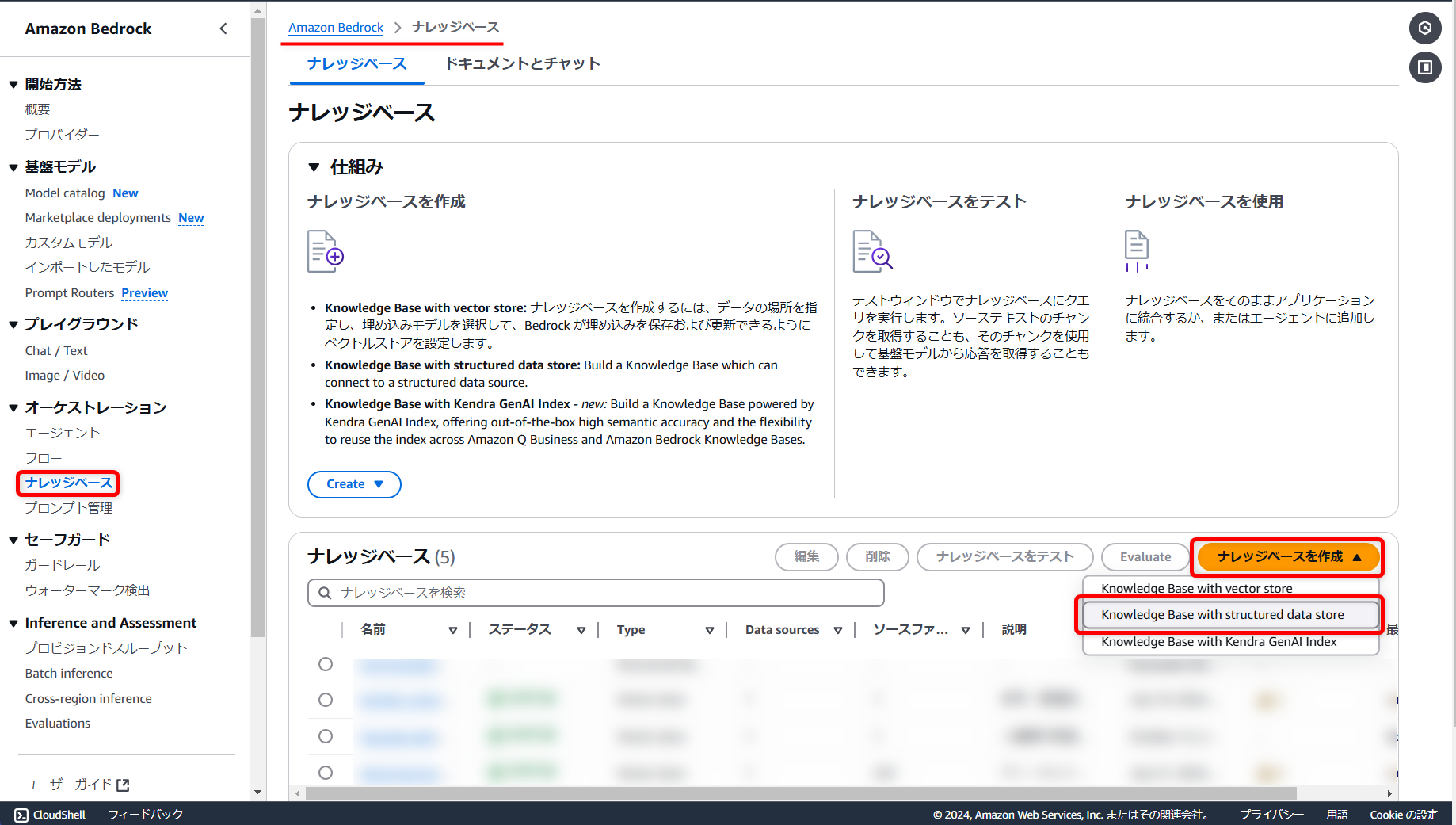
任意のナレッジベース名を入力し、既に「Redshift」が選択されているため、そのまま進めます。
その他IAM許可設定等はデフォルトのまま進めていきます。
ここに「Amazon SageMaker Lakehouse」とかも生えてくるんでしょうか?🤔
(スペース的にもう1個増えそう…??)
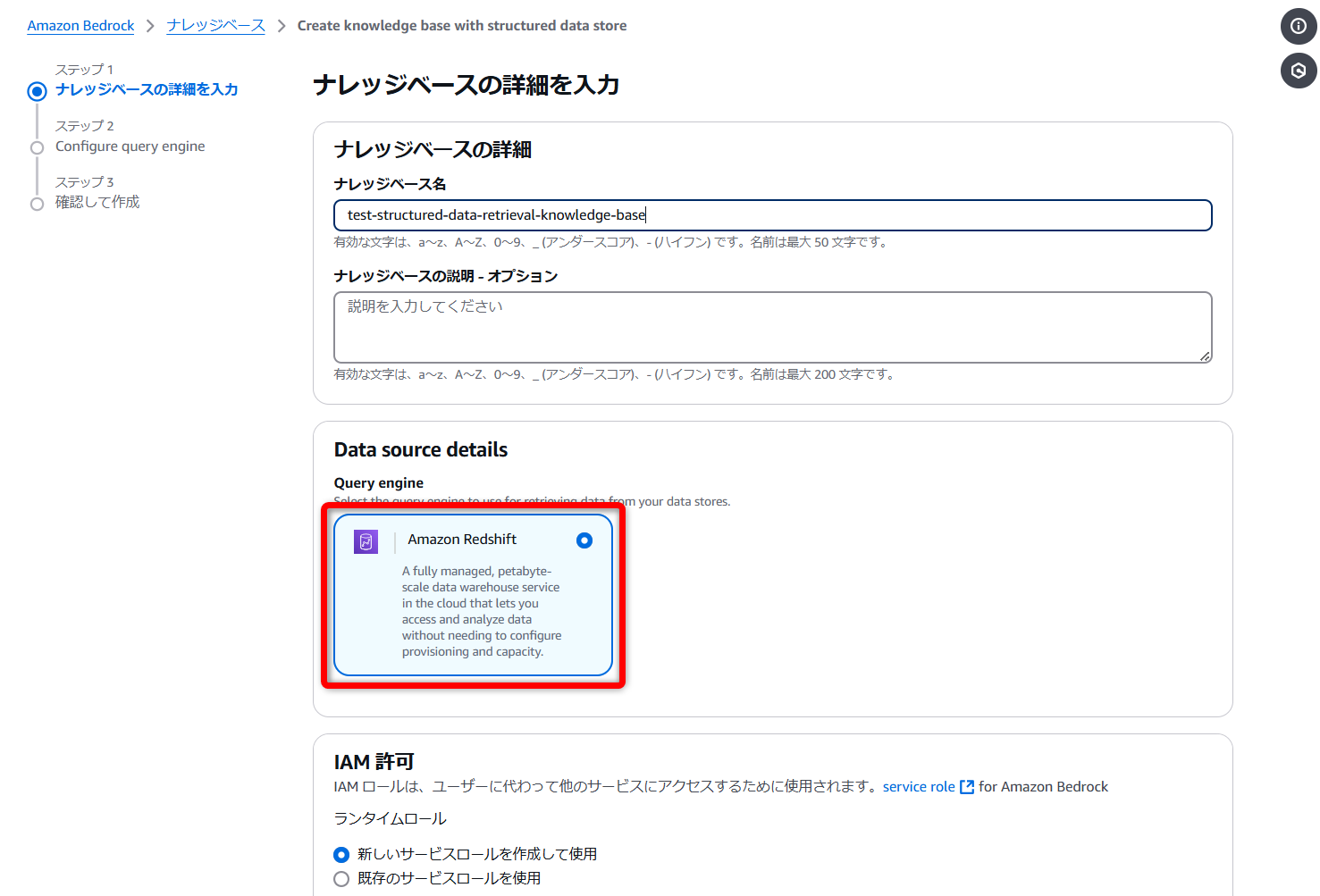
Redshiftのタイプは[Redshift serverless]を選択して、先ほど作成したワークグループを選択し、認証は[IAM Role]のまま進めます。
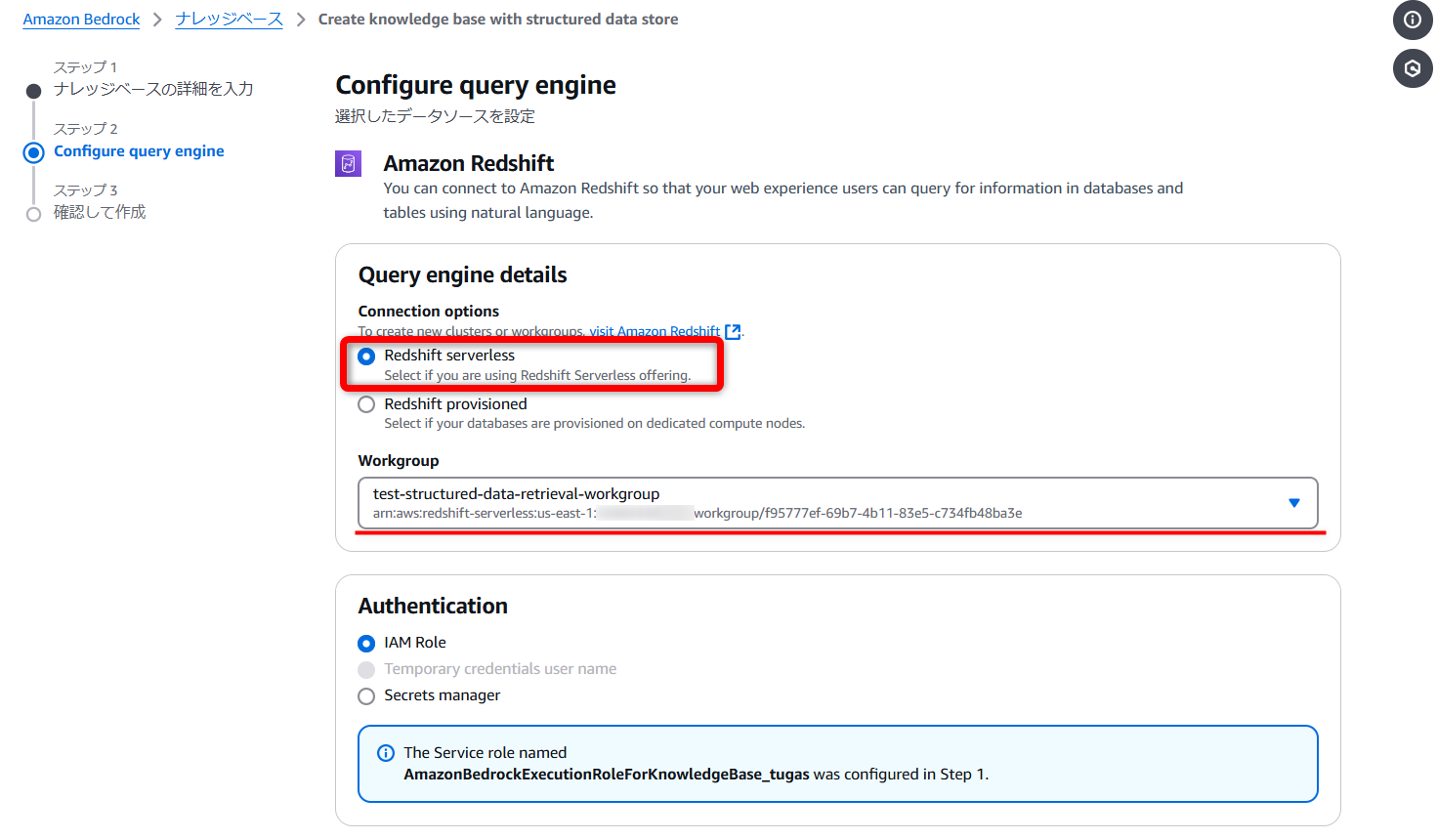
使用するデータベースを[Redshift database list]から選択します。(今回は先ほど作成した“dev”データベース)
その他オプションはデフォルトのままで進めます。
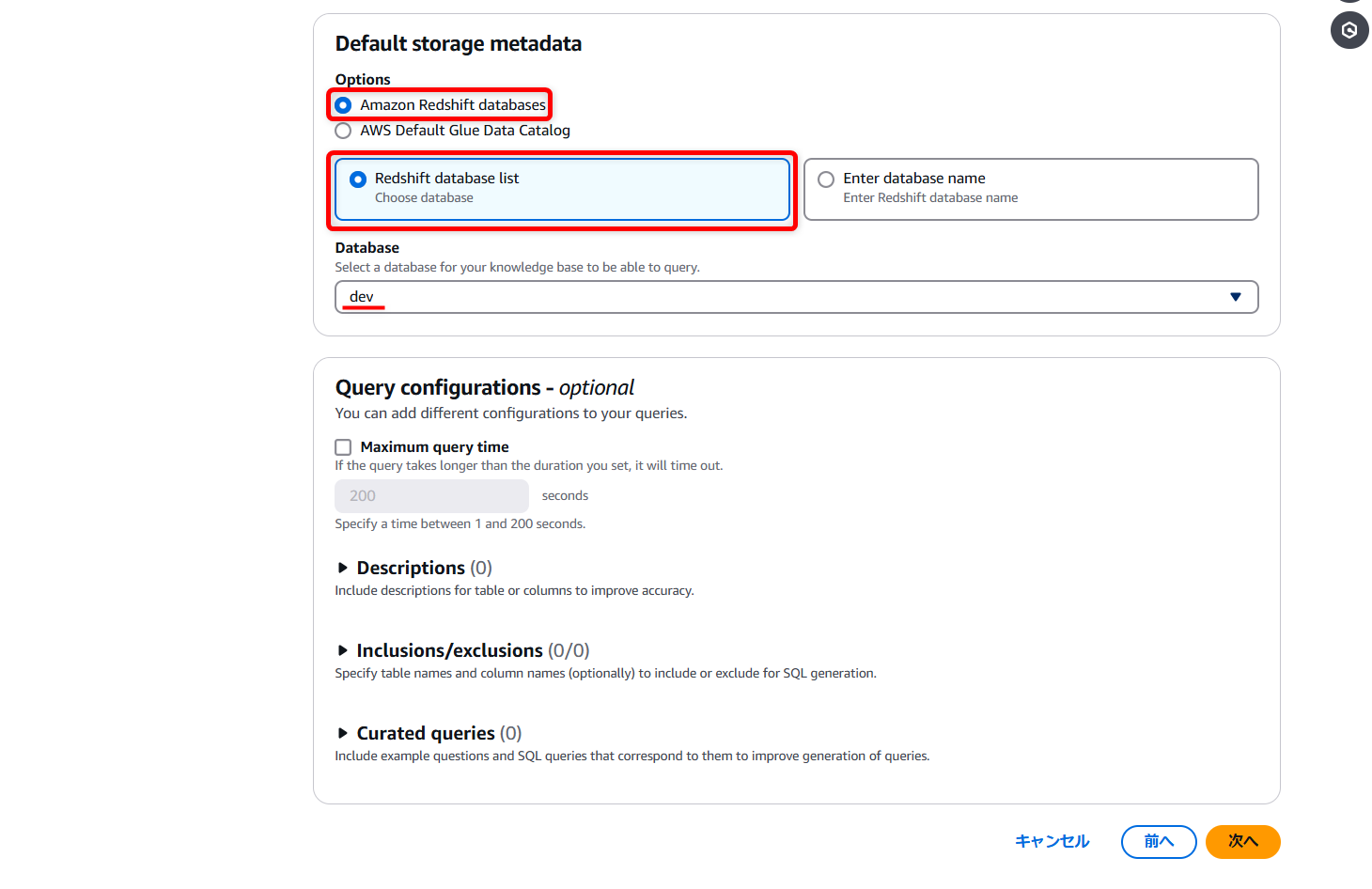
確認画面から、問題なければ作成!
作成完了後、画面上部に緑色の案内が出ますが、これが中々重要で
『同期する前に、テーブルに対する“SELECT”権限を付与せなあかんよ~』
て言うてます。
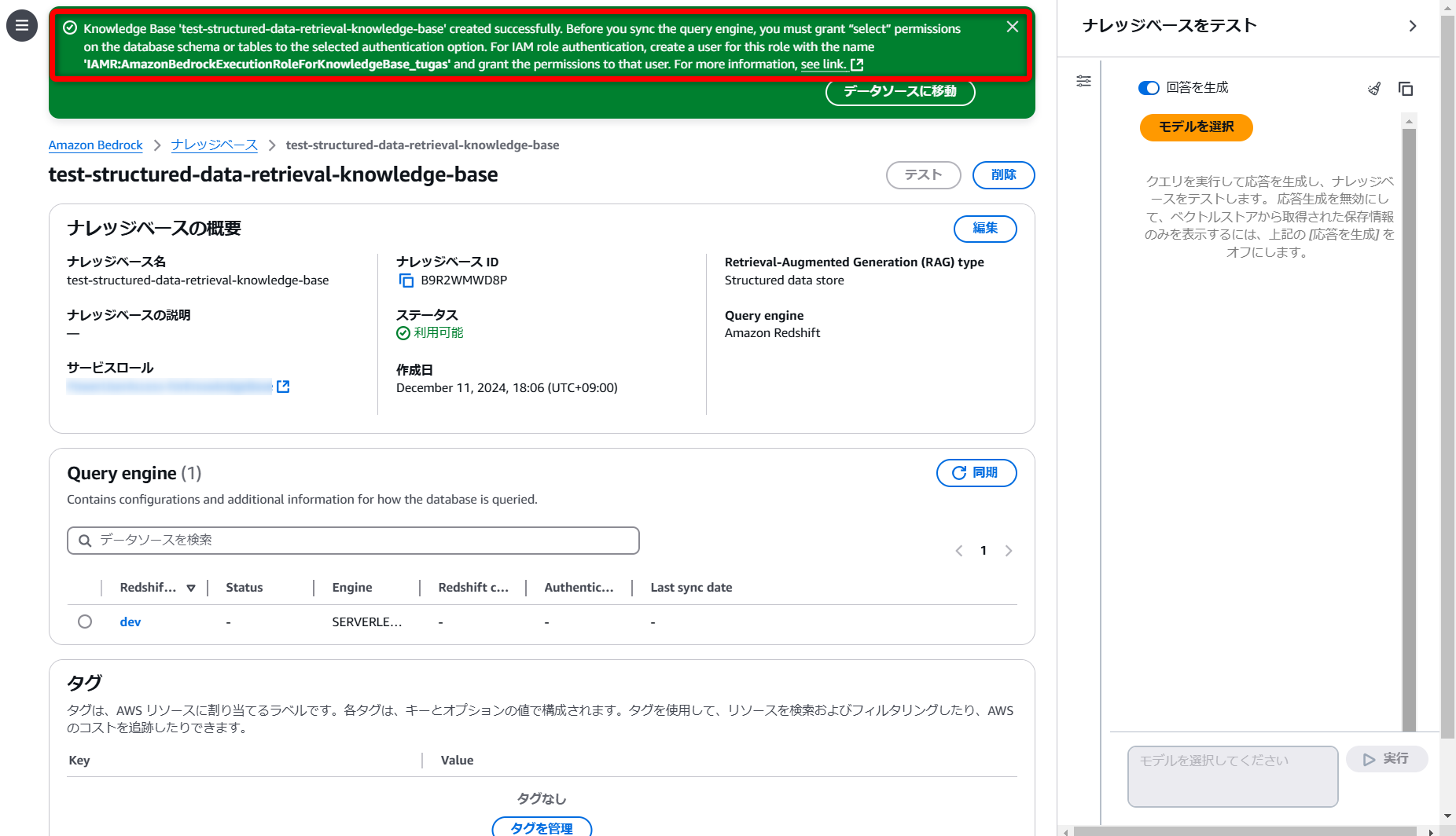
「Redshift」のクエリエディターにて、以下のクエリを実行する必要があります。
(「Bedrock Knowledge Bases」が使用するIAMロールに、「Redshift」の読み取り権限を付与します。)
CREATE USER "IAMR:{Bedrock Knowledge BasesのIAMロール名}" WITH PASSWORD DISABLE;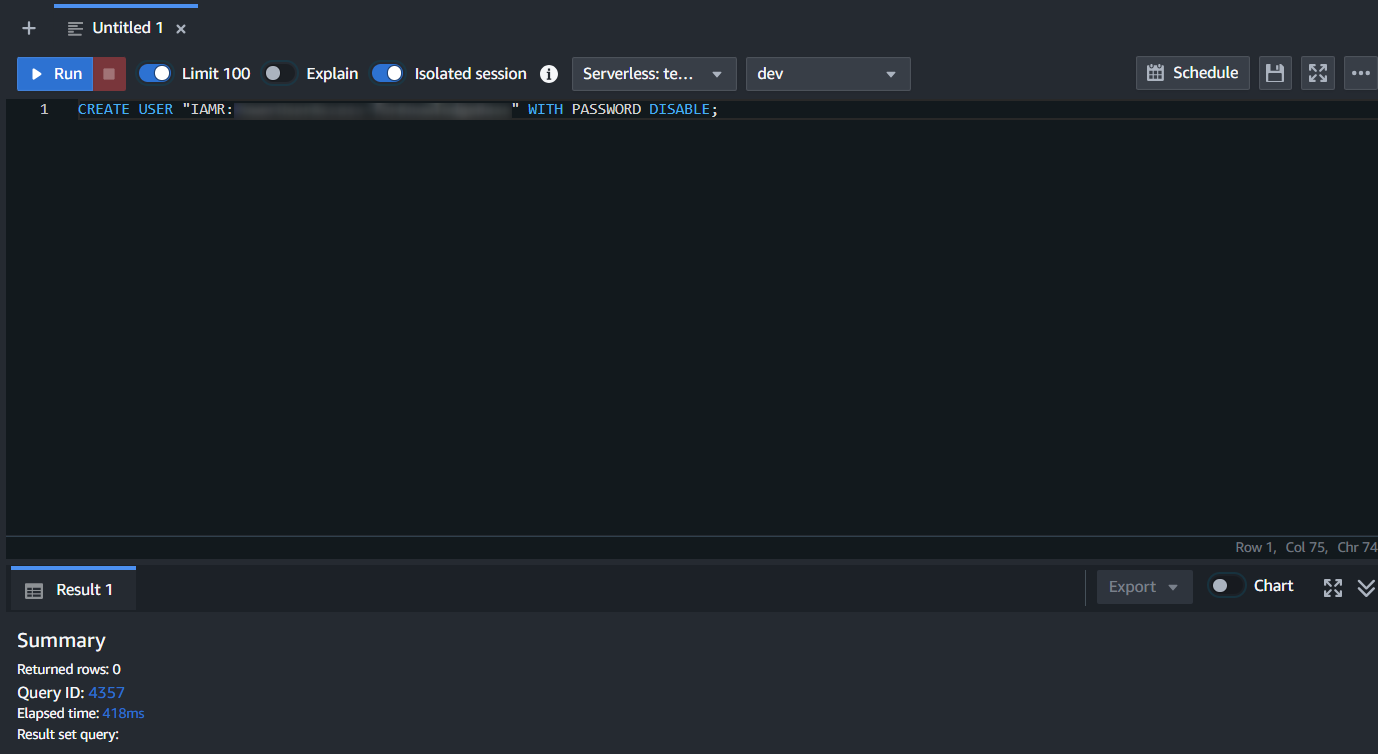
GRANT SELECT ON {テーブル名} TO "IAMR:{Bedrock Knowledge BasesのIAMロール名}";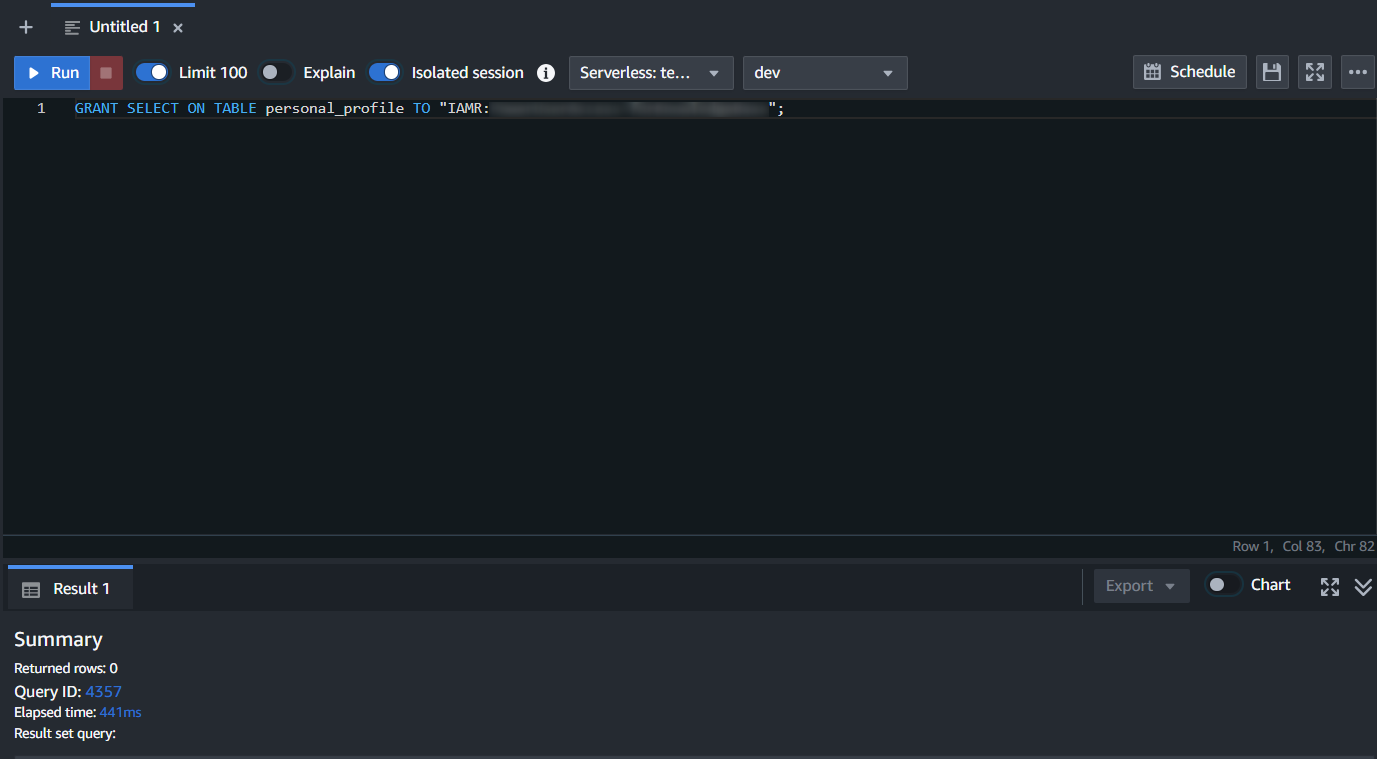
詳細は以下公式ドキュメントにて
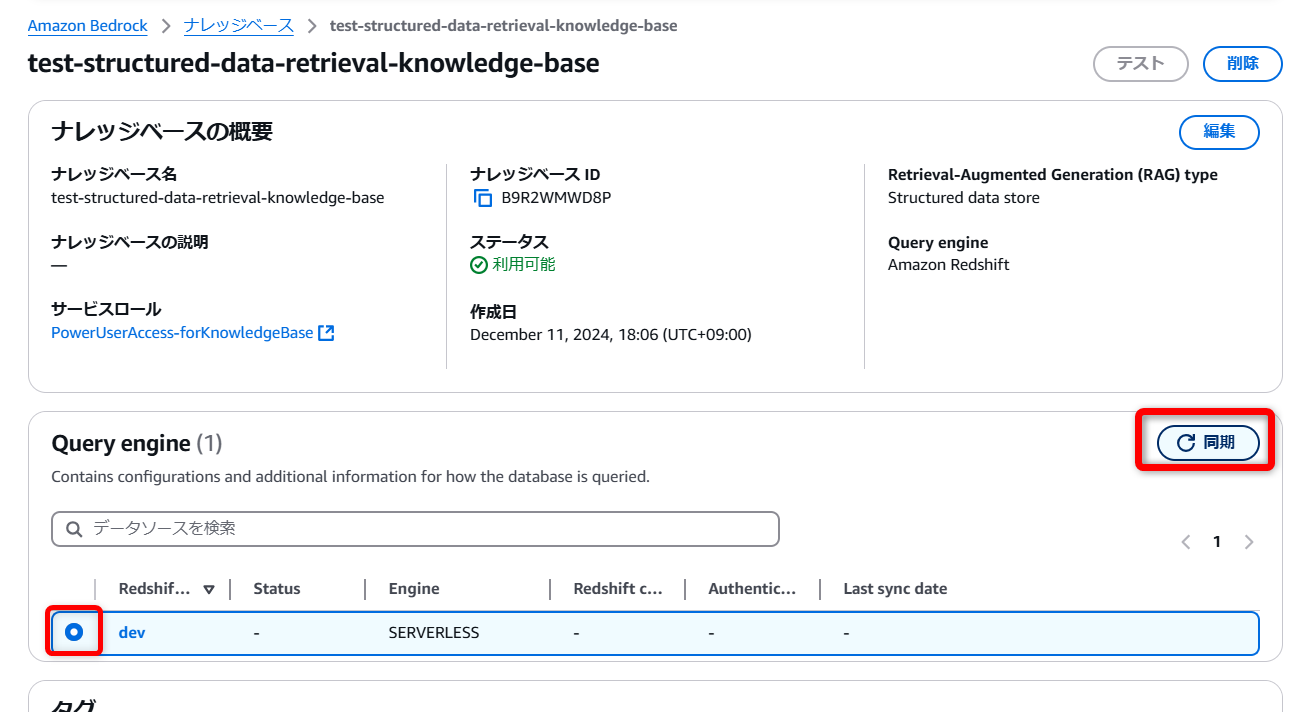
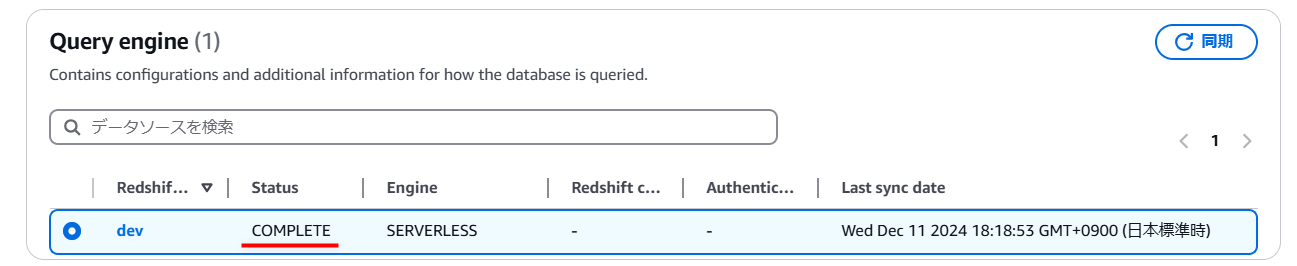
権限付与ができれば、ソースとなるデータベース(今回は“dev”)を選択して[同期]を実行します。
データも少ないので、数分で完了しました。
使ってみる
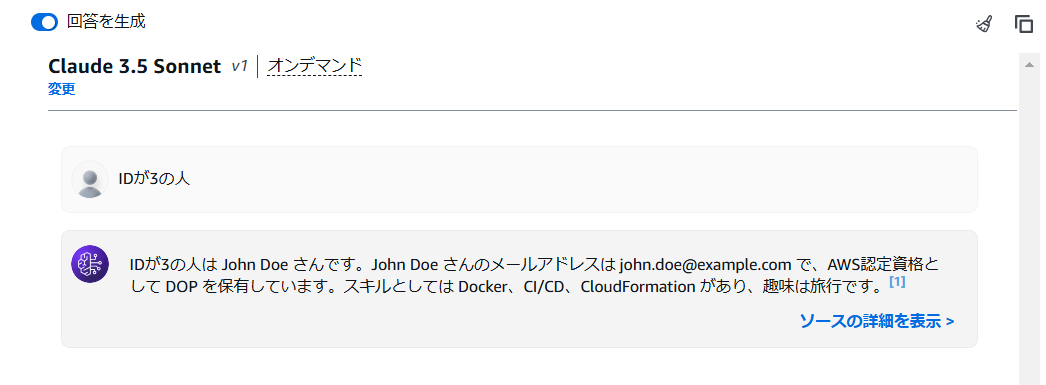
自然言語で聞いてみる
クエリできてるうううううううううううう👏👏👏
自然言語の問い合わせに対して、ちゃんと結果を返してくれています。
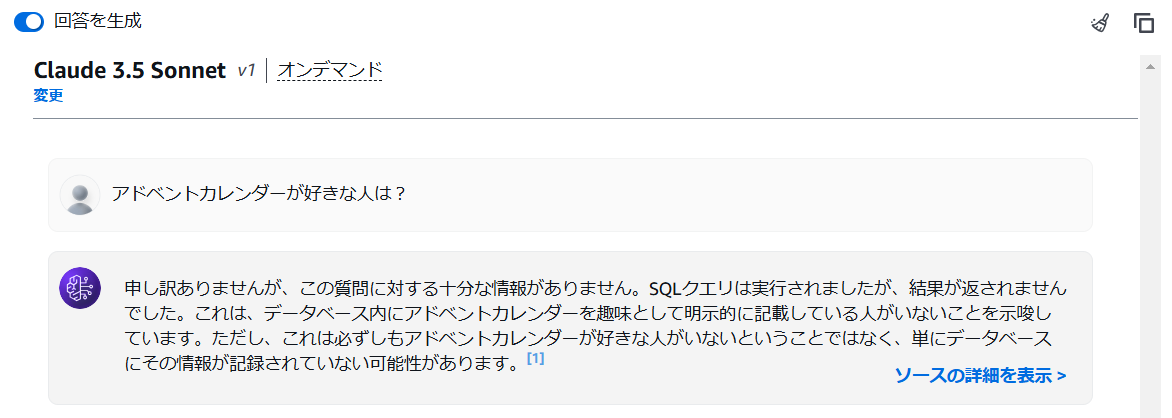
存在しない情報で検索してみた結果。
ちゃんと検索結果は無いと答えてくれています!
(申し訳程度のアドカレ要素…………🎅)
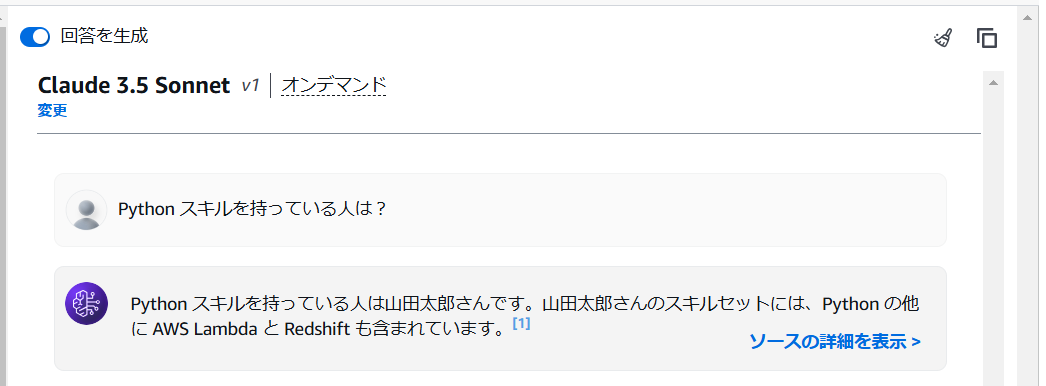
似通った検索ワード(“Pycyon”)を渡した場合でもクエリ検索をしてくれているお陰で、想定通り『見つからなかった』と回答してくれます。
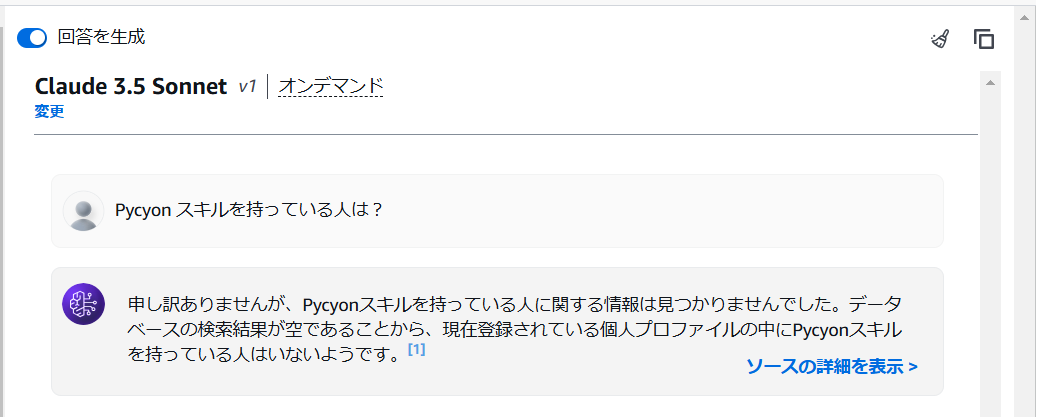
これが従来のベクトルデータベースを使用するケースだと、意味的に近い“Python”を引っ掛けてくることが多いと思うので、完全一致のクエリ結果に基づいた厳密な回答を生成させたいときなんかに、有効な機能なんだろうなぁと感じました。
↓ベクトルデータベース(OpenSearch Service Serverless)を使用している場合の回答生成
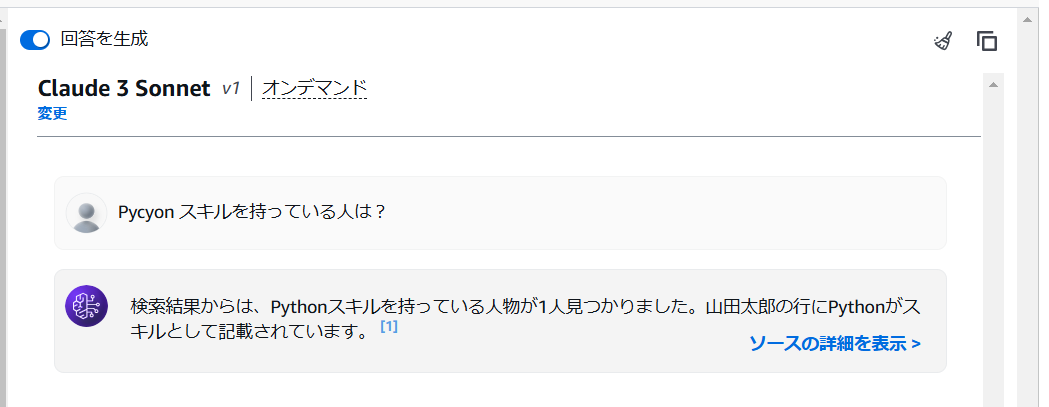
(やっぱClaude3.5 Sonnet賢い)
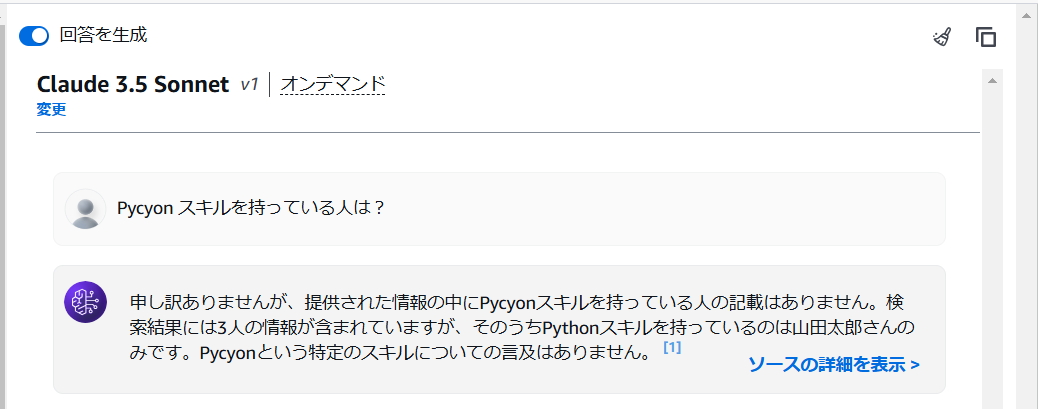
SQLクエリのみ生成させたりすることも可能
[Retrieval and response generation]という設定項目には以下の3つがあり、用途に合わせて生成するものを変えることができます。
- Retrieval only: data sources(データソースからの取得のみを行う)
- Retrieval and response generation: data sources and model:(検索した結果から回答を生成する)
- Generate SQL queries(SQLクエリを生成する)
↓SQLクエリを生成させてみた様子
ええやん…。
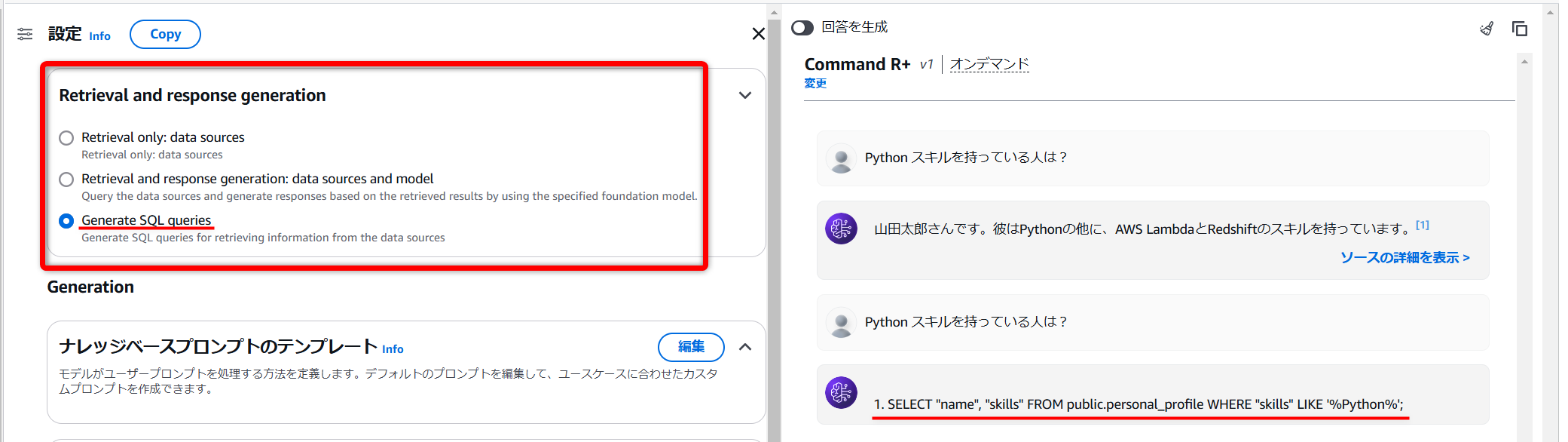
生成したSQLをそのまま「Redshift」で実行しても、ちゃんとクエリできます。👍️
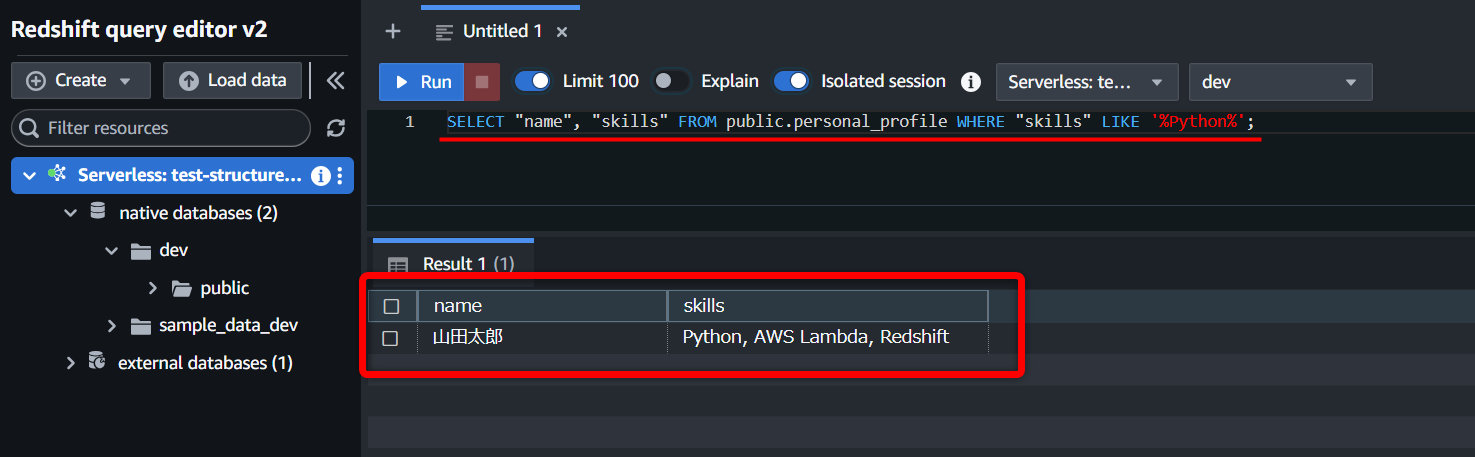
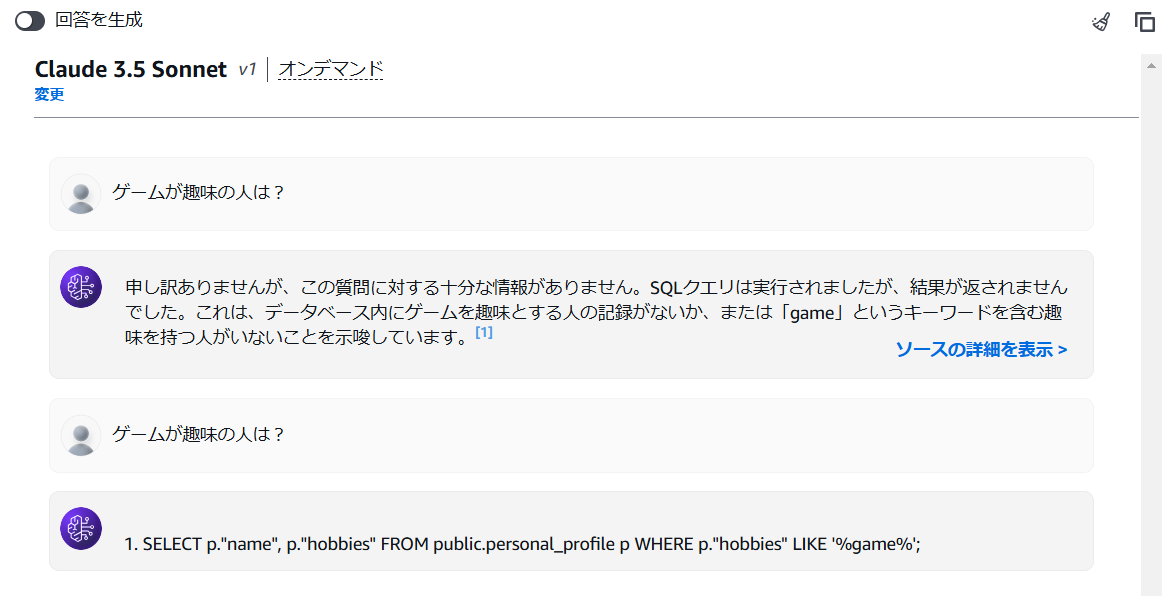
日本語(カタカナ)の検索は苦手
データソースには、趣味を日本語で入れてたんですが、クエリ生成時にカタカナが英語に変換されてしまうようで、趣味が“ゲーム”の人を“game”で検索しちゃったことで、検索失敗してました。
これは要注意…。😑
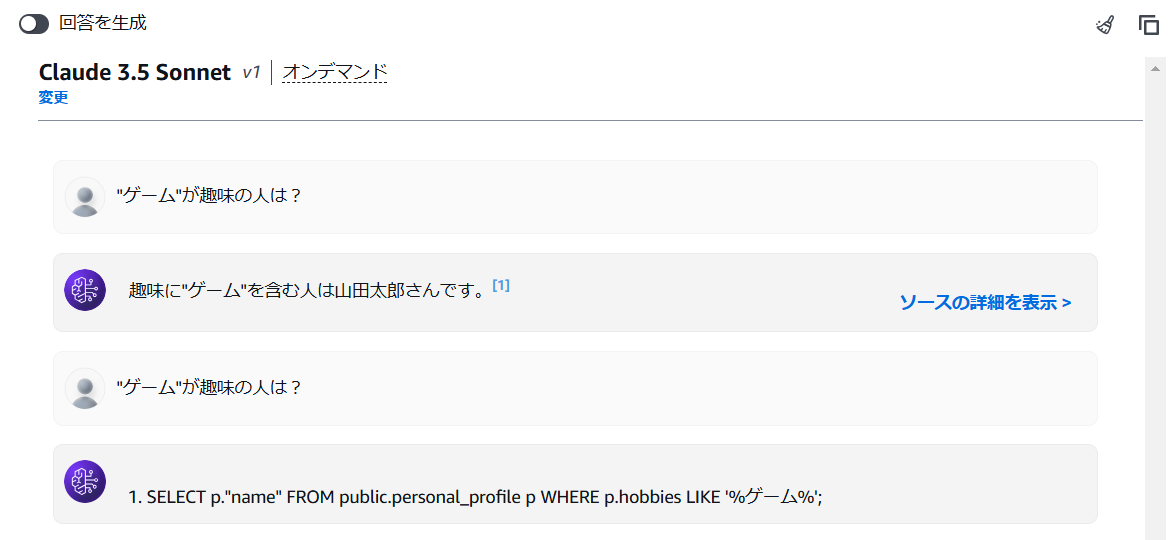
揺らぎはあると思いますが、ダブルクォーテーションで囲んだら、いい感じに検索してくれました。
単純にレスポンスが遅い
当然なんですが、
[自然言語 →SQLクエリ変換 →SQLクエリ実行(Redshift) →結果を踏まえて回答生成]
という工程を踏んでいるため、その分レスポンスに時間がかかってます。(ベクトルデータベースの場合と比べて体感2倍以上)
「Redshift」のスペックを上げたりすることで検索速度は改善したりするとは思いますが、SQLへの変換に結構時間がかかっている雰囲気なので、ここは仕方ないのかなと思いました。😔
感想・まとめ
構造化データへの厳密な検索が可能になったことで、ハルシネーションを抑えられたり、意図しない回答を防ぐことができるかと思います。
RAG活用の幅が更に広がると感じるアップデートでした!!
最後までお付き合いいただきありがとうございました~

好きなこと:音楽、猫、お酒、ゲーム、効率化
経歴:テレビ業界AD → 通信回線販売代理店 → IT関連職業訓練 → 株式会社ディーネット