
目次
はじめに
こんにちは、omkです。
今回はGlueでMarketplaceのコネクターを使ってみました。
Marketplace自体あまり使ったことがなくて、どうやって使うのか混乱する箇所もありましたので手順を紹介していこうと思います。
最終的には何のコネクターを利用するか次第だとは思いますが、今回はCloudWach Logsのログを取得することにし、以下のコネクターを利用します。
Cloudwatch Logs connector for AWS Glue
こちらはAWS公式のコネクターでサブスクライブにも特に料金は発生しません。
やってみた
コネクターのサブスクライブ
Glueコンソールで「Connectors」を選択します。
何も設定していない場合は以下の画像のようになっています。
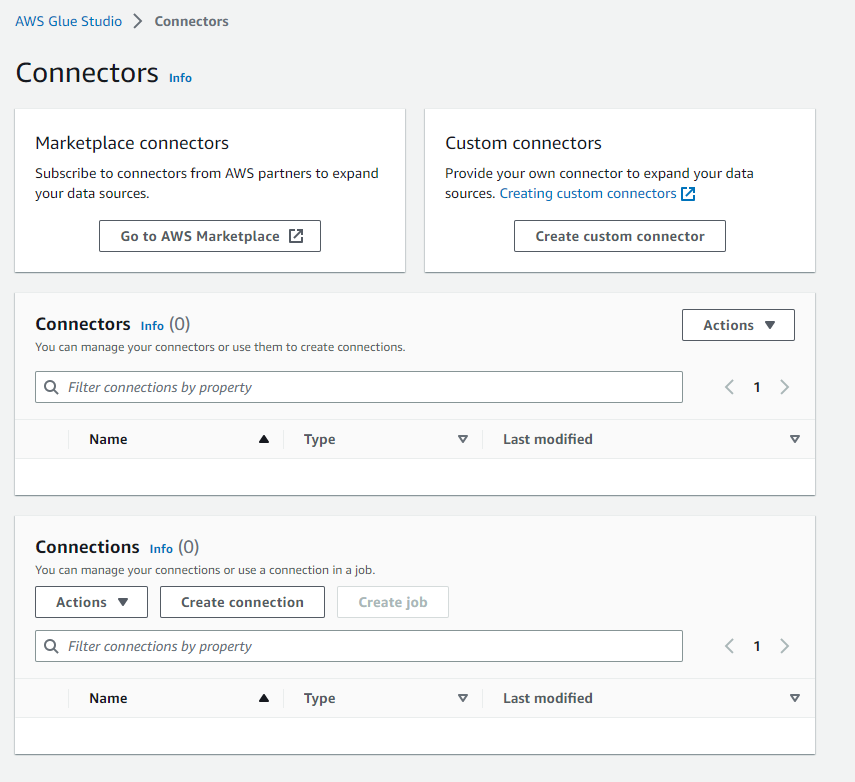
ここから「Go to AWS Marketplace」を選択して、対象のコネクターを選択します。
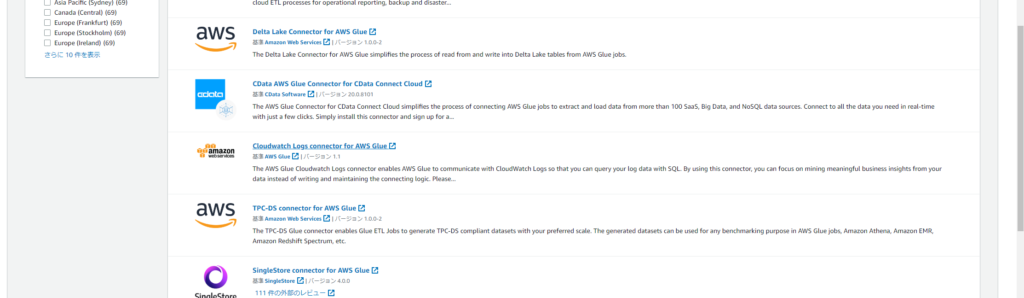
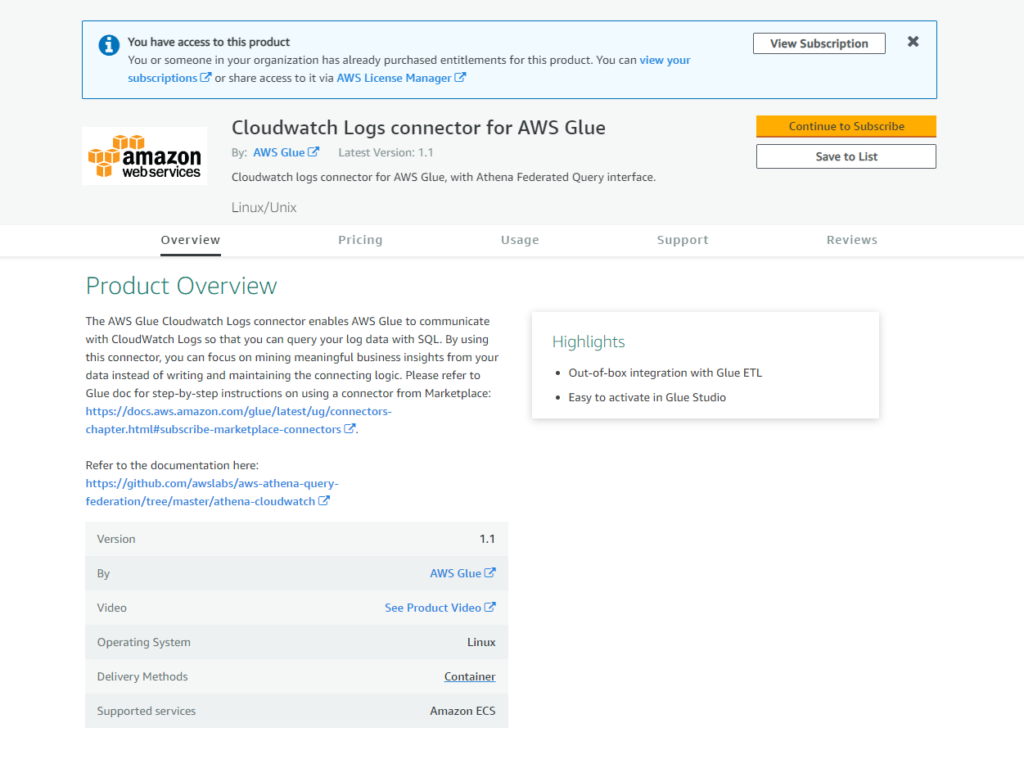
対象のコネクターをサブスクライブします。
コネクションの作成
サブスクライブ出来たら「Continue to Configuration」を選択します。
「Activate in AWS Glue Studio」とバージョンを設定を入力したら「Continue to Launch」を選択します。
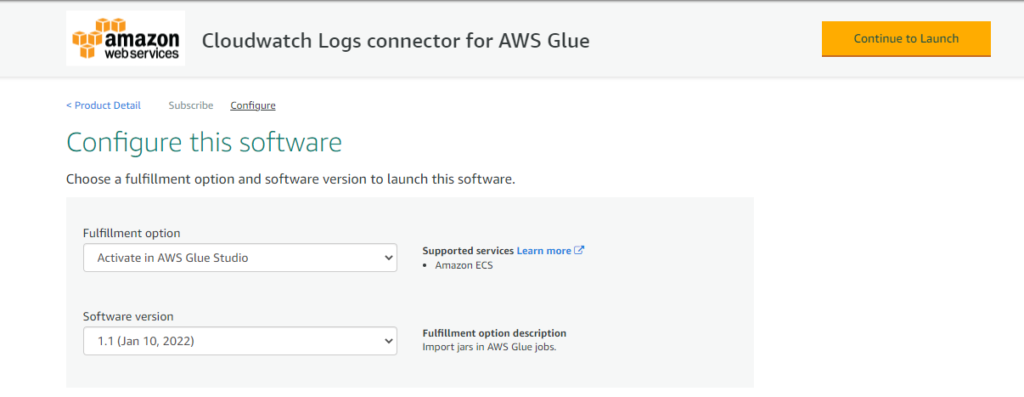
「Usage Instruction」を選択して「Activate the Glue connector from AWS Glue Studio」でコンソールに遷移します。
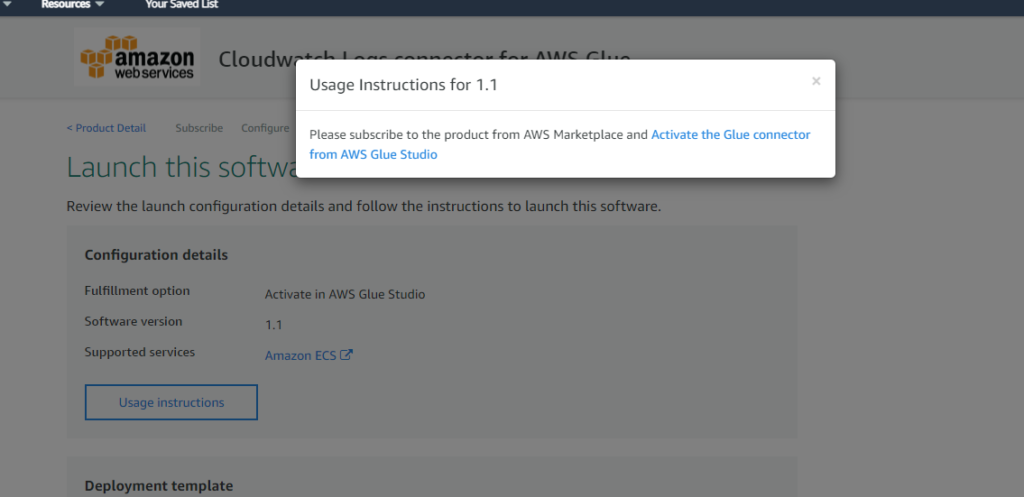
コネクションを作成します。ここではコネクション名の設定だけすることとします。
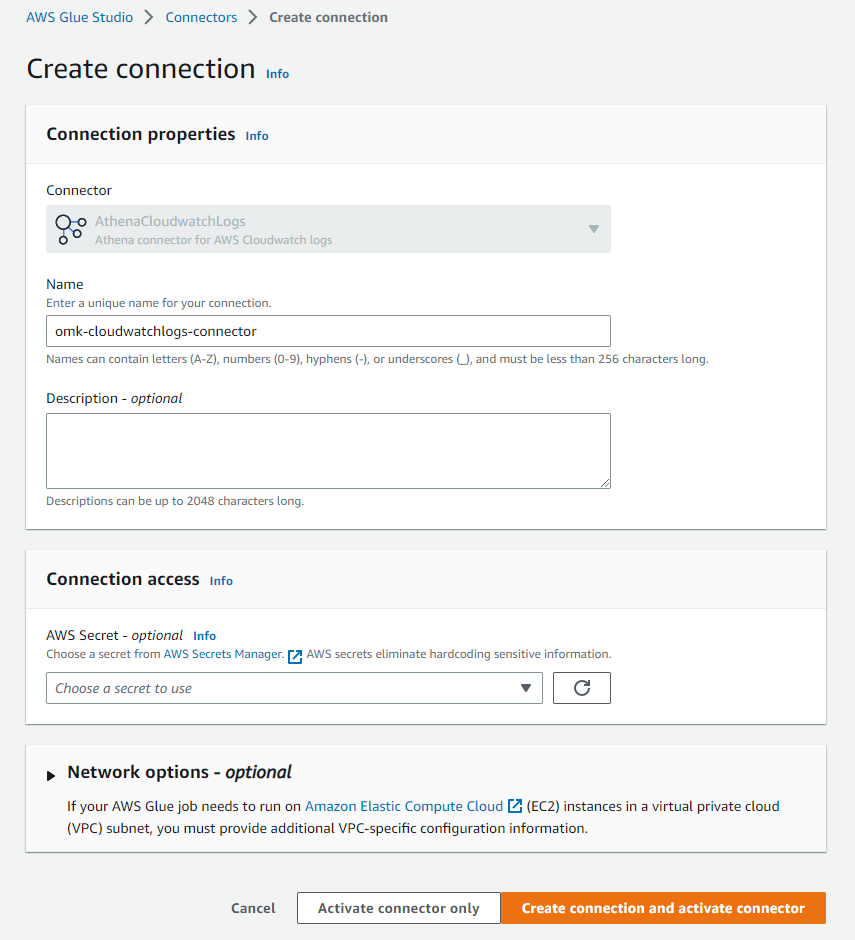
「Create connection and activate connector」を選択して、コネクションを作成します。
Connectorsにサブスクライブしたコネクターが存在し、Connectionsに作成したコネクションが存在することを確認できます。
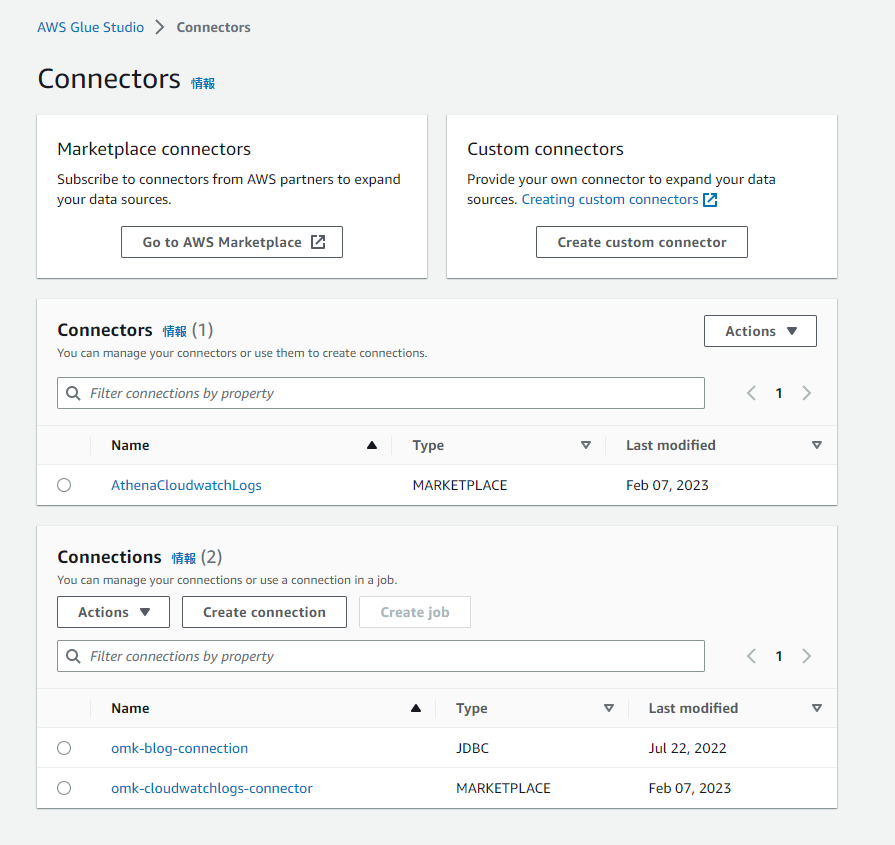
これでコネクションの設定が完了です。
ジョブでの使用
では、Glueジョブで作成したコネクターを使用してCloudWatch Logsからログを取得していきます。
コネクションを作成したため、Glue StudioのJobsの「Create job」の「Source」欄に対象のコネクターを設定することが可能になっています。
また、作成したコネクションの詳細画面から「Create job」を選択することで本コネクションをSourceにしてジョブを作成することが可能です。
他にも作成中のジョブのSourceを変更することも可能です。
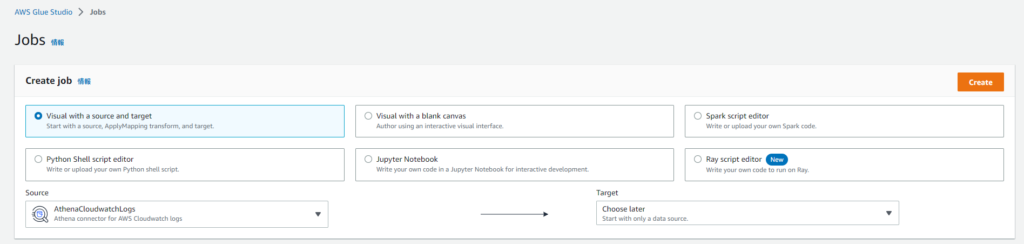
「Cloudwatch Logs connector for AWS Glue」をGlue Studioで使用する際には「Data source properties - Connector」の欄から「Schema name」に対象のロググループを「Table name」にはログストリームを指定する必要があります。
Sparkのスクリプトは以下のようになります。
AthenaCloudwatchLogs_node1 = glueContext.create_dynamic_frame.from_options(
connection_type="marketplace.athena",
connection_options={
"schemaName": "/aws-glue/crawlers",
"tableName": "omk-part-crawler",
"dbTable": "omk-part-crawler",
"connectionName": "omk-cloudwatchlogs-connector",
},
transformation_ctx="AthenaCloudwatchLogs_node1",
)あとはデータを出力するようにして必要なIAM権限を割り当てたら利用できます。
おまけ -サブスクリプションの停止
「AWS Marketplace」からサブスクリプションの一覧が取得出来ます。
この中でGlueのコネクターのサブスクリプションも同様に管理されていますので対象サブスクリプションの契約欄のアクションから「サブスクリプションのキャンセル」を選択することでサブスクリプションを停止出来ます。
また必要になったときに再度サブスクライブすることも可能です。
おわりに
コネクターで色々なところからデータが連携できるようになるので便利ですね。
最後までお付き合いありがとうございました。

アーキテクト課のomkです。
IoTが主食です。