
目次
はじめに
こんにちは、機械学習入門中のomkです。
趣味でボードゲームを嗜んでいるのですが思わぬ見落としが多発するので画像認識でソリューションを考えてみます(人と対戦するときに使うのはズルですが)。
まずは画像から対象を認識する必要があると思うのでRekognitionで認識してもらうとして、そのためのラベル付けをGround Truthでやってみます。
やってみた
題材
今回利用するのはQuarto!の駒です。
Quarto!はそれぞれの駒に{白い:黒い}、{丸い:四角い}、{長い:短い}、{平ら:凹んでいる}というそれぞれどちらかの要素が割り当てられており、盤面に2人で駒を交互に置いていく中で縦横斜めのいずれかにいずれかの要素の駒を揃えると勝ち、という対戦ゲームです。
シンプルながらに戦略が難しく駒の見落としも非常に多いです。
最終的にはすべての駒の並びを取れるところまで進めたいですが、まずは3つの駒を用いてそれぞれを認識できるところまで行おうと思います。
利用する駒は
- 黒くて丸くて長くて平らな駒
- 白くて四角くて短くて凹んだ駒
- 白くて四角くて長くて凹んだ駒
の3つです。



最初は上2つで行っていたのですが「白くて四角くて短くて凹んだ駒」と「白くて四角くて長くて凹んだ駒」の誤認が多かったため対象を追加しています。
Ground Truthでラベル付け
Rekognitionで駒を学習させるためにまずはラベルを設定していきます。
SageMaker Ground Truthを利用することで画像中の駒の範囲を直感的に指定することができます。
ラベルは駒の各要素をもとにそれぞれ
- black-high-flat-cylinder
- white-low-dented-box
- white-high-dented-box
と名付けました。
画像にラベルを設定していきます。

各駒で15枚ずつくらいと複数の駒があるパターンでラベルを設定していくのでまぁまぁしんどい作業です。
これでラベルの設定が完了しました。
一覧でラベルが合っているかを確認します。
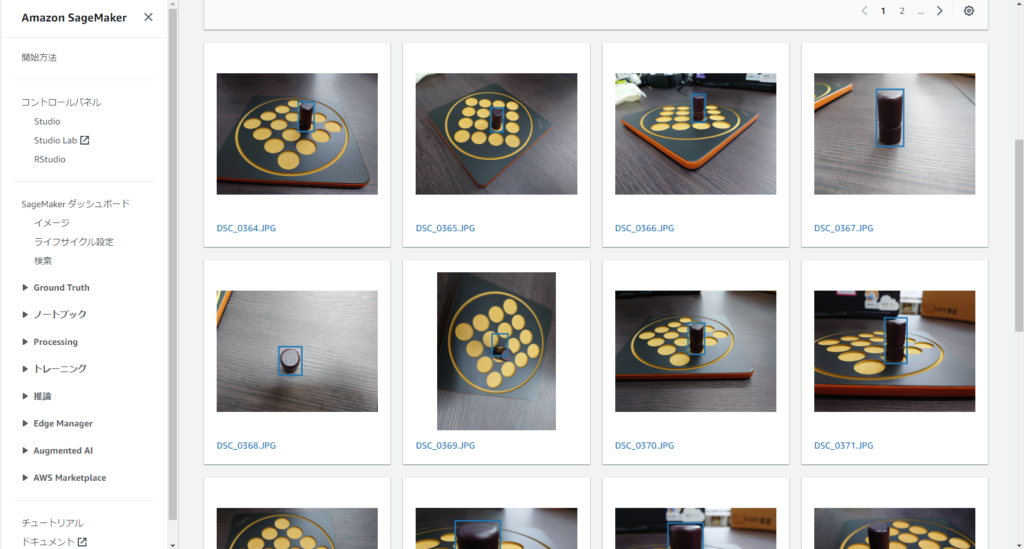
(一箇所間違っていたので手動でマニフェストファイルを変更したのですが正しくはどうするんでしょうか……)
ラベルの設定が完了したので次はRekognitionで学習させます。
Rekognitionで学習
Amazon Rekognition Custom Labelsを選択してプロジェクトを作ります。
Create datasetのTraining dataset detailsでデータセットの設定方法を「Import images labeled by SageMaker Ground Truth」に設定することで先程作成したラベルを利用できます。
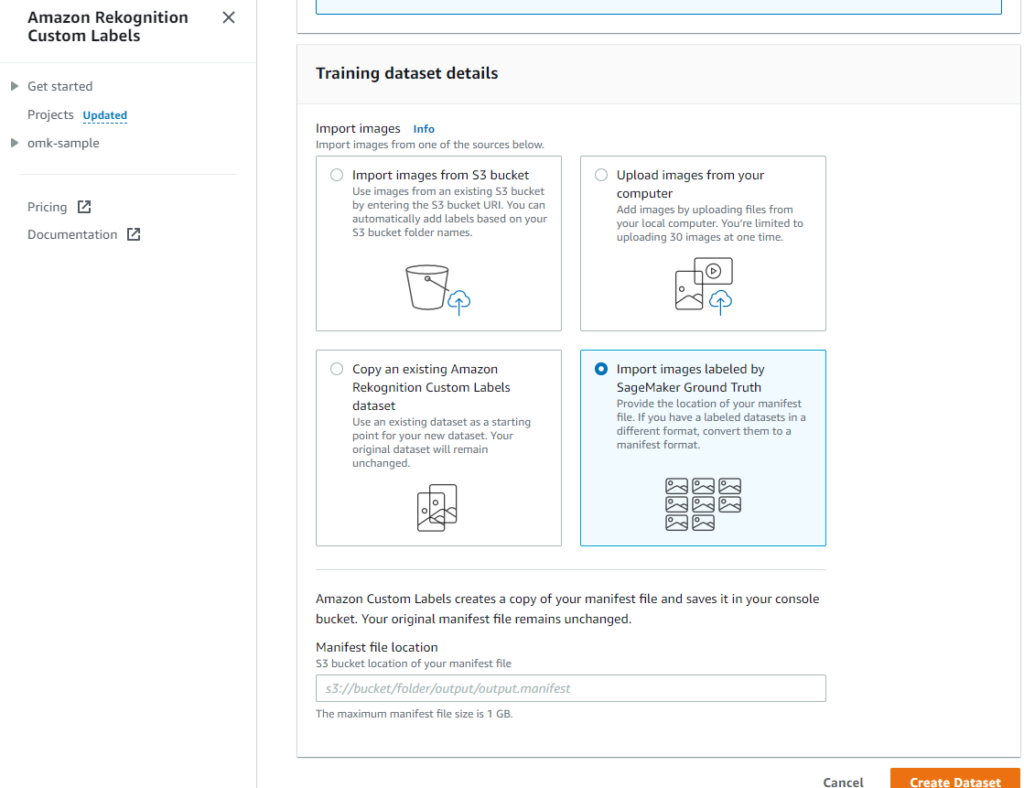
対象のS3のパスはGround Truthの「{出力データセットの場所}/manifests/output/output.manifest」になります。
これでデータセットの設定ができたのでトレーニングを始めます。
しばらく時間がかかるのでお茶を淹れます。
モデルが完成したら精度を確認します。
「Start with a single dataset」でデータセットを登録した場合、自動で訓練データとテストデータに分けてくれていますので、完成時点ですでにモデルの精度が測定されています。
精度に問題なければそのまま使います。
認識結果を画像に出力
「Use model」からモデルをスタートします。
起動が完了したらAPIに画像を投げます。
今回は山田さんのスクリプトを借りつつPythonから投げます。
画像を投げて得られた認識結果からラベル名ごとに最も「Confidence」の高かったものを色付きの枠で囲います。
import boto3
import io
from io import BytesIO
from matplotlib import pyplot as plt
from PIL import Image, ImageDraw, ExifTags, ImageColor, ImageFont
def write_image(bucket,photo,items):
s3 = boto3.resource("s3")
bucket = s3.Bucket(bucket)
# S3からオブジェクトを取得
obj = bucket.Object(photo)
response = obj.get()
body = response["Body"].read()
img = Image.open(BytesIO(body))
img_width = img.size[0]
img_height = img.size[1]
for item in items:
# rekognitionで比較した結果、関連する部分が見つかったか判定
# 検索対象を探す画像で見つかった位置を扱いやすいように変数に定義する
size_width = item['Geometry']['BoundingBox']['Width']
size_height = item['Geometry']['BoundingBox']['Height']
size_left = item['Geometry']['BoundingBox']['Left']
size_top = item['Geometry']['BoundingBox']['Top']
# 見つかった対象の類似度を表示する
print("関連する部分が見つかりました\n詳しくは、生成された画像を確認してください")
# 検索対象を探す画像のどの部分に見つかったか画像を修正
color = {
"black-high-flat-cylinder": "red",
"white-low-dented-box": "blue",
"white-high-dented-box": "green"
}
rect = plt.Rectangle(
(size_left * img_width, size_top * img_height),
size_width * img_width, size_height * img_height,
fill=False,
edgecolor=color[item['Name']])
plt.gca().add_patch(rect)
# 検索対象が見つかった画像をファイルに出力する
plt.imshow(img)
plt.savefig("./image.png", dpi=600)
def show_custom_labels(model,bucket,photo, min_confidence):
client=boto3.client('rekognition')
#Call DetectCustomLabels
response = client.detect_custom_labels(Image={'S3Object': {'Bucket': bucket, 'Name': photo}},
MinConfidence=min_confidence,
ProjectVersionArn=model)
# For object detection use case, uncomment below code to display image.
return response['CustomLabels']
def main():
bucket={ここにバケット名}
photo={ここに画像のキー}
model={モデルのARN}
min_confidence=50
#labels
label_count=show_custom_labels(model,bucket,photo, min_confidence)
#print("Custom labels detected: " + str(label_count))
#最もスコアの高いラベルを表示
bhfc = list(filter(lambda item : item['Name'] == 'black-high-flat-cylinder', label_count))
bhfc_sorted = sorted(bhfc, key=lambda x: x['Confidence'], reverse=True)
print(bhfc_sorted[0])
wldb = list(filter(lambda item : item['Name'] == 'white-low-dented-box', label_count))
wldb_sorted = sorted(wldb, key=lambda x: x['Confidence'], reverse=True)
print(wldb_sorted[0])
whdb = list(filter(lambda item : item['Name'] == 'white-high-dented-box', label_count))
whdb_sorted = sorted(whdb, key=lambda x: x['Confidence'], reverse=True)
print(whdb_sorted[0])
items = [bhfc_sorted[0], wldb_sorted[0],whdb_sorted[0]]
write_image(bucket,photo,label_count)
if __name__ == "__main__":
main()自分で書いたところはバーって書いたのでキレイなコードではないです。
S3に画像を上げて確認してみます。
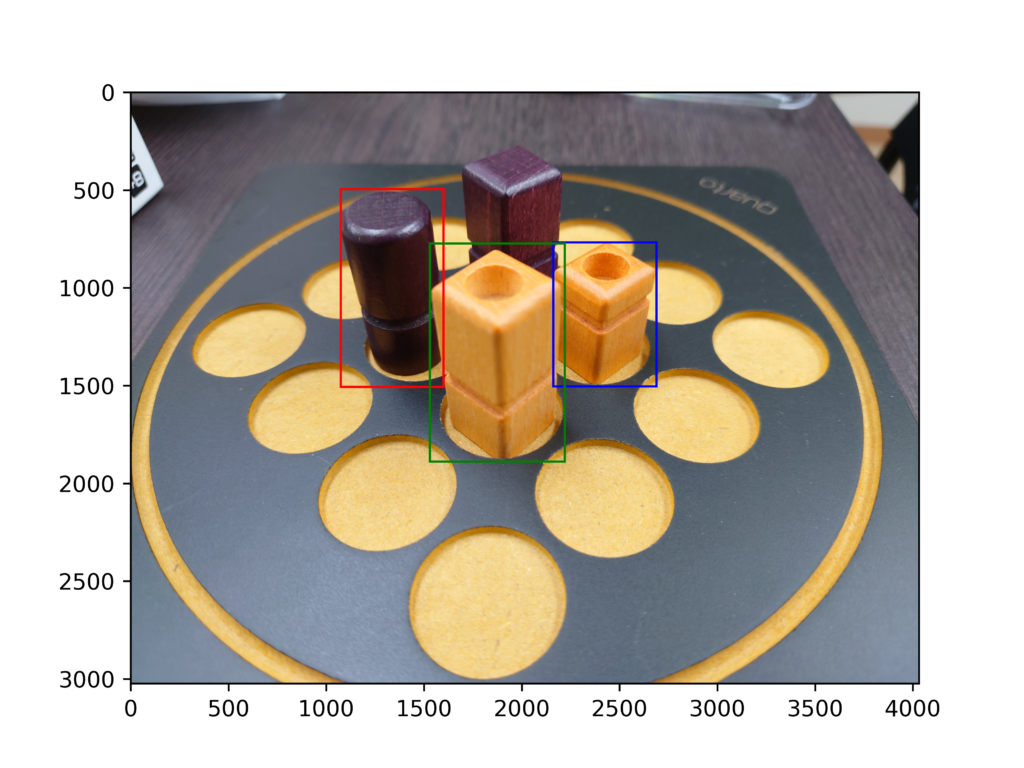
これは成功パターンです。認識したラベルごとに色を変えていますが、正しい色で囲われていることがわかります。

こっちは失敗パターンです。
奥の黒くて四角くて長くて平らなやつが何故か認識されています。
今回は十分区別できるほどの精度は出ませんでしたがある程度判別できるようになりました。
反省
今回Quarto!を題材にしましたが、
同じような特徴を持つ駒同士が非常に似ているため(今回の例では白い駒2つの差は駒の高さと溝の位置程度しかない)駒同士の区別が難しかったと思います。
加えて、てっぺんに凹みがあるかを判別する必要があるので写真を取る際に少なからず角度をつけて取る必要があったのですが、そうすると画像からでは長い:短いの判断がつかないのが難点だったと思います。
人間は立体的に見れるからいいですよね。
あとは訓練データが駒にピントがあっているものが多かったからか、ピンボケた写真や別の駒に焦点があたっている画像では精度が低かったように思います。
適切な画像を用意する必要があるというのがわかりますがなかなかやってみないとわからないものですね。
おわりに
Ground Truthでラベル付けしたデータをRekognitionで認識させてみました。
認識するまでの手間がラベル付の手作業部分くらいだったので非常に簡単でした。
今後ももっと精度を上げるコツを学びつつ簡単に画像認識を導入していきたいですね。
以上、最後までお付き合いありがとうございました。

アーキテクト課のomkです。
IoTが主食です。