こんにちは!
ディーネットにて見習いエンジニアをしております下地です(^^)
私の所属するチームでは、メンバーの技術共有のために朝少し時間を取ってミーティングをしているのですが、ある日のミーティングでvmstatについての話題がでました。
サーバのトラブルシューティングや負荷状況を調査する際に時々使ってはいるのですが、自分自身イマイチ各項目が何を意味しているのかを掴めていませんでした。
そこで改めてvmstatコマンドについて調べてみました。
目次
vmstatとは
vmstatとは、LinuxにおいてCPUやメモリなどの使用状況を表示するコマンドです。
システム全体の負荷状況をリアルタイムで観察するのに適しています。
vmstatコマンドの使い方
- 1回だけ実行します
vmstatとだけ打ち込むと1回のみの実行結果を表示します。

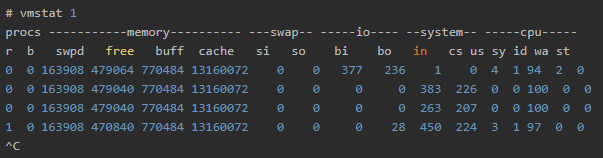
- 1秒毎に連続して実行します
1秒毎に連続して実行します。停止はCtrl + Cで行いました。
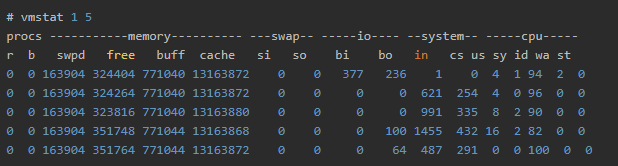
- 1秒毎に連続して5回だけ実行します
こうすると実行間隔と回数を指定できます。
各項目を読み取る
procs
procsは、サーバを使っている人が「なんか重いなー」だったり「さくさく動く!」といったことを端的にあらわしている項目です。
- r ランタイム待ちのプロセス数
実行可能で「実行キュー」に入っているプロセスの数です。
まず、Linuxは時分割という手法で、複数のプロセスを「さも同時に動いているように見せる」方法を取っています。
例えば、プログラムA・B・Cが3個あったとして、プロセッサが1個しかないなら、本当は同時に1個のプログラムしか実行できないハズです。
そこで、1個のプログラムを実行する時間をすごく短くして、A→B→C→A→B→C・・・と順番にかわりばんこに処理することで、あたかも3つのプログラムが同時に処理されているように見えます。
この処理の順番待ち行列(お店に並んでる感じ)を実行キューと呼んでいます。
通常は、この実行キューに入ったプログラムはほとんど即時に処理されてキューから退出するのですが、CPUが忙しかったすると、退出が追いつかず待ち行列ができてしまいます。
したがって、この数値が大きい(通常は0~2程度)場合、利用者は「このサーバ重いな~」と感じている可能性があります。
- b 割り込み不可能なスリープ状態にあるプロセス数
bはdiskのI/O完了待ちになっているプロセス数です。
ディスクI/Oとは、ハードディスクなどの外部記憶装置(ストレージ)に対するデータ読み書き(Input/Output)操作のこと。もしくは、そのような操作にかかる時間や速さです。
つまり、実行中にもかかわらず、ディスクやネットワークなどのI/O待ち状態に入って、実際には実行できてないプロセスの数です。
こちらも通常は0~2程度です。
memory
- swpd 仮想メモリの量(KB)
使用しているスワップ領域の量です。
- free 空きメモリの量(KB)
純粋に未使用状態なメモリの量です。
実はここの値はあまりアテになりません。
空きメモリが増えると、その分をcacheにまわすため、この値がカツカツでも「メモリ不足だ!」とはなりません。
- buff バッファに用いられているメモリの量(KB)
主にカーネルがバッファ領域として使用しているメモリ量です。
バッファとは、簡単に言うと「一時的にデータを溜めておく記憶場所」です。
それほど大きくなることは無いけれども、メモリ全体が逼迫してくると、ここの領域を削ってどうにかがんばるようになります。
- cache キャッシュに用いられているメモリの量(KB)
ディスクアクセス時にキャッシュデータを保存しているメモリの量です。
ここはほうっておくと物凄く大きな値になりますが、特に問題ありません。
なぜなら、この領域は未使用状態なメモリと同じ扱いだからです。
空いている領域を未使用のままにしておくのはもったいないので、過去のディスクアクセスの際に読み書きした(使用頻度の高い)データを保存しておこう・・ということで使用しています。
したがって、メモリが逼迫してくると、この領域のデータは捨ててメモリをプログラムのために割り当てます。
データは捨ててもただのキャッシュなので、またディスクから読み込めばよい、となります。
swap
メモリが不足してくると、メモリ上にある不要データやプログラムをディスクに書き込んで、メモリを空けようとします。
そして、そのデータやプログラムが必要になったら、今度はディスクからメモリの上に戻してプログラムを実行したりデータをいじったりします。
その挙動がここに現れます。
si、so共に常時ゼロという状態が基本です。
ここに常時数値が現れることは、そのサーバにはメモリが足りないか、メモリをバカ食いするプログラムが多すぎるかのどちらかということになります。
- si ディスクからスワップインされているメモリの量 (KB/s)
スワップ(ディスク)⇒メモリの方向で展開したデータ量。スワップ・イン。
- so ディスクにスワップしているメモリの量(KB/s)
メモリ⇒スワップ(ディスク)の方向でスワップ領域に書き込んだデータの量。スワップ・アウト。
io
ブロックデバイスとは、例えばハードディスクやフラッシュドライブなどのことです。
- bi ブロックデバイスから受け取ったブロック (blocks/s)
- bo ブロックデバイスに送られたブロック (blocks/s)
system
- in 一秒あたりの割り込み回数。クロック割り込みも含む
割り込み処理の回数です。
今まで処理していたことを一旦やめて、他の処理を行う、という回数をレポートしています。
- cs 一秒あたりのコンテキストスイッチの回数
コンテキストスイッチの回数です。
「コンテキストスイッチ」とは、プログラムの実行を切り替えることを言います。
プロセッサ(CPU)は前に書いたとおり、すごく短い時間でプログラムを切り替えること(時分割)で並列処理(のように見せる)を行っています。
その切り替え回数を示しています。
なお、このコンテキストスイッチには、一定のロスが生じてしまいます(これをオーバーヘッドと呼んだりします)。
したがって、この数値が大きいと、頻繁にコンテキストスイッチが発生=ロスが大きくなっている、ことを示しています。
cpu
これらの数値はCPUの総時間に対するパーセンテージです。
したがって、全ての値を合計すると100%となります。
- us カーネルコード以外の実行に使用した時間 (ユーザー時間、nice 時間を含む)(%)。
要するに一般のプログラムが動いていた時間の割合です。
- sy カーネルコードの実行に使用した時間 (システム時間)(%)。
カーネルコード(OS自身、またLinuxコール等を呼び出された等)の処理のために費やした時間の割合です。
- id アイドル時間。Linux 2.5.41 以前では、IO 待ち時間を含んでいる。(%)
アイドルタイムです。完全にcpuが空いていた時間の割合です。
- wa IO 待ち時間。Linux 2.5.41 以前では、0 と表示される。(%)
データの入出力処理(ディスクへのアクセス、ネットワークへのアクセス)を試みたものの、結果的にデータを待っていた時間の割合です。
- st 仮想マシンから盗まれた時間。Linux 2.6.11より前では未知。(%)
ここは気にしなくてOKです。
まとめ
このように細かく項目をみていくといろんな情報が汲み取れました。
「サーバが重い」といった基本的なインシデントも、どこにボトルネックがあって重い理由はこうです、と適切に対応できると良いですね。