こんにちは、「負荷テスト中の●●」シリーズでお馴染みの浅見です。
前回「負荷テスト中のアクセスログを解析する」という記事を書きました。
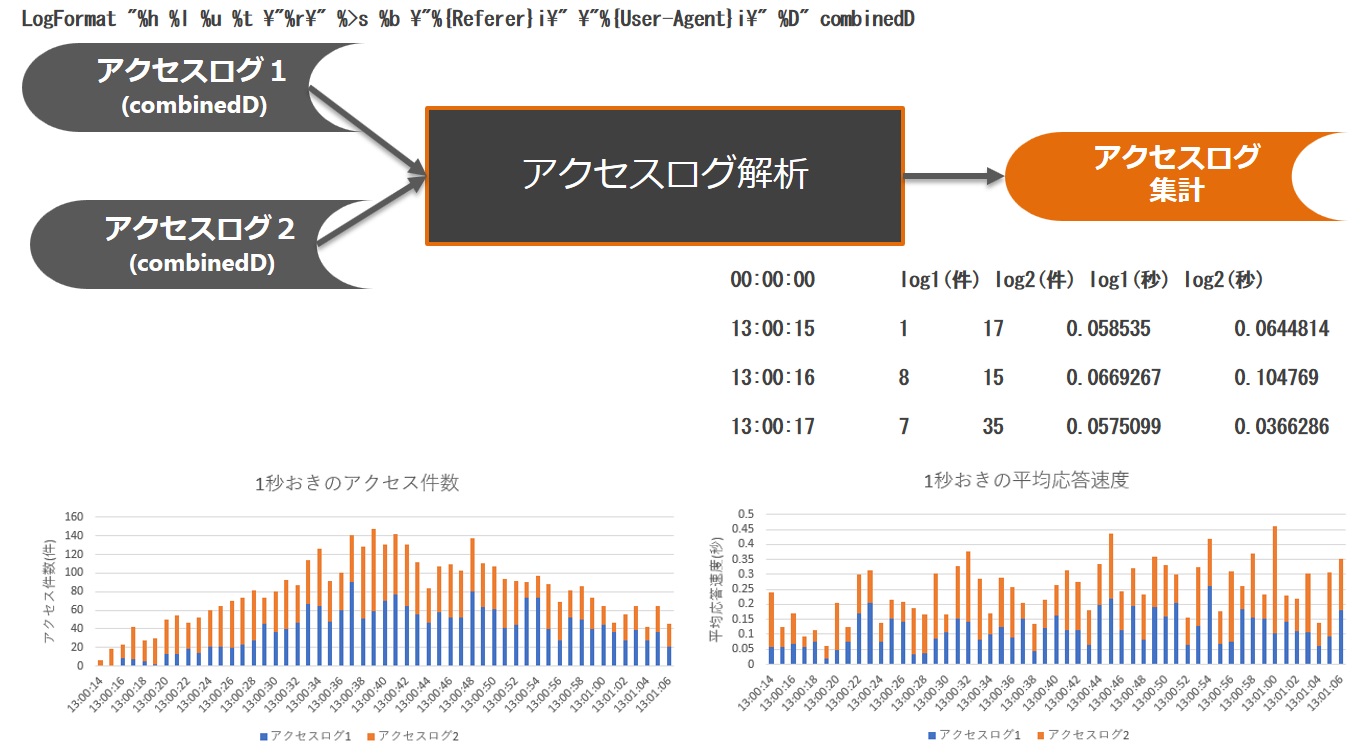
今回は、ちょっと応用して、下の図のように複数サーバのアクセスログを一気に解析する方法をご紹介します。
目次
サンプル構成
今回紹介するシェルは、次のような構成で動作します。
# ls -rlth
合計 2.5M
-rw-r--r-- 1 root root 24 2月 19 17:02 2018 list.txt
drwxr-xr-x 2 root root 4.0K 2月 19 17:05 2018 tmplogs
-rwxr-xr-x 1 root root 3.1K 2月 19 17:21 2018 analyze.sh
-rw-r--r-- 1 root root 1.2M 2月 19 17:39 2018 access_log1
-rw-r--r-- 1 root root 1.3M 2月 19 17:39 2018 access_log2
analyze.sh
ログ解析用シェルです。
引数なしで実行が可能です。
list.txt
ログ解析用シェルの入力ファイルです。
ファイルに、解析対象のアクセスログ名を記載します
# cat list.txt
access_log1
access_log2
tmplogs
テンポラリディレクトリです。
ログ解析中の一時ファイルが保存されます。
access_log1 access_log2
解析するためのアクセスログです。
list.txt内にファイル名を記載する必要があります。
アクセスログを解析するシェル
シェル内容
#!/bin/sh
#-------------------------------------------------------
# アクセスログ解析スクリプト
# アクセスログから時系列に平均応答速度と件数を取得します
# list.txtに解析対象ログファイル名を記載してください
#-------------------------------------------------------
# アクセスログ数分繰り返し
while read access_log
do
# 一時ファイルの変数定義
log_access=tmplogs/${access_log}
tmp_pv_file=${log_access}.pv
tmp_timelist=${log_access}.time
tmp_nmbr_ave_file=${log_access}.nmbr_ave
tmp_time_ave_file=${log_access}.time_ave
tmp_nmbr_ave_join_file=${log_access}.avecnt.join
tmp_time_ave_join_file=${log_access}.avetime.join
#-------------------------------------------------------
# PVっぽいアクセスのみピックアップする
#-------------------------------------------------------
cat $access_log|egrep -v ".svg|.css|.js|.class|.gif|.jpg|.jpeg|.png|.bmp|.ico|.swf|/js/|.cur|healthcheck.txt|.xml">${tmp_pv_file}
#-------------------------------------------------------
# 時系列の応答時間ファイルの作成
#-------------------------------------------------------
# hh:mm:ss の形式で時間を抽出
cat ${tmp_pv_file} |awk '{print $4}'|awk -F: '{print $2 ":" $3 ":" $4}'|sort|uniq|sort -n>${tmp_timelist}
# 平均応答速度と件数を取得
echo > ${tmp_nmbr_ave_file}
echo > ${tmp_time_ave_file}
echo 00:00:00 ${access_log}(秒)>${tmp_time_ave_file}
echo 00:00:00 ${access_log}(件)>${tmp_nmbr_ave_file}
while read time
do
# 平均応答時間
responsetime=grep ${time} ${tmp_pv_file}|awk '{m+=$NF} END{print m/NR/1000000;}'
echo ${time} ${responsetime} >> ${tmp_time_ave_file}
# 平均PV件数
count=grep ${time} ${tmp_pv_file}|awk 'END{print NR;}'
echo ${time} ${count} >> ${tmp_nmbr_ave_file}
done <${tmp_timelist}
#-------------------------------------------------------
# ファイルを結合
#-------------------------------------------------------
if [ "${tmp_nmbr_ave_join}" = "" ] ; then
# 最初のファイルの場合
cat ${tmp_nmbr_ave_file}>${tmp_nmbr_ave_join_file}
cat ${tmp_time_ave_file}>${tmp_time_ave_join_file}
else
# 2番目以降のファイルの場合
join ${tmp_nmbr_ave_join} ${tmp_nmbr_ave_file}>${tmp_nmbr_ave_join_file}
join ${tmp_time_ave_join} ${tmp_time_ave_file}>${tmp_time_ave_join_file}
fi
tmp_nmbr_ave_join=${tmp_nmbr_ave_join_file}
tmp_time_ave_join=${tmp_time_ave_join_file}
done < list.txt
#-------------------------------------------------------
# 区切り文字をスペースからタブへ変更
#-------------------------------------------------------
join ${tmp_nmbr_ave_join} ${tmp_time_ave_join}|sed 's/ /t/g'>result.txt
echo
echo "結果は「result.txt」を確認ください"
echo
echo "先頭10行をピックアップしています↓"
head -n 10 result.txt
ポイントは、joinコマンドです。
joinコマンドは、SQLの内部結合(INNER JOIN)のような振る舞いができるので、アクセスログの時間をキーにして、合致する列を結合させることができます。
注意点としては、どちらか片方にしかない場合は無視されてしまうところです。アクセス状況に応じて、キーになる時間軸を「時分秒」とするか「時分」とするなど調整すると良いでしょう。
実行結果
上記シェルを実行すると、次のような結果が得られます。 ※CentOS6.9で動作確認しています
# ./analyze.sh
結果は「result.txt」を確認ください
先頭10行をピックアップしています↓
00:00:00 access_log1(件) access_log2(件) access_log1(秒) access_log2(秒)
13:00:14 1 5 1.47043 0.184377
13:00:15 1 17 0.058535 0.0644814
13:00:16 8 15 0.0669267 0.104769
13:00:17 7 35 0.0575099 0.0366286
13:00:18 5 23 0.0757728 0.0391552
13:00:19 2 28 0.0178125 0.0444122
13:00:20 13 37 0.0475866 0.157888
13:00:21 13 41 0.0749071 0.0499775
13:00:22 19 28 0.169945 0.130676
結果はタブ区切りのテキストファイルで出力されます。
次のような順番で結果が出力されます。
- 時分秒
- アクセスログ1の件数
- アクセスログ2の件数
- アクセスログ1の平均応答速度
- アクセスログ2の平均応答速度
クライアントPCへダウンロードし、Excel等で加工することで欲しい情報を入手できると思います。