
目次
はじめに
こんにちは、omkです。
少し前に勤怠表が要りそうになったので自動で作成出来るようにしてみましたが結局不要になったのでこちらで供養します。
Excelって業務で使う割に自動化が大変で関数やVBAを維持しながら更新していくのも面倒なのでPythonにやらせるのが最高ですね。
やってみた
タイムログの取得・出力
タイムログは「Toggl Track」を利用して記録しました。
ログは以下のCSVフォーマットで出力され、記録ごとに行が作成されて出力されます。
Email,Client,Project,Task,Description,Billable,Start date,Start time,End date,End time,Duration,Tagsこのままではどれだけの時間を費やしたか分からないので集計します。
Pythonスクリプト
CSVを読み込んで日毎に集計し、表にまとめる内容になっています。
表の見た目の調整に色々こだわったので本来いらない部分も多いです。
カレンダーをちゃんとその月に合ったかたちで作っているのもこだわりです。
import numpy as np
import pandas as pd
from datetime import timedelta
import sys
import boto3
import calendar
import openpyxl as xl
# CSVファイルのパス指定
csv_path = "Toggl Time Entries.csv"
''' CSV DATA FORMATT
"User", "Email", "Client", "Project", "Task", "Description", "Billable", "Start date", "Start time", "End date", "End time", "Duration", "Tags"
'''
# pandasの設定
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.width', 150)
# calendarの設定
calendar.setfirstweekday(calendar.SUNDAY)
# excelブックの設定
book = xl.Workbook() # workbookの作成
sheet = book["Sheet"]
sheet.title = "勤務表"
outline = xl.styles.Side(style="thin", color="000000")
border = xl.styles.Border(top=outline, bottom=outline, left=outline, right=outline)
time_style = xl.styles.NamedStyle(name="time_style")
time_style.number_format = "HH:MM"
for col in range(1,30):
sheet.column_dimensions[xl.utils.get_column_letter(col)].width = 12
print(xl.utils.get_column_letter(col))
# 年月を取得
def get_target_nengetsu(target_date):
nengetu = target_date.strftime('%Y年%m月')
return nengetu
# 対象月の範囲を取得
def get_target_month_range(target_date):
print(calendar.month(target_date.year, target_date.month))
week_range = calendar.monthrange(target_date.year, target_date.month)[0]
calendar_days = calendar.monthcalendar(target_date.year, target_date.month)
return week_range, calendar_days
# 時間のフォーマットを変更
def format_timedelta(td):
total_seconds = int(td.total_seconds())
hours, remainder = divmod(total_seconds, 3600)
minutes, _ = divmod(remainder, 60)
return f"{hours:02d}:{minutes:02d}"
# 見た目調整用
def format_date(date):
date_str = "" if date == 0 else "日付" if date == 9999999 else str(date)
return date_str
# 表の作成
def create_weekly_worktime(df, week):
# 週の各日に対応する duration を格納するリスト
durations = []
for date in week:
if date == "":
durations.append("")
elif date == "日付":
durations.append("稼働時間")
else:
# その日の duration を探す
match = df[df['Start date'].dt.strftime('%-d') == date]
if len(match) > 0:
# 該当する日付がある場合、その duration を追加
durations.append(format_timedelta(match['Duration'].iloc[0].to_pytimedelta()))
else:
# 該当する日付がない場合、timedelta(0) を追加
durations.append(format_timedelta(timedelta(0)))
return durations
# 表の見た目調整
def set_border():
for row in range(sheet.max_row + 1):
if row == 0 or row == 1:
continue
for col in range(sheet.max_column + 1):
if col == 0 or (row == 2 and col == 1):
continue
sheet.cell(row = row, column = col).border = border
# 表の見た目調整
def set_empty_row():
max_row = sheet.max_row
now_row = 2
while now_row + 3 < max_row:
now_row += 3
sheet.insert_rows(now_row)
max_row = sheet.max_row
# 表の作成
def make_calendar(df):
target_date = df.iloc[0]['Start date']
nengetsu = get_target_nengetsu(target_date)
week_range, calendar_days = get_target_month_range(target_date)
worksheet = book["勤怠表"]
worksheet.cell(row = 1, column = 1, value = nengetsu)
week_title = ["", "日", "月", "火", "水", "木", "金", "土"]
sheet.append(week_title)
for week in calendar_days:
week.insert(0, 9999999)
week = [format_date(date) for date in week]
print(week)
sheet.append(week)
work = create_weekly_worktime(df, week)
sheet.append(work)
set_border()
set_empty_row()
book.save('./book.xlsx')
def daily_sum(df):
df['Duration'] = pd.to_timedelta(df['Duration'])
df['Start date'] = pd.to_datetime(df['Start date'])
df = df.groupby('Start date', as_index=False).sum()
return df[['Start date', 'Duration']]
def main():
# CSVファイルの読み込み
df_aggregate = pd.read_csv(csv_path, header=0)
# 時間を扱いやすいように変更
df_aggregate = df_aggregate.assign(Start_timestamp=df_aggregate['Start date']+"T"+df_aggregate['Start time'])
# 不要なカラムを削除
df_aggregate = df_aggregate[['Start_timestamp', 'Start date', 'Duration']]
# 日付で合計
df_aggregate = daily_sum(df_aggregate)
print(df_aggregate)
make_calendar(df_aggregate)
if __name__ == '__main__':
main()これで完成です。
実行
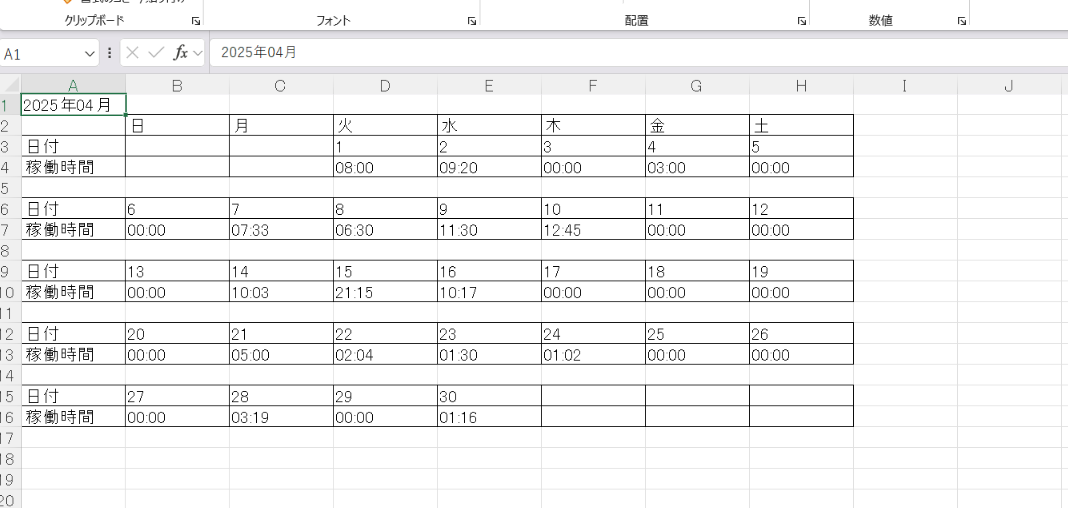
テキトーなCSVを用意して実行してみて作成されたxlsxファイルをダウンロードして確認してみます。
はい、いい感じに表ができました。
おわりに
openpyxlで好きな表を自動で作れるようになりました。
これで急にPTA会長に任命されても安心ですね。
最後までお付き合いいただきありがとうございました。

アーキテクト課のomkです。
IoTが主食です。