
目次
はじめに
こんにちは、omkです。
通常Athenaを利用する際にクエリエディタを利用することが多いと思います。
クエリエディタを利用する場合はAthena SQLでクエリすることになりますが、
今回はPySparkでクエリしたかったのでPySparkで設定してみました。
やってみた
ワークグループ作成
まずはAthenaのコンソールからPySpark用のワークグループを作成します。
分析エンジンをApache SparkにすることでPySparkが使えるようになります。
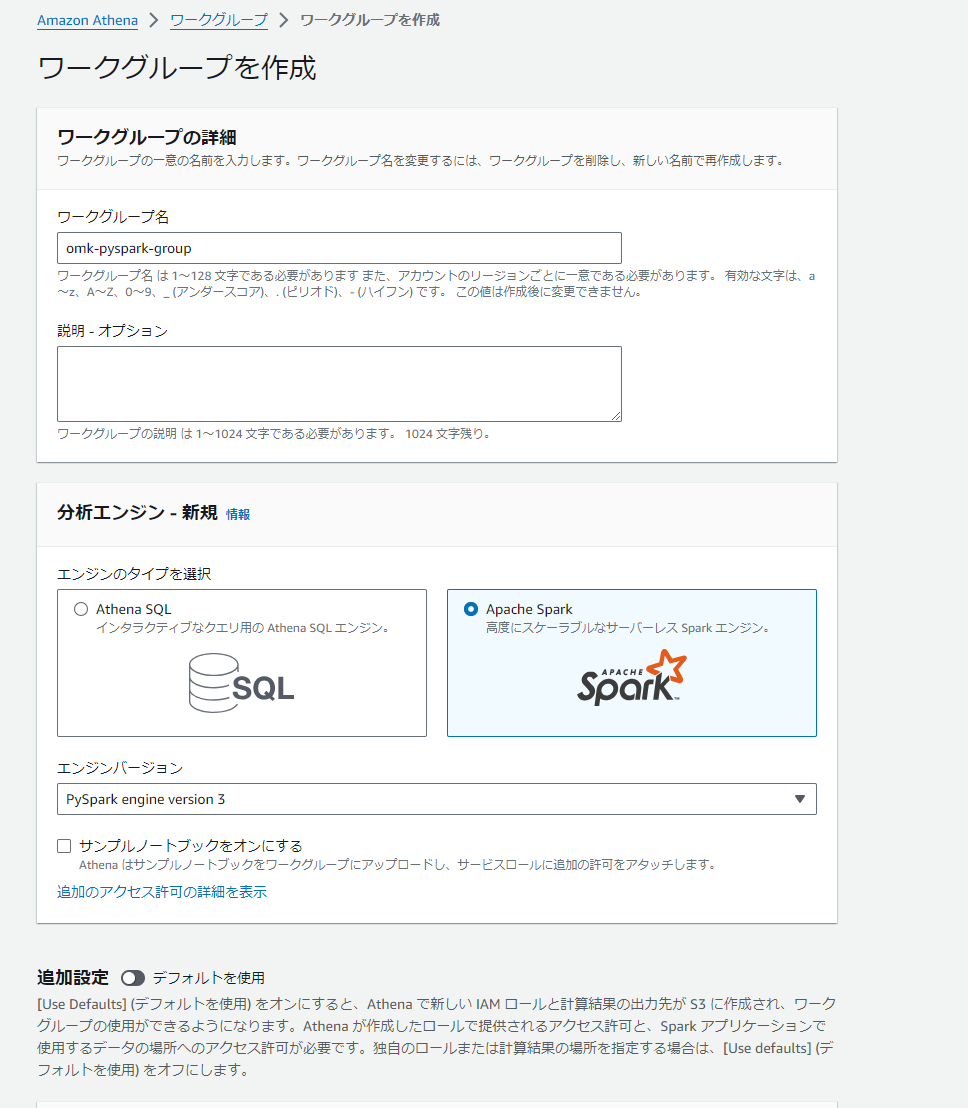
ワークグループが出来ました。
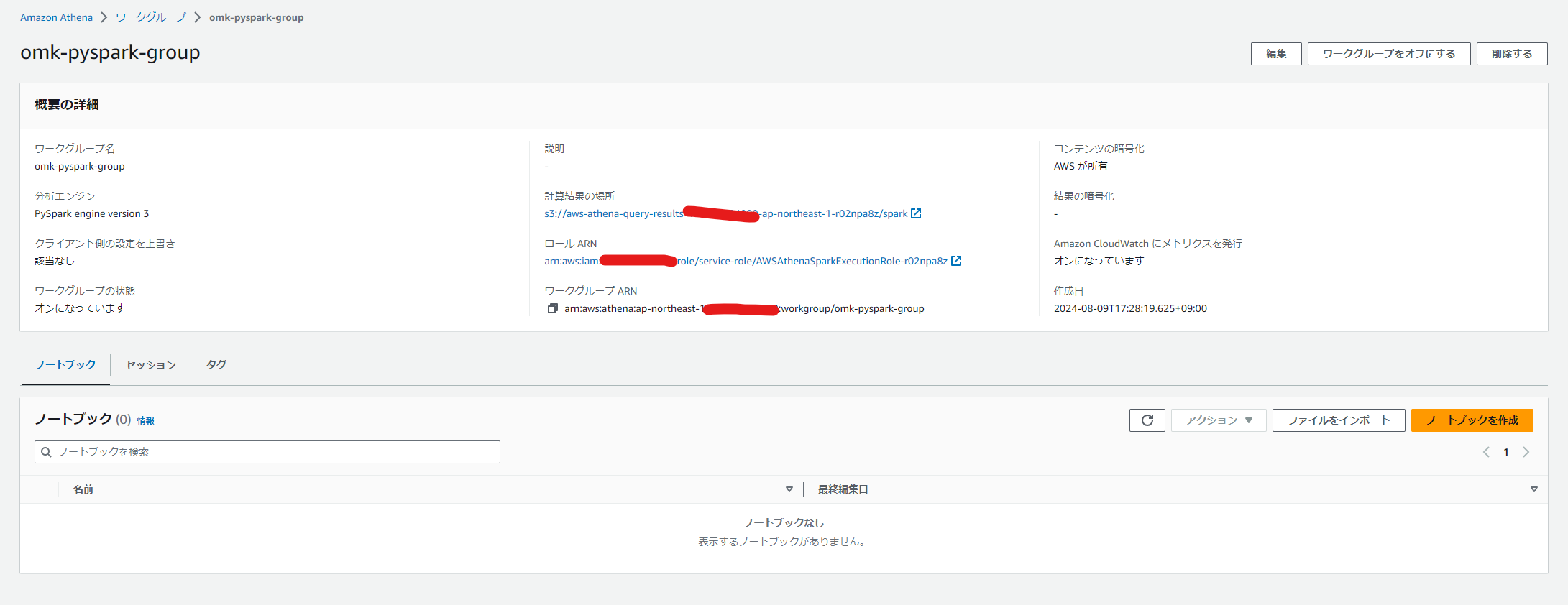
IAMロールが割り当てられたので適切に権限を設定します。
今回はGlue Data CatalogにあるS3バックエンドのテーブルをクエリしたかったのでGlueとS3の権限をつけました。
ノートブック作成
「ノートブックを作成」からノートブックを作成します。
細かい設定の希望がなければ名前だけつけてそのまま作成出来ます。
(※料金には気をつけてね)
あとはクエリしたい内容に沿ってノートブックに記述していきます。
特定のGlue Data Catalogのテーブルを集計してグラフ化するノートブックを作ってみた
ノートブックってどうやってブログに貼ればいいんでしょうね。
ipynbファイルをまるごと貼り付けるのが使い方的に正しそうですがブログとしてどうなんでしょう……。
とりあえずグラフィカルな部分も表現したいので画像で貼っていきます。
Glueのデータベースは次のようにカレントに設定出来ます。
spark.catalog.setCurrentDatabase("{DATABASE_NAME}")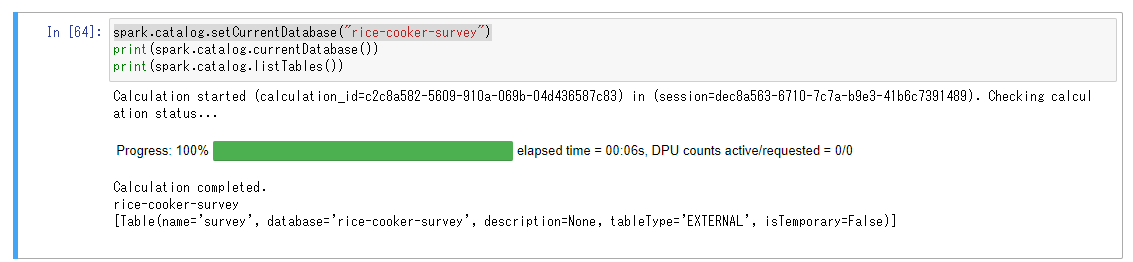
「rice-cooker-survey」データベースのテーブルの一覧に「survey」テーブルがあることがわかりました。
中身を確認します。
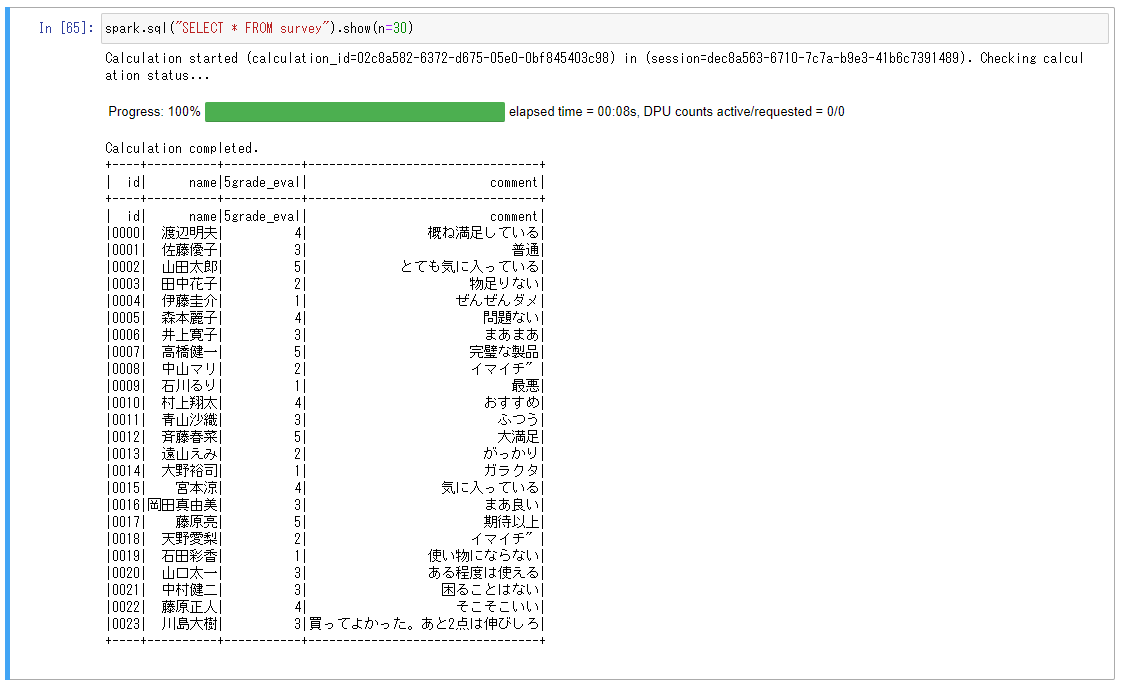
※人名が表示されますが、本データは人名を生成するAPIからランダムに作成したものです。特定の個人に紐づくものではありません。
ある炊飯器をユーザーに5段階で評価してもらった調査結果という体のテーブルです。
マジックコマンドを利用することで次のように記述することも出来ます。

ただし spark.sql("{SQL}").show()
ではグラフを作成していきます。
5段階評価の評価点に基づいて集計しました。
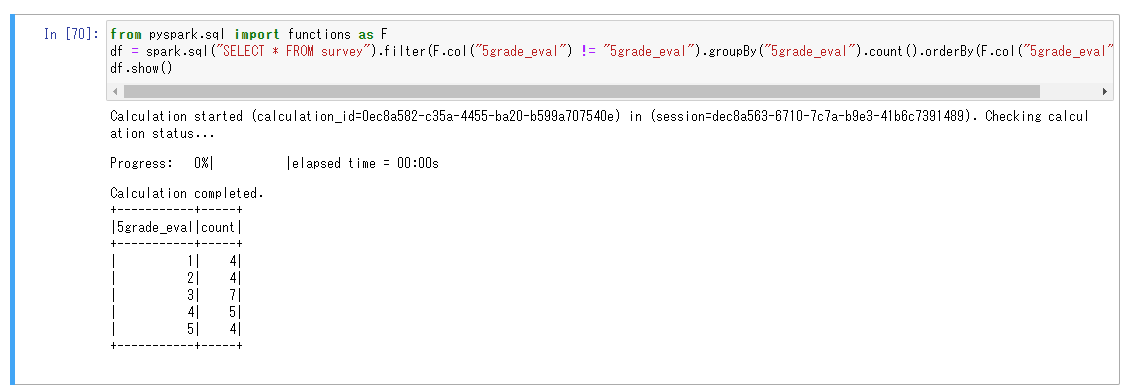
集計結果をmatplotlibで描画します。ここでもマジックコマンドが使用できます。
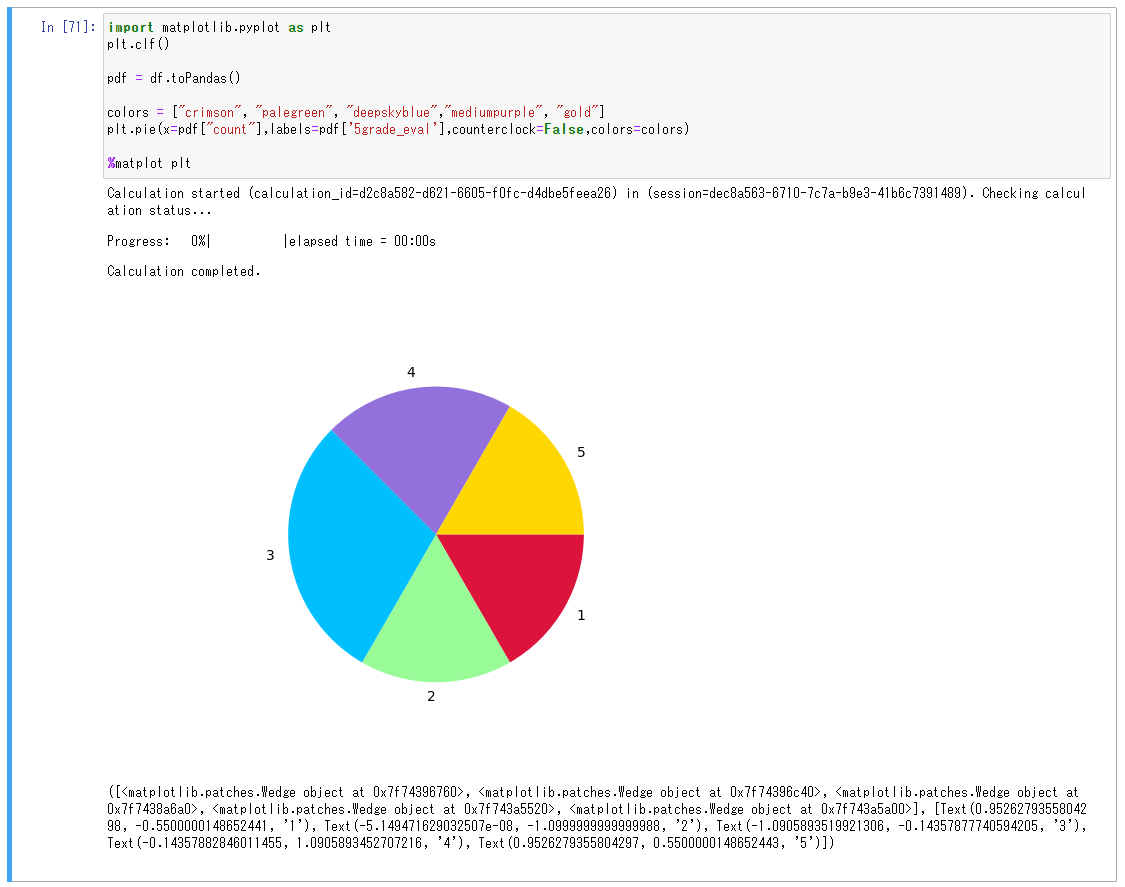
無事グラフが作成できました。
boto3が使えるのでs3にアップロードすることも可能です。
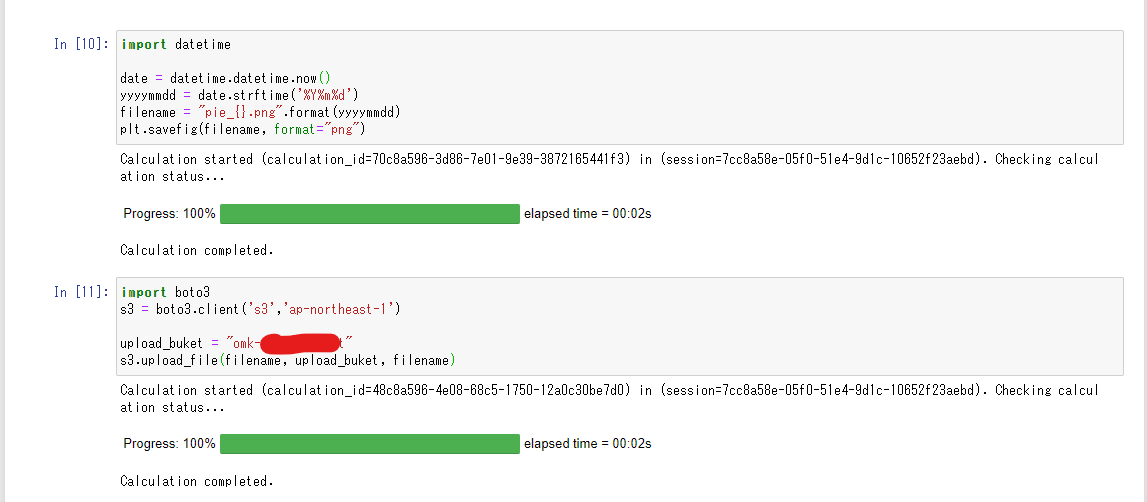
これで欲しい時に簡単にグラフを連携できますね。S3に上げなくてもブラウザ画面から画像を保存することも出来ます。
おわりに
スムーズにPySparkで複雑なクエリが実行できる環境が手に入りました。
あとマジックコマンドが便利でした。
その場でテーブルやグラフを見たいときにちゃちゃっと書けてすぐ使えるのでおすすめです。
考慮事項と制約事項のページに色々記載があるので使用前に見ておくと良いと思います。
以上、最後までお付き合いありがとうございました。

アーキテクト課のomkです。
IoTが主食です。